
Research
Palo Alto, California
Zyphra is excited to release Zyda2, a 5-trillion token dataset composed of filtered and cross-deduplicated DCLM, FineWeb-Edu, Zyda-1, and Dolma v1.7's Common Crawl portion. Leveraging NVIDIA NeMo Curator, we've dramatically accelerated data processing from 3 weeks to 2 days while reducing costs. Zyda-2 powers our Zamba2 series, pushing the boundaries of small-LLM performance and reinforcing Zyphra's position at the forefront of efficient, high-performance language model development.
Zyphra & Nvidia
Introduction
At Zyphra, one of our key priorities is producing the highest-quality and most efficient models for a given parameter budget. This has driven our innovations in model architecture and also necessitates a focus on constructing strong pretraining and annealing datasets.
Our general approach is to first collect strong open-source datasets (like Dolma, FineWeb, and DCLM), then remove duplicates and aggressively filter them to obtain the highest-quality subset that meets our training budget. Our first dataset was Zyda-1 used to train Zamba-7B, which was a dataset composed of 1.3T tokens outperforming all open major language modeling datasets at the time, such as Dolma-1.6, FineWeb, and RefinedWeb. For this dataset, we constructed our own data processing pipeline which is open-sourced in the Zyda-processing library which entirely relies on CPU compute for both deduplication and filtering steps.
For our next round of datasets we aimed to significantly increase the scale of the dataset beyond Zyda-1 as well as the quality, to enable us to reach the frontier of small-LLM performance, which we have reached with our Zamba2 series of models. Because of this, we realized that our previous hand-made CPU-based data processing pipeline would not be sufficient and turned to NVIDIA NeMo Curator to speed up development time, lower costs and decrease runtime of our dataset processing significantly.
Processing Large-Scale, High-Quality Data with NeMo Curator
NeMo Curator is a GPU-accelerated data curation library that improves generative AI model performance by processing large-scale, high-quality datasets for pretraining and customization.
By providing ready-made scripts for filtering and deduplication, as well as its own suite of topic models, NeMo Curator enables rapid prototyping and development of dataset processing workflows.
Additionally, due to its deep integration with Dask and optimization for GPU processing, NeMo Curator enables much more straightforward parallelization of jobs and the ability to perform certain data processing stages on GPUs leading to substantial speedup – from 3 weeks on CPU to 2 days on GPU.
Zyda-2 At a Glance
Zyda-2 is an approximately 5-trillion token permissively licensed dataset which is available on HuggingFace. Models trained on this dataset perform extremely strongly on downstream standardized evaluation tasks, beating current state-of-the-art datasets such as DCLM and FineWeb-Edu. Our leading Zamba2 series of models was trained on an early version of this dataset.
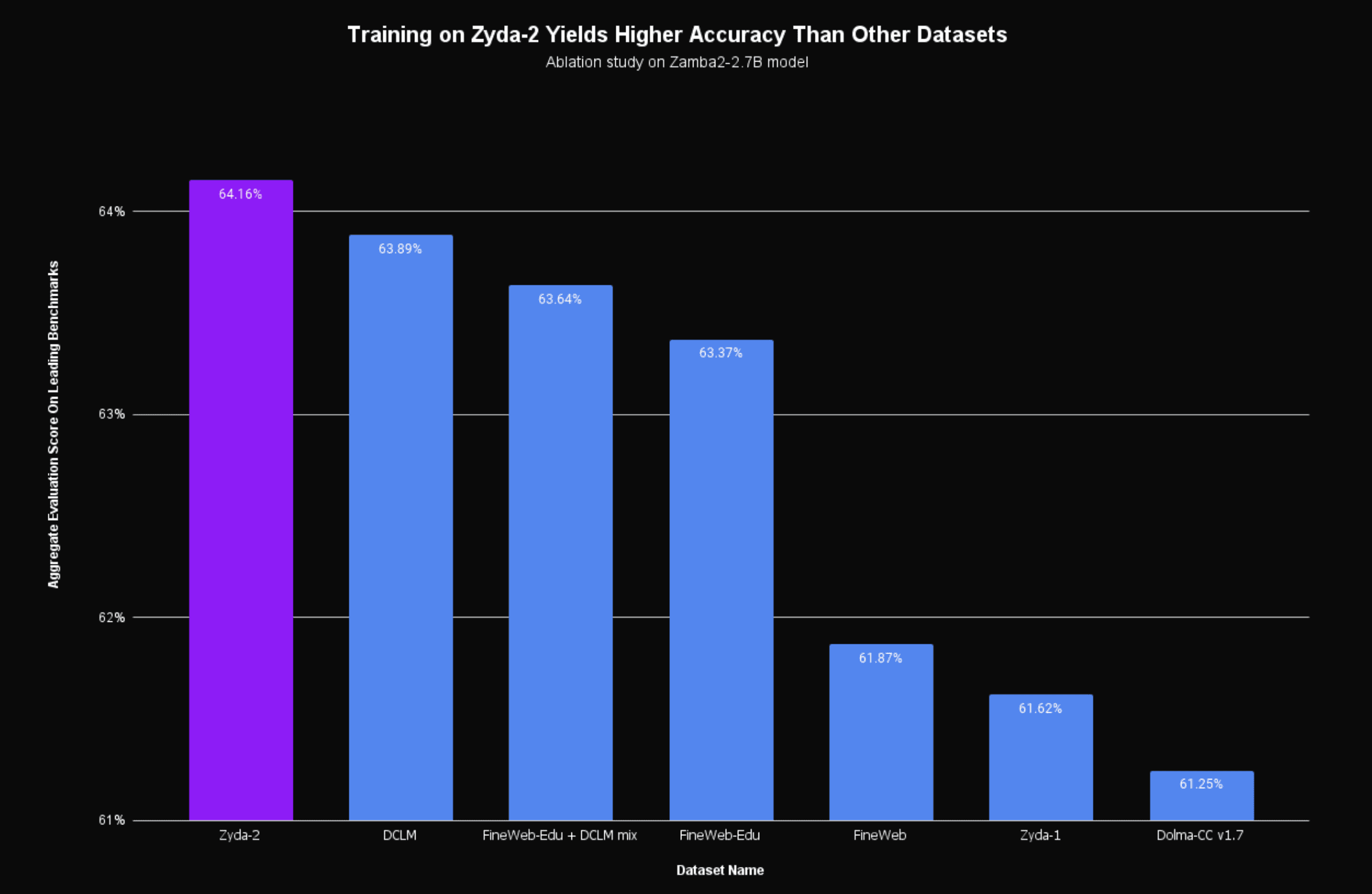
Figure 1: Performance of Zyda-2 vs other open-source language modeling datasets. We observe that models annealed using Zyda-2 dataset outperform these competing datasets in aggregate eval scores. Aggregate score is a mean of: MMLU, Hellaswag, Piqa, Winogrande, Arc-Easy and Arc-Challenge.
Zyda-2 comprises the majority of open-source high-quality tokens available online. Specifically, it consists of DCLM, FineWeb-Edu, Zyda-1, and the Common-Crawl portion of Dolma v1.7.

Figure 2: The composition of Zyda-2 in terms of the originating dataset for each document.
DCLM and FineWeb-Edu have already undergone significant quality filtering as a core component of their creation and so perform extremely strongly on many benchmark tasks. Zyda-1 and Dolma-CC are less filtered datasets and contain a higher variety of internet documents which are not all designed to be educational. While these datasets lead to worse performance on small model ablations, we believe that for larger models having greater dataset diversity is extremely important and indeed combining the Zyda-1 and Dolma-CC portions with FineWeb-Edu and DCLM leads to increased downstream evaluation performance.
We perform cross-deduplication between all datasets. We believe this increases quality per token since it removes duplicated documents from the dataset. Following on from that, we perform model-based quality filtering on Zyda-1 and Dolma-CC using NeMo Curator’s quality-classifier-deberta, keeping only the ‘high-quality’ subset of these datasets.

Figure 3: Schematic of how Zyda-2 was produced.
The combination of all these datasets improves overall performance so that Zyda-2 outperforms each of its individual component datasets. We believe this is both due to our cross-deduplication efforts as well as an ensembling effect where combining a variety of data sources obtained through different processing pipelines leads to more diverse data which improves model performance and robustness.
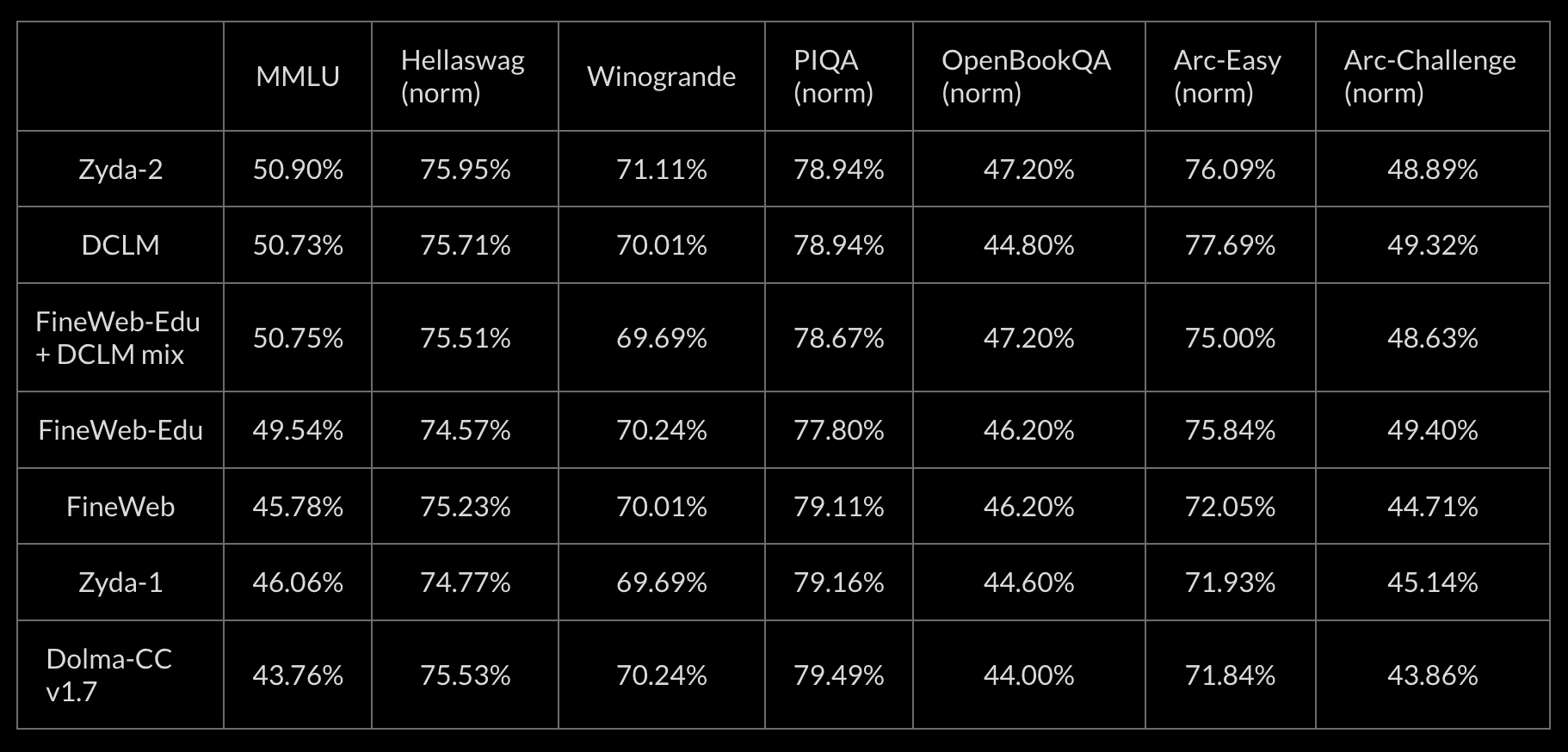
Table 1: Evaluation scores for Zyda-2 vs alternative datasets broken down more granularly by specific evaluation metric
The Making of Zyda-2
To create Zyda-2 we first obtained our starting data sources, DCLM, FineWeb-Edu-score-2 (FineWeb-Edu2 for short), Zyda-1 and Common Crawl portion of Dolma v1.7 (Dolma-CC for short), and then put them through a two-stage pipeline (see Fig. 3). We chose the FineWeb-Edu2 version of FineWeb-Edu to have a much bigger starting pool of documents. The first stage was a cross-deduplication stage applied to all datasets followed by a model-based filtering stage applied to Zyda-1 and Dolma-CC.
As the final step we decided to filter FineWeb-Edu2 by its educational score, essentially converting it to FineWeb-Edu, which is the recommended version of FineWeb-Edu dataset. We elaborate on the reasons below.
This whole process results in the best possible version of each subset, comprising the final dataset of 5T tokens.
Cross-deduplication
Our first phase was to perform deduplication across our component dataset since, given that they all ultimately originated from likely similar Common Crawl scrapes, they may contain significant fractions of duplicated documents. Deduplication has been found to generally improve language modeling performance although recent papers have claimed its effects are neutral and maybe negative, which we discuss later.
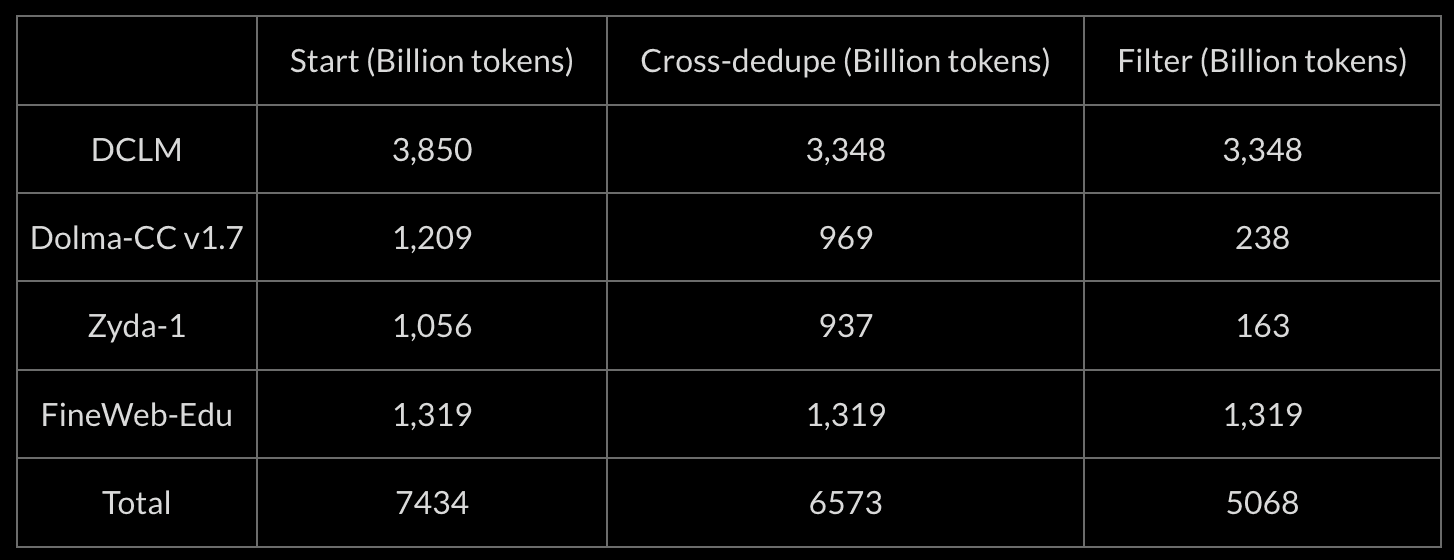
Table 2: The number of tokens (in billions) in each dataset at the start of the dataset processing, after cross-deduplication, and after filtering. DCLM and FineWeb-Edu are not filtered since they had already been filtered by their own model-based classifiers. FineWeb-Edu is used as the originator dataset for deduplication, meaning that if duplicates are detected in FineWeb-Edu and in some other dataset, they will be removed from the other dataset, which is why it does not lose tokens during deduplication.
As expected we found a significant number of duplicated documents across datasets, which resulted in us removing approximately 32% of the total tokens from Zyda-2 compared to its source dataset. We used the approximate minhash LSH deduplication that is provided in NeMo Curator for our deduplication pipelinewith the following parameters: minhash with signature size of 128 computed on character-based 25-grams signatures and split into 8 bands, giving roughly 85% Jaccard similarity threshold. Then we constructed an undirected graph with nodes being documents and edges being duplicates, and found connected components in it, which basically provided us with clusters of duplicates. Duplicates in FineWeb-Edu2 and DCLM.
While performing our deduplication analyses, we also performed a full intra-dataset deduplication of both DCLM and FineWeb-Edu. We found that both datasets contained a very large number of internal duplicates. For FineWeb-Edu this had previously been noticed but our result is also true of DCLM where we believe we have found 80% duplicates. Both the DCLM and FineWeb-Edu papers claim that internal dataset deduplication did not improve their results and so they did not pursue it or release a deduplicated version of their datasets.
These results raise several interesting questions. Firstly, it is unclear why removing duplicates does not improve performance. This implies that documents with large numbers of identical tokens provide approximately the same benefit as fresh tokens from the same distribution. We can perhaps consider a highly duplicated dataset like FineWeb-Edu as equivalent to performing a 2-5 epoch shuffled run on a much smaller deduplicated dataset. This implies that a small number of epochs do not particularly harm language model performance at these scales. However, this effect may not hold true at larger scales where language models can perform much more sample-efficient memorization of the training dataset, thus requiring more regularization to counter overfitting on multi-epoched text data.
If this is true, however, it is unclear why earlier results showed positive effects of deduplication. One possible hypothesis we hold is that the early datasets where deduplication was found to hold were not strongly filtered by model-based classifiers like DCLM and FineWeb and thus the deduplication step may simply be removing many low-quality spam documents that occur often in unfiltered web data, and hence the deduplication may simply be acting as an implicit filter. However, in more stringently filtered datasets, the magnitude of this effect diminishes and disappears in the evaluation noise. However, we do note that the most frequent duplicate in DCLM is indeed a spam document which indeed seems to have been low quality. Additionally, we notice that on supposedly ‘duplicate’ data, the scores assigned by the quality model often vary significantly despite only very minor differences in text, which is perhaps indicative of the relative lack of robustness in some of these classifiers or the presence of significant fractions of false-positives in the dedupe step.
To be cautious, we decided not to change the deduplication strategy of DCLM and FineWeb-Edu at this point, and we limited the extent of deduplication to only cross deduplication between the datasets. So we only considered clusters that contained documents coming from different sources. For every cluster we sorted documents based on the ranking FineWeb-Edu2 -> DCLM -> Zyda-1 -> Dolma-CC, preserved documents from the highest ranking source and removed the rest.
Model-based filtering
Since Zyda-1and Dolma-CC, unlike FineWeb-Edu and DCLM, have not been processed by model-based filtering, we decided to experiment with the quality-classifier-deberta provided in NeMo Curator. We applied this filter to Zyda-1and Dolma-CC and experimented with removing either only the ‘low’ quality documents or keeping only the ‘high quality’ ones. We found that keeping only the high quality documents 10-20% of the total significantly improved model performance.

Figure 4: Effect of training on the full Zyda-1and Dolma datasets vs only those documents labelled ‘high’ in the quality classifier. For both datasets we observe significant improvements through filtering.
This is likely because, since the original datasets are not filtered by model-based classifiers (although Zyda-1has significant syntactic filtering), both datasets contain large numbers of web documents which do not help particularly with downstream language modeling tasks.
As an additional step, we filtered FineWeb-Edu2 by its educational score basically converting it to FineWeb-Edu, a higher-quality subset of FineWeb-Edu2 comprising samples with the higher score 3 based on the FineWeb quality filter model. This scoring method yielded the best performance in the ablations conducted during the creation of FineWeb-Edu. Notably, we applied this filtering after cross-deduplicating DCLM against FineWeb-Edu2, which involved eliminating all samples in DCLM deemed duplicates with FineWeb-Edu2. This sequence of steps indirectly applied the FineWeb quality classifier to DCLM, effectively removing the samples in DCLM with lower educational content.
Zyda-2 Evaluation Methodology
Evaluating the quality of datasets is challenging without training large scale models upon them, which costs significant compute and is infeasible for every possible dataset ablation. One typical approach to get signal on such dataset ablations is to train small models on small slices of the dataset (for instance a 300 million parameter model on 100 billion tokens) and then compare the evaluation performance of such models. This is the approach taken by the vast majority of recent papers and datasets released. This approach has advantages in that it is computationally feasible to run many such experiments even on relatively constrained resources but for such small models many standard evaluations do not show strong signal (for instance MMLU remains at chance for such models) and often even when there is signal it is noisy.
An alternative approach is to utilize the newly popular annealing approach to training LLMs. It has been found that training an LLM on a large amount of data with a relatively slow learning-rate decay followed by a rapid learning rate decay over a high quality dataset can significantly improve performance. Many recent models have reported using such an annealing strategy although details are often sparse.
Blakeney et al proposes utilizing the annealing phase as a method to test the performance of different datasets. While not requiring significantly more compute than training a small model from scratch, annealing enables much larger and already trained base models to be used which can show signal on important evaluation metrics such as MMLU.
We validate the results proposed in this paper where we see significantly less signal on our dataset ablations using small models vs annealing. We perform our annealing ablations on our pre-annealing checkpoint of our Zamba2-2.7B model which we run for 40 billion tokens. Since our Zamba2-2.7B model is significantly above chance at MMLU and is already highly trained on approximately 3 trillion tokens we observe a clear signal on all standard ablations and additionally greater sensitivity to changes in dataset composition.

Figure 5: Aggregate eval scores across time during the annealing. Due to the dataset distribution shift all eval scores decrease in the first few billion tokens before returning to a higher level. Zyda-2 performs at a higher level than alternative datasets throughout the annealing phase and its advantage is established early on in training.
Subset weightings
An important question, given that Zyda-2 is derived from four pre-existing datasets, is what the optimal weightings of these datasets is. We conducted a series of experiments to determine this using our annealing scheme described previously. We found that a uniform weighting of dataset proportion by the total number of tokens in the dataset is suboptimal and that upweighting Fineweb-Edu to an equal proportion as DCLM performed optimally. Due to their smaller sizes together Zyda-1and Dolma-CC in total make up approximately 5% of the total dataset.

Figure 6: The distribution of the documents into their constituent dataset s for the optimal dataset weighting. We observe that weighting DCLM and FineWeb-Edu near-equally leads to optimal performance. Adding a small amount of Zyda-1 and Dolma-CC into the dataset also increases performance and likely robustness despite these datasets not having undergone the strict educational quality filtering of DCLM and FineWeb-Edu
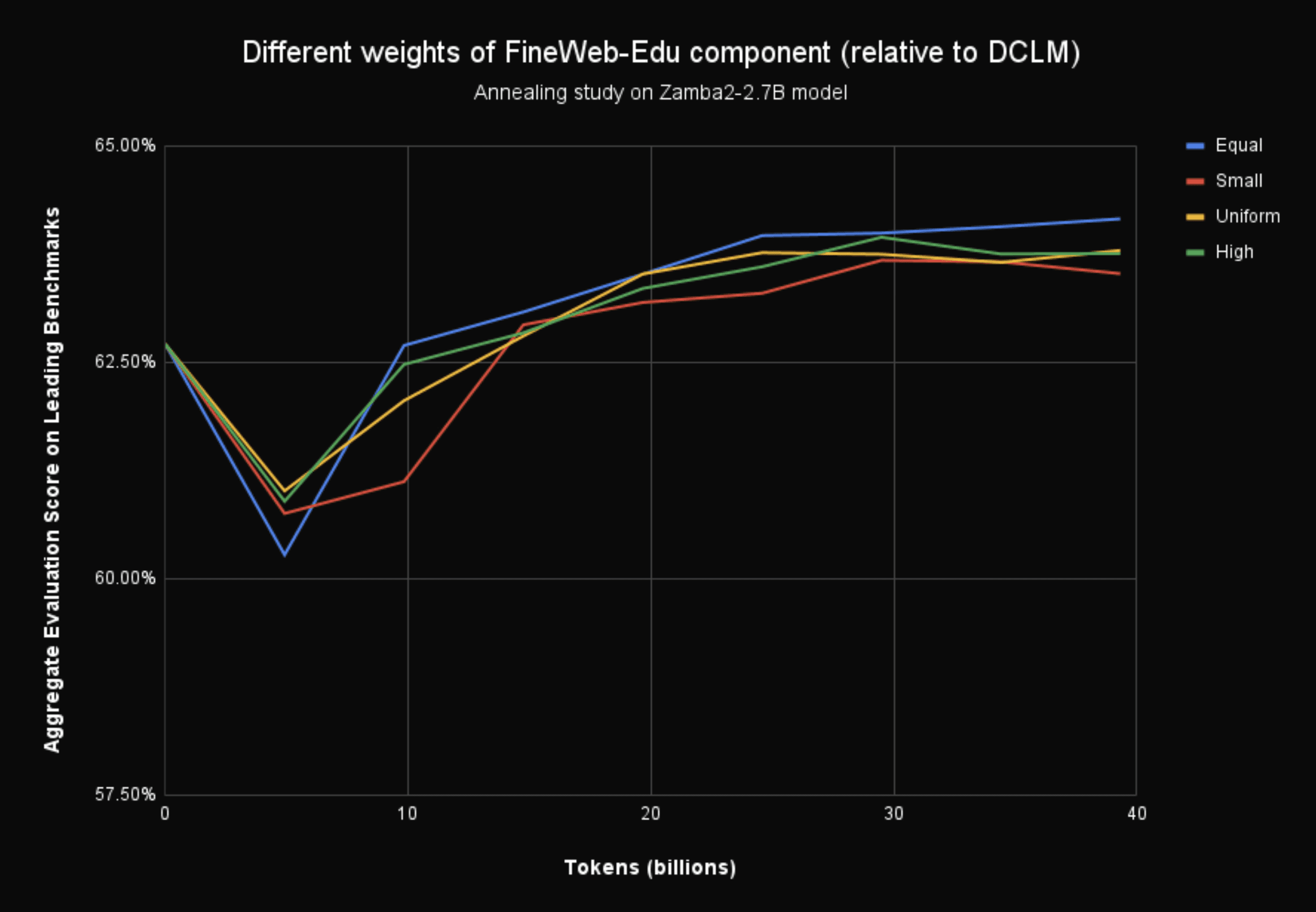
Figure 7: The aggregate evaluation scores across time for different upweightings of FineWeb-Edu3 in the total dataset. We observe that upweighting FineWeb-Edu to approximately the same size as DCLM in total documents gives the best performance.
Lower TCO & Faster Time to Market with NeMo Curator
For our quality filtering and deduplication steps we utilized NeMo Curator for dataset processing. We found that it performs extremely well for distributed multi-GPU dataset processing. NeMo Curator supports Infiniband, which enables excellent scaling on multi-node setups.
We benchmarked NeMo Curator against our previous CPU-based Python package Zyda-Processing. We compared running both packages on a single instance of a3-highgpu-8g on Google Cloud, which has 208 vCPUs, 1.9TB of RAM and 8 H100s 80GB GPUs. This is a typical setup for a node of H100s.
We found that running NeMo Curator on this node using GPUs is 10 times faster than running our Zyda package. Processing the whole raw dataset (which is roughly 12 billion documents with 11.5T tokens) would only take roughly 2 days on 8 GPU nodes. At the same time processing on 8 CPU nodes would take roughly 3 weeks.
We find that performant CPU nodes with enough RAM and good networking capabilities typically cost 5 times less than a node of H100s. By leveraging NeMo Curator and accelerating the data processing pipelines on GPUs, our team reduced the total cost of ownership (TCO) by 2x and processed the data 10x faster (from 3 weeks to 2 days).
In conclusion, NeMo Curator is a powerful tool that allows us to not only to scale our data processing capabilities, but optimize costs.
Get Started
Download the Zyda-2 dataset directly from Hugging Face and train higher-accuracy models. For more information see our GitHub tutorial.
Appendix
Analysis of Global Duplicates
We present histograms depicting distribution of cluster sizes in all the datasets (see Fig. 7-11). Please, note that all the figures are in log-log scale. We see a significant drop in the number of clusters starting from the size of around 100. This drop is present both in DCLM and FineWeb-Edu2 (see Fig. 8 and 9 respectively), and most likely is explained by a combination of the deduplication strategy and quality when creating both datasets: DCLM deduplication was done individually within 10 shards, while FineWeb-Edu2 was deduplicated within every Common Crawl snapshot. We find that large clusters usually contain low quality material (repeated advertisements, license agreements templates, etc), so it’s not surprising that such documents were removed. Notably, DCLM still contained one cluster with the size close to 1 million documents, containing low quality documents seemingly coming from the advertisements (see Appendix).We find both Zyda-1and Dolma-CC contain a small amount of duplicates, which is expected, since both datasets were deduplicated globally by their authors. Remaining duplicates are likely false negatives from the initial deduplication procedure. Note, that distribution of duplicates clusters sizes of these two datasets (Fig. 10 and 11) don’t contain any sharp drops, but rather hyper exponentially decreases with cluster size.
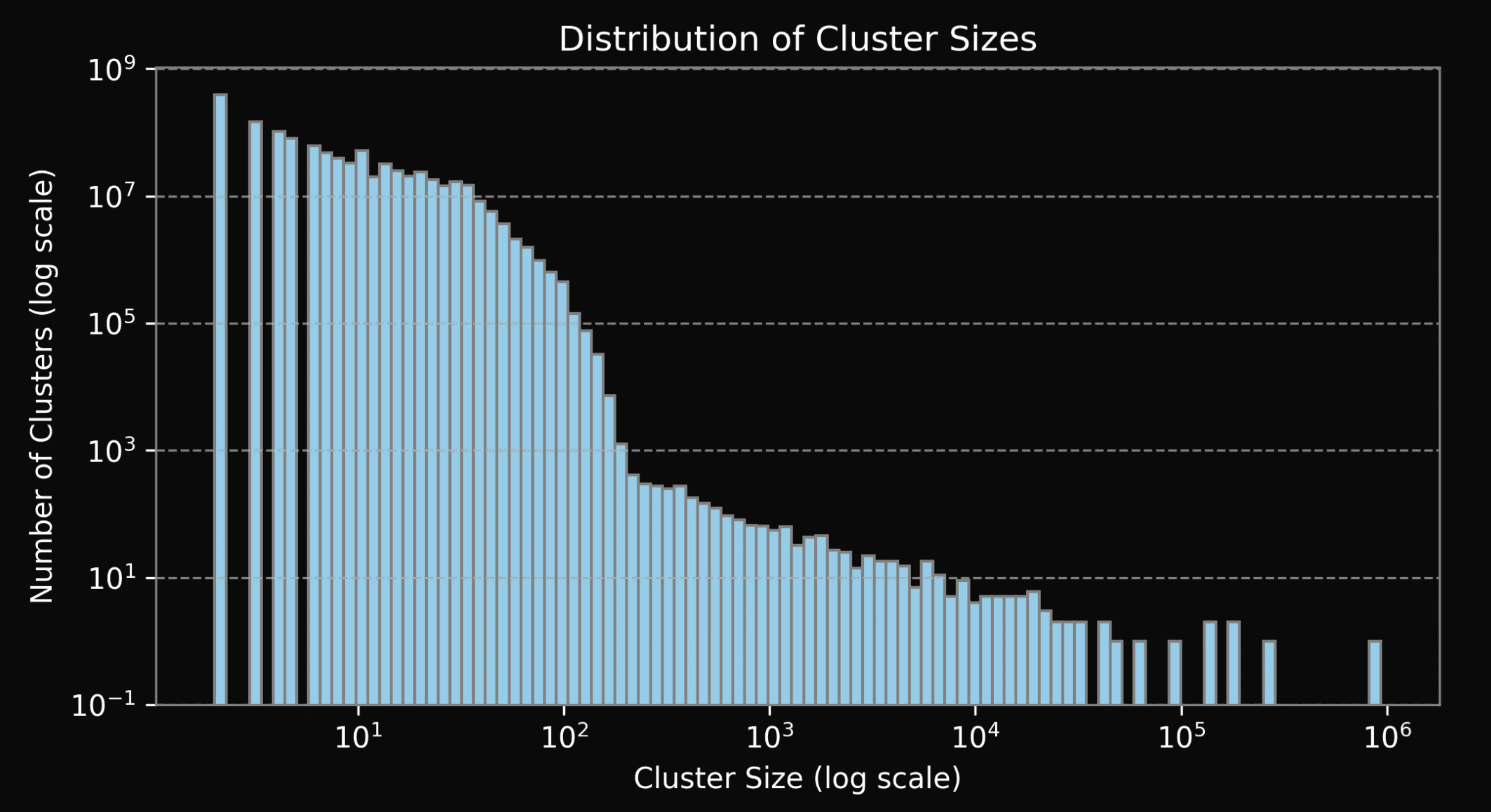
Figure 7: Distribution of cluster sizes of duplicates in global dataset (log-log scale).

Figure 8: Distribution of cluster sizes of duplicates in DCLM (log-log scale).
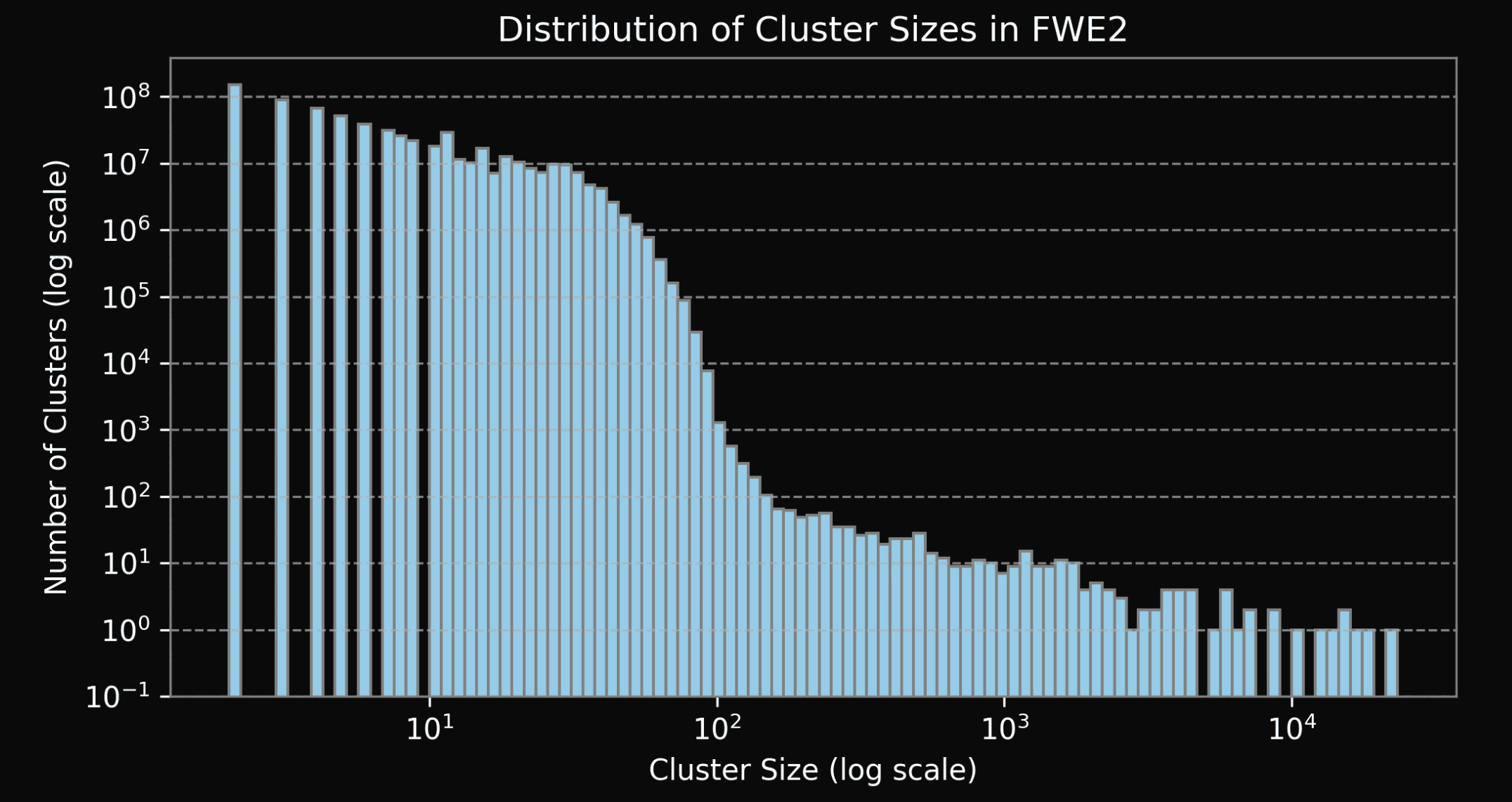
Figure 9: Distribution of cluster sizes of duplicates in FineWeb-Edu2 (log-log scale).
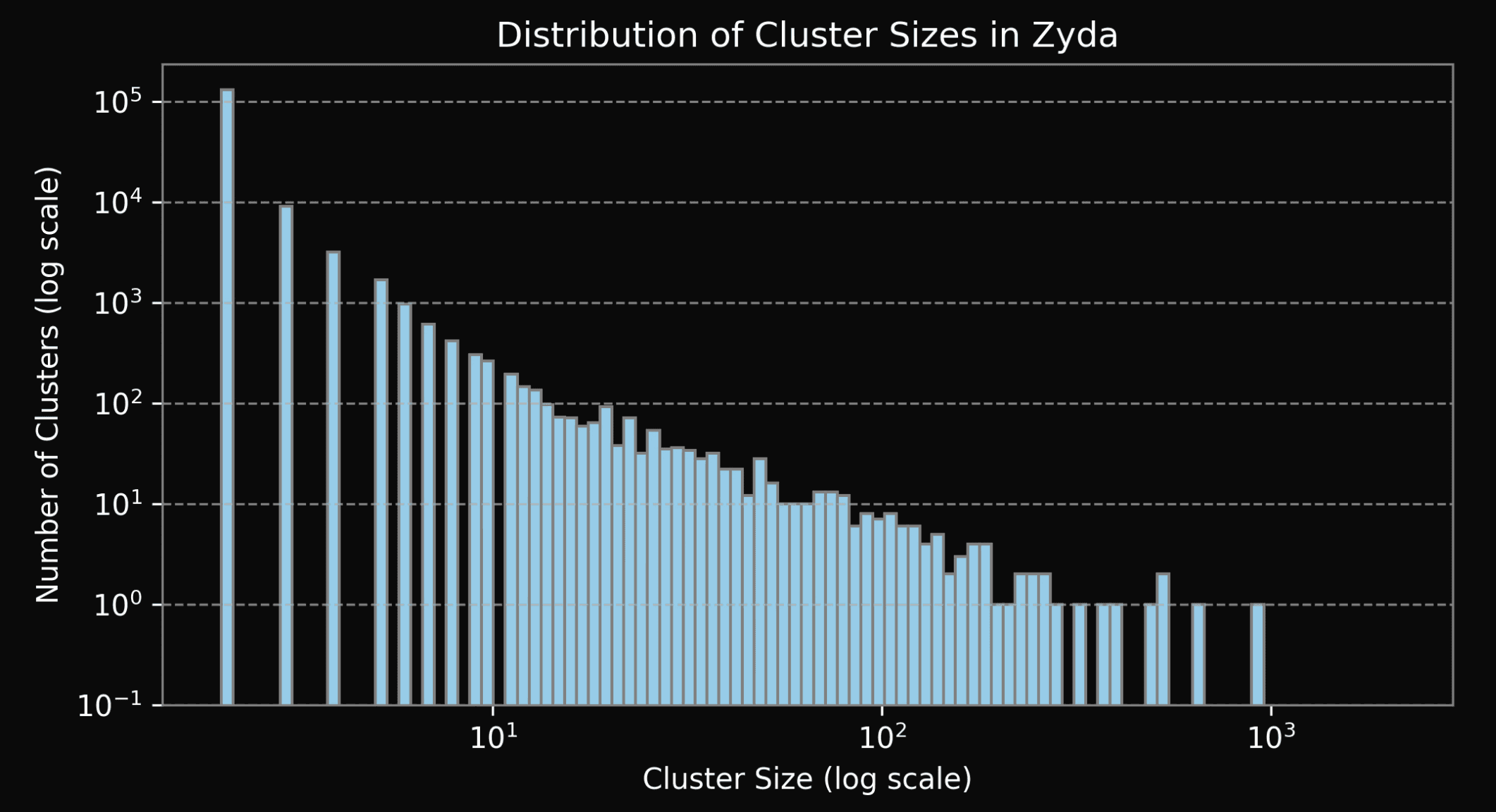
Figure 10: Distribution of cluster sizes of duplicates in Zyda-1 (log-log scale).
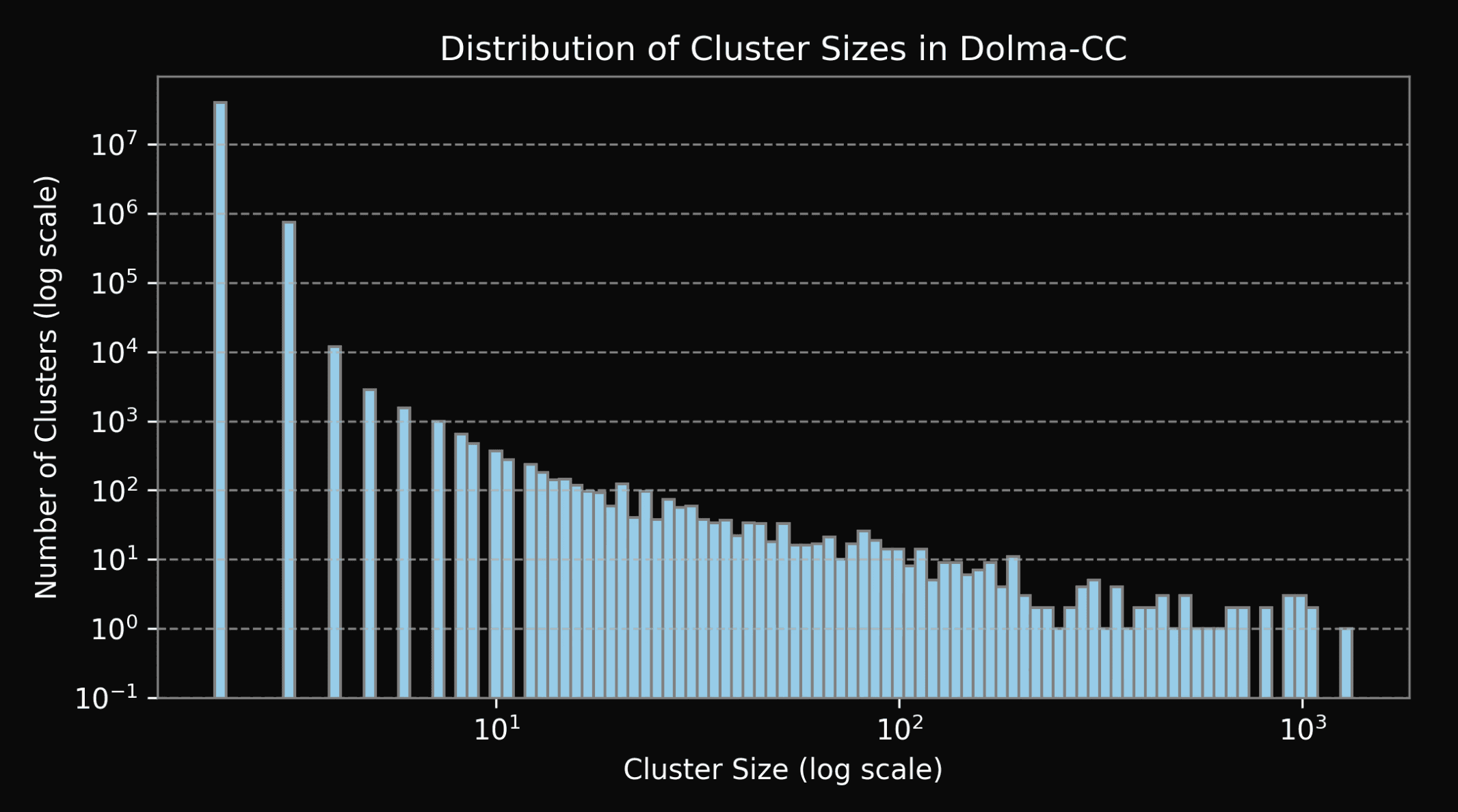
Figure 11: Distribution of cluster sizes of duplicates in Dolma-CC (log-log scale).
Largest cluster in DCLM
Below is an example of the document from the largest cluster (~1M documents) of duplicates in DCLM (quality score 0.482627):
Is safe? Is scam?
Is safe for your PC?
Is safe or is it scam?
Domain is SafeSafe score: 1
The higher the number, the more dangerous the website.Any number higher than 1 means DANGER.
Positive votes:
Negative votes:
Vote Up Vote Down review
Have you had bad experience with Warn us, please!
Examples of varying quality score in a cluster of duplicates in DCLM
Below one will find a few documents with different quality scores from DCLM coming from the same duplicates cluster. Quality score varies from ~0.2 to ~0.04.
Document ID: <urn:uuid:941f22c0-760e-4596-84fa-0b21eb92b8c4>
Quality score of: 0.19616
Thrill Jockey instrumental duo Rome are, like many of the acts on the Chicago-based independent label, generally categorized as loose adherents of "post-rock," a period-genre arising in the mid-'90s to refer to rock-based bands utilizing the instruments and structures of music in a non-traditionalist or otherwise heavily mutated fashion. Unlike other Thrill Jockey artists such as Tortoise and Trans-Am, however, Rome draw less obviously from the past, using instruments closely associated with dub (melodica, studio effects), ambient (synthesizers, found sounds), industrial (machine beats, abrasive sounds), and space music (soundtrack-y atmospherics), but fashioning from them a sound which clearly lies beyond the boundaries of each. Perhaps best described as simply "experimental," Rome formed in the early '90s as the trio of Rik Shaw (bass), Le Deuce (electronics), and Elliot Dicks (drums). Based in Chicago, their Thrill Jockey debut was a soupy collage of echoing drums, looping electronics, and deep, droning bass, with an overwhelmingly live feel (the band later divulged that much of the album was the product of studio jamming and leave-the-tape-running-styled improvisation). Benefiting from an early association with labelmates Tortoise as representing a new direction for American rock, Rome toured the U.S. and U.K. with the group (even before the album had been released), also appearing on the German Mille Plateaux label's tribute compilation to French philosopher Gilles Deleuze, In Memoriam. Although drummer Dicks left the group soon after the first album was released, Shaw and Deuce wasted no time with new material, releasing the "Beware Soul Snatchers" single within weeks of its appearance. An even denser slab of inboard studio trickery, "Soul Snatchers" was the clearest example to date of the group's evolving sound, though further recordings failed to materialize. ~ Sean Cooper, Rovi
Document ID: <urn:uuid:0df10da5-58b8-44d8-afcb-66aa73d1518b>
Quality score of: 0.091928
Thrill Jockey instrumental duo Rome are, like many of the acts on the Chicago-based independent label, generally grouped in as loose adherents of "post-rock," a period-genre arising in the mid-'90s to refer to rock-based bands utilizing the instruments and structures of the music in a non-traditionalist or otherwise heavily mutated fashion. Unlike other Thrill Jocky artists such as Tortoise and Trans-Am, however, Rome draw less obviously from the past, using instruments closely associated with dub (melodica, studio effects), ambient (synthesizers, found sounds), industrial (machine beats, abrasive sounds), and space music (soundtrack-y atmospherics), but fashioning from them a sound which lay clearly beyond the boundaries of each. Perhaps best described as simply experimental, Rome formed in the early '90s as the trio of Rik Shaw (bass), Le Deuce (electronics), and Elliot Dick (drums). Based in Chicago, their Thrill Jockey debut was a soupy collage of echoing drums, looping electronics, and deep, droning bass, with an overwhelmingly live feel (the band later divulged that much of the album was the product of studio jamming and leave-the-tape-running styled improvisation). Benefiting from an early association with labelmates Tortoise as representing a new direction for American rock, Rome toured the U.S. and U.K. with the group (even before the album had been released), also appearing on the German Mille Plateaux label's tribute compilation to French philosopher Gilles Deleuze, In Memoriam. Although drummer Elliot Dick left the group soon after the first album was released, Shaw and Deuce wasted no time with new material, releasing the "Beware Soul Snatchers" single within weeks of its appearance. An even denser slab of inboard studio trickery, "Soul Snatchers" was the clearest example to date of the group's evolving sound, though further recordings failed to materialize.
Sean Cooper, Rovi
More Rome
You may also like...
Document ID: <urn:uuid:4986ef09-3ee3-4e13-9084-7898aaf72aaf>
Quality score of: 0.072259
recent on-air advertisers
Now Playing
You Control the ...
Artist Snapshot:
Thrill Jockey instrumental duo Rome are, like many of the acts on the Chicago-based independent label, generally grouped in as loose adherents of "post-rock," a period-genre arising in the mid-'90s to refer to rock-based bands utilizing the instruments and structures of the music in a non-traditionalist or otherwise heavily mutated fashion. Unlike other Thrill Jocky artists such as Tortoise and Trans-Am, however, Rome draw less obviously from the past, using instruments closely associated with dub (melodica, studio effects), ambient (synthesizers, found sounds), industrial (machine beats, abrasive sounds), and space music (soundtrack-y atmospherics), but fashioning from them a sound which lay clearly beyond the boundaries of each. Perhaps best described as simply experimental, Rome formed in the early '90s as the trio of Rik Shaw (bass), Le Deuce (electronics), and Elliot Dick (drums). Based in Chicago, their Thrill Jockey debut was a soupy collage of echoing drums, looping electronics, and deep, droning bass, with an overwhelmingly live feel (the band later divulged that much of the album was the product of studio jamming and leave-the-tape-running styled improvisation). Benefiting from an early association with labelmates Tortoise as representing a new direction for American rock, Rome toured the U.S. and U.K. with the group (even before the album had been released), also appearing on the German Mille Plateaux label's tribute compilation to French philosopher Gilles Deleuze, In Memoriam. Although drummer Elliot Dick left the group soon after the first album was released, Shaw and Deuce wasted no time with new material, releasing the "Beware Soul Snatchers" single within weeks of its appearance. An even denser slab of inboard studio trickery, "Soul Snatchers" was the clearest example to date of the group's evolving sound, though further recordings failed to materialize. ~ Sean Cooper, RoviSean Cooper, Rovi
More Rome
You may also like...
Document ID: <urn:uuid:1e0496a9-0116-418a-9aec-e65b1d20e709>
Quality score of: 0.0424
18 June 2015
ROME self titled 1996
by request
Artist Biography by
Thrill Jockey instrumental duo Rome are, like many of the acts on the Chicago-based independent label, generally categorized as loose adherents of "post-rock," a period-genre arising in the mid-'90s to refer to rock-based bands utilizing the instruments and structures of music in a non-traditionalist or otherwise heavily mutated fashion. Unlike other Thrill Jockey artists such as Tortoise and Trans-Am, however, Rome draw less obviously from the past, using instruments closely associated with dub (melodica, studio effects), ambient (synthesizers, found sounds), industrial (machine beats, abrasive sounds), and space music (soundtrack-y atmospherics), but fashioning from them a sound which clearly lies beyond the boundaries of each. Perhaps best described as simply "experimental," Rome formed in the early '90s as the trio of Rik Shaw (bass), Le Deuce (electronics), and Elliot Dicks (drums). Based in Chicago, their Thrill Jockey debut was a soupy collage of echoing drums, looping electronics, and deep, droning bass, with an overwhelmingly live feel (the band later divulged that much of the album was the product of studio jamming and leave-the-tape-running-styled improvisation). Benefiting from an early association with labelmates Tortoise as representing a new direction for American rock, Rome toured the U.S. and U.K. with the group (even before the album had been released), also appearing on the German Mille Plateaux label's tribute compilation to French philosopher Gilles Deleuze, In Memoriam. Although drummer Dicks left the group soon after the first album was released, Shaw and Deuce wasted no time with new material, releasing the "Beware Soul Snatchers" single within weeks of its appearance. An even denser slab of inboard studio trickery, "Soul Snatchers" was the clearest example to date of the group's evolving sound, though further recordings failed to materialize.
1 Leaving Perdition 8:10
2 Intermodal 3:39
3 Lunar White 3:25
4 She's A Black Belt 3:14
5 Rohm 1:09
6 Radiolucence (Version) 5:31
7 Deepest Laws 14:14
No comments: