
Research
Palo Alto, California
Zyphra’s NeuraNoC is a pioneering packet-switched network-on-chip (NoC), named for its routing mechanism that resembles the spiking behavior of neurons in the brain by encoding processor connections as Bernoulli processes. It is the first NoC to be trained at compile time to precisely match the bandwidth requirements between connected processors, making it ideal for ML workloads with predictable and sustained bandwidth profiles. Although the packet routing in a hardware network may seem stochastic for a given connection, it is actually deterministic and predefined. This is achieved by treating the packets as carriers that may or may not contain a payload. This approach is similar to time domain multiplexing in arbitrary connectivity graphs. This NoC eliminates all memory blocks typically required in network routers and processing units for packet exchange. As a result, NeuraNoC drastically reduces the silicon footprint, allowing more space for additional compute resources or local memory.
Tomás Figliolia
Introduction
Computational ML models can be represented as a graph, where the nodes denote operations and the edges denote the amount of information exchanged between connected nodes. These nodes (or groups of nodes, as illustrated in Figure 1) can then be mapped to processors in an array – for instance individual tensor cores in a GPU – based on the operations they require, the memory they need, and their connections to other nodes, with careful consideration of their proximity to connected neighbors in the graph.
The process of assigning a specific processor in an array to a node in the graph is known as "mapping". Information exchange between processors within the die is managed by an on-chip interconnect fabric. The process of programming this interconnect fabric is referred to as “routing”. Developing mappers and router compilers for these interconnect fabrics is usually a complex and challenging task since they must balance the spatial topology of processors on the chip and the bandwidth requirements of particular programs to ensure the processors can be fully utilized.
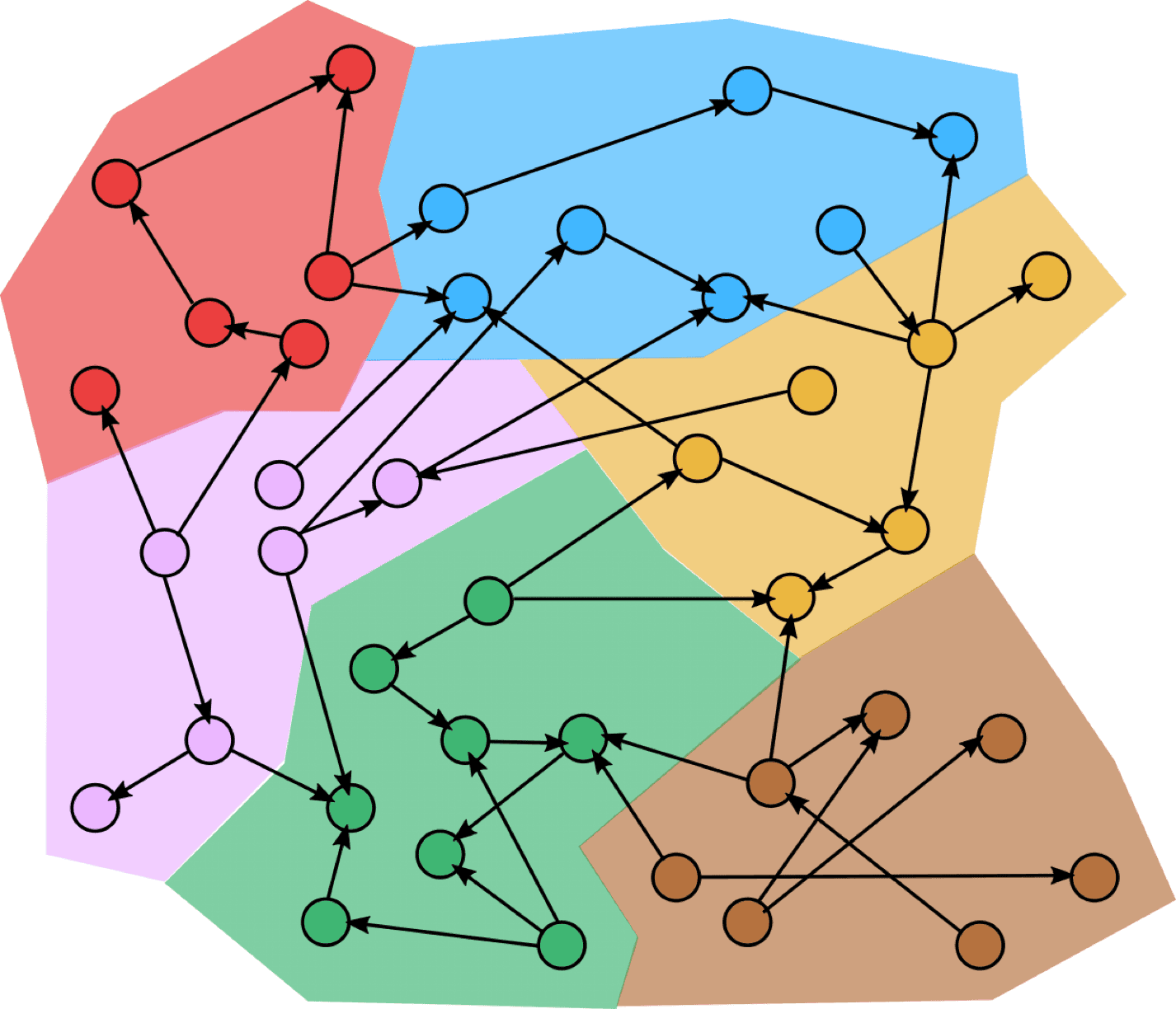
Figure 1. Example of a computation graph that can be collapsed into different clusters of nodes that are used to map on multi-core arrays.
As fabrication processes advance, enabling more transistors to be packed into a given silicon area, it becomes possible to integrate more processing units on these dies. This increase in processing units leads to significantly higher on-chip memory bandwidth, as demonstrated by chips like Tesla’s Dojo, Cerebras WSE-3, and Groq's LPU. However, as the number of processors increases, the need for an efficient interconnect strategy becomes crucial—one that can sustain bandwidth levels comparable to those between a processor and its local memory.
Commonly the interconnect fabric of choice are networks on chip (NoCs), which traditionally introduce significant overheads in silicon area, primarily due to the memory required to temporarily store data in NoC switches or to hold packets until the corresponding processor is ready to process them. In networks that enable point-to-point connections between any two processors, these memories are implemented on-chip as SRAM blocks. This results in significant silicon overhead when multiple blocks are needed for each NoC switch, often leading to a large portion of the silicon area being dedicated to the on-chip NoC.
Our proposed NeuraNoC overcomes the challenges inherent in traditional NoC designs. It is the first NoC system to undergo a "training" process at compile-time tailored to meet the bandwidth demands of specific workloads, simplifying the place-and-route process. We regard the packets routed in the network as 'carriers', whose behavior is entirely independent of the specific state of any processors exchanging information with the NoC. These carriers define the bandwidth between connected nodes and operate in a completely deterministic manner, similar to time slots in time domain multiplexing within a token ring network. This determinism enables processors to precisely know when they can send and receive data, down to the exact clock cycle. Processors knowing specifically the clock cycle where they will either receive or can send data, allows to further remove the inbound and outbound buffers usually present in networks on chip. Moreover, NeuraNoC eliminates all buffers typically found in switches, allowing for the complete removal of the memory usually required in conventional NoC approaches, allowing to achieve a very low silicon area footprint, while still maintaining homogeneous latency and bandwidth over time.
Thanks to ML workloads featuring predictable and generally static bandwidth profiles for long periods of time, they are particularly suitable for the NeuraNoC, as those bandwidth profiles can be provided at compile time. We have developed an algorithm that takes as an input these bandwidth profiles and produces a highly efficient configuration for the NoC to satisfy those needed internode bandwidths.
Overview
Zyphra's NeuraNoC, is a highly adaptable multi-processor array fabric that operates efficiently with minimal prerequisites and no dependence on a specific network topology. Designed to avoid deadlocks and livelocks, the NeuraNoC ensures packet delivery within a finite number of cycles without packet losses. Differing from other NoCs that utilize local buffers to manage traffic, the NeuraNoC operates without buffers or FIFO memories, thereby minimizing the silicon footprint in multi-processor arrays. This predictable and deterministic behavior enables processing units (PUs) to precisely time the injection and reception of packets without depending on queueing buffers.
In conventional networks on-chip, a processor connected to a network switch consumes data at a specific input rate R_in, while the data may arrive from the NoC at a different rate R_NoC. Typically, each network switch is built with a small amount of local SRAM memory to which packets destined for a node must be written. Within a network node, PUs may use the local memory for various purposes, causing incoming packets from the NoC to wait for available bandwidth to be written locally, resulting in fluctuations in input rate R_in and leading to large buffers being required to ensure packets are not dropped.
Both R_in and R_NoC can be viewed as random variables, with instantaneous rates that can vary over time but with average rates that must be equal E(R_in(t) = E(R_NoC(t))). Similarly, the rate at which a PU wants to inject packets into the NoC (rate R_out) can differ from the rate at which the NoC can send packets to other PUs (rate R_NoC). As R_out, R_NoC, and R_in can fluctuate over time, intermediate buffers are necessary to alleviate any instantaneous rate changes. Generally, these buffers are implemented as the inbound and outbound network buffers found in traditional network nodes as seen in figure 2.
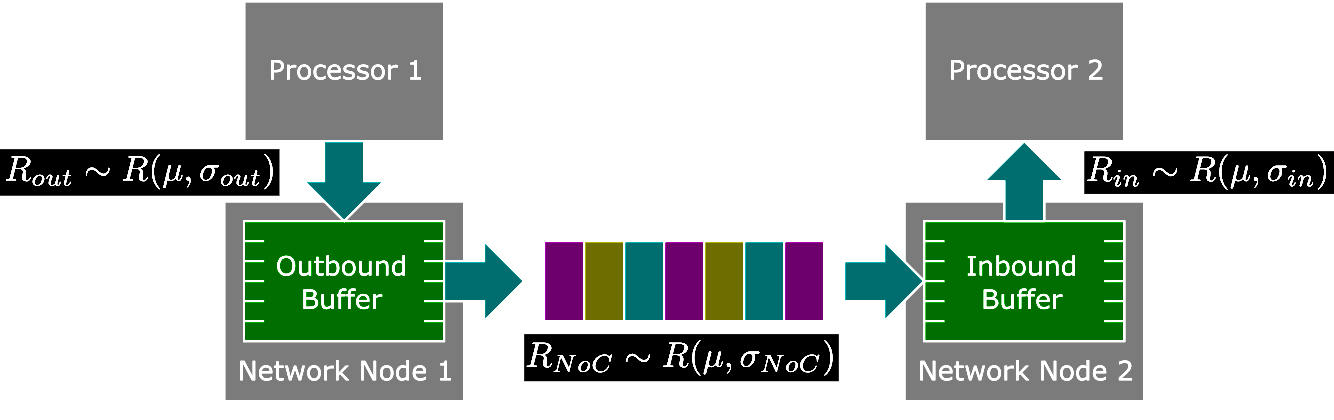
Figure 2. Example of a more traditional NoC, where buffers are used to smooth the effect of instantaneous data rate changes. Traffic flows from one network node to another one. The rate node 1 outputs data will be distributed as R_out ∼ R_out(μ,σout), and the rate at which node 2 can receive data will be R_in ∼ R_in (μ, σin ). Due to the NoC not having all its time slots necessarily free, the rate at which packets can be taken from PU 1 will be _RNoC ∼ R_NoC(μ,σNoC).
The predictability of traffic found in the NeuraNoC eliminates the need for the intermediate buffers used in equalizing data rates. Furthermore, no other buffers – such as the buffers required to further equalize traffic from different interfaces in a node switch used in traditional NoC designs – will be needed in our NeuraNoC design. With a hardened NoC configuration driven by workloads of interest, our NoC compiler allows us to specify the needed bandwidth between any logically connected nodes at compile time.
The NeuraNoC only features registers in the buses connecting neighboring nodes, as seen in Figure 3. Even though this example shows the case of a 4x4 mesh, the proposed network works for any network topology chosen, as long as a series of simple requirements are satisfied. Generally, when considering the “place and route” (P&R) backend process of a NoC, the number of pipelining stages between nodes is chosen based on the target clock frequency, and any addition of pipelining stages will only serve this purpose. On the other hand, our proposed design cleverly utilizes the registers between nodes as the traffic equalizing buffers. Therefore, the buffers that traditional NoC designs place inside every network node, as shown in figure 2, can now be embedded into the edges of the network itself. This design allows all the nodes to share these memory elements more efficiently.
With this in mind, the proposed NeuraNoC network can dramatically reduce silicon resources compared to other NoCs since it does not require any memory blocks of any kind. The addition of pipelining stages will now not only help in achieving the desired clock frequency, but will also increase the overall embedded NoC buffer size, thereby both increasing the network’s degrees of freedom and allowing the system to more accurately achieve the desired bandwidths between logically-connected nodes.

Figure 3. This is an example of a 4 x 4 2D mesh. The proposed network will only feature registers in the buses connecting neighboring nodes (drawn in light blue).
Two different networks have been developed, with or without directional edges, showcased in figure 4.
Directed Graph NoC (DGNoC)
A connection from node B to node A reads data from B and writes into A. DGNoC is useful in simulating directed graphs such as data pipeline systems, inference calculation, etc.
Non-Directed (or bidirectional) Graph NoC (NDGNoC)
A connection from node B to node A both reads data from A and writes into B, and reads from node B and writes into A. NDGNoC is useful for simulating non-directed computational graphs such as dynamical systems, non-directed ML graphs, some energy-based training algorithms, ML training, etc.
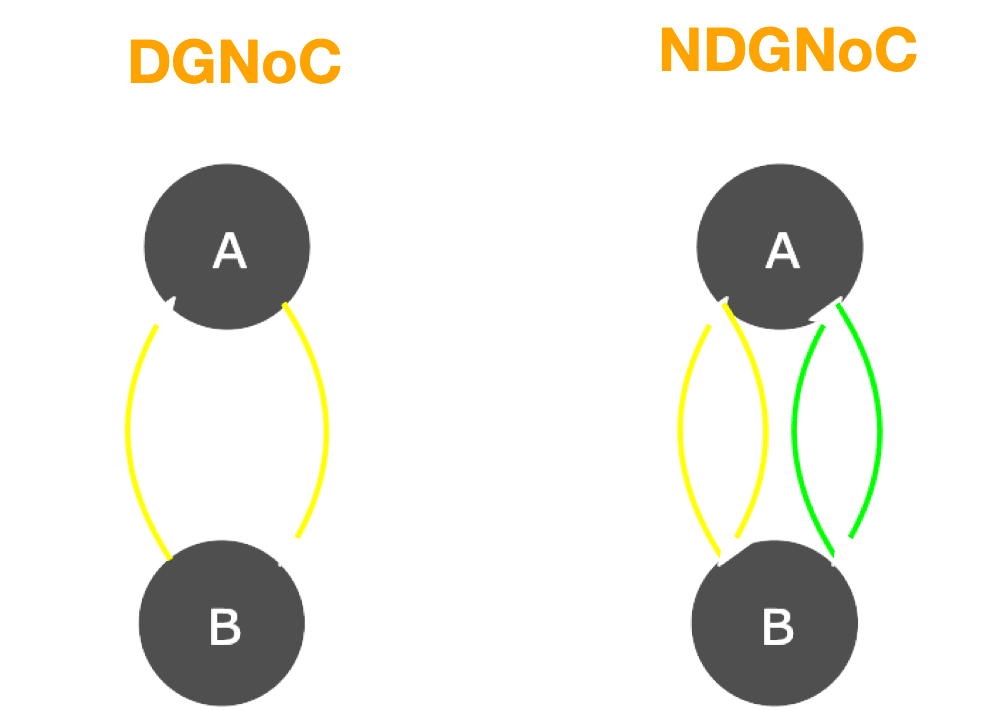
Figure 4. Two nodes connected with directed (left) and non-directed (right) NeuraNoC nodes.
How can we report NoC performance results?
NoC performance results need to be presented based on particular workloads of interest. Precise and specific workloads are difficult to come up with and to test rigorously, because they require graph pre-compilers, and proper hardware graph mappers. This is why it is very difficult to find actual performance results for NoC designs, and many of those found are very questionable. Cerebras claims numbers like “total fabric bandwidth to 220 petabits per second”, or Graphcore claims “47.5TB/s memory bandwidth per IPU”. Those numbers do not mean much if those are not bandwidths that are actually sustained over time for an actual meaningful workload. How can we provide generic performance results that are actually meaningful?
To address this, we designed a benchmark where we measure the ability of the network to exploit data locality, and for that we will define a receptive field for every node in the NoC. The receptive fields are defined by a target Hamming Distance. The workloads we will test will consider all nodes in the NoC to be connected to nodes that are within a given Hamming Distance (HD). A HD of 1 will make nodes be connected only to their nearest neighbors, and a very high HD will make the NoC behave closer to a crossbar.
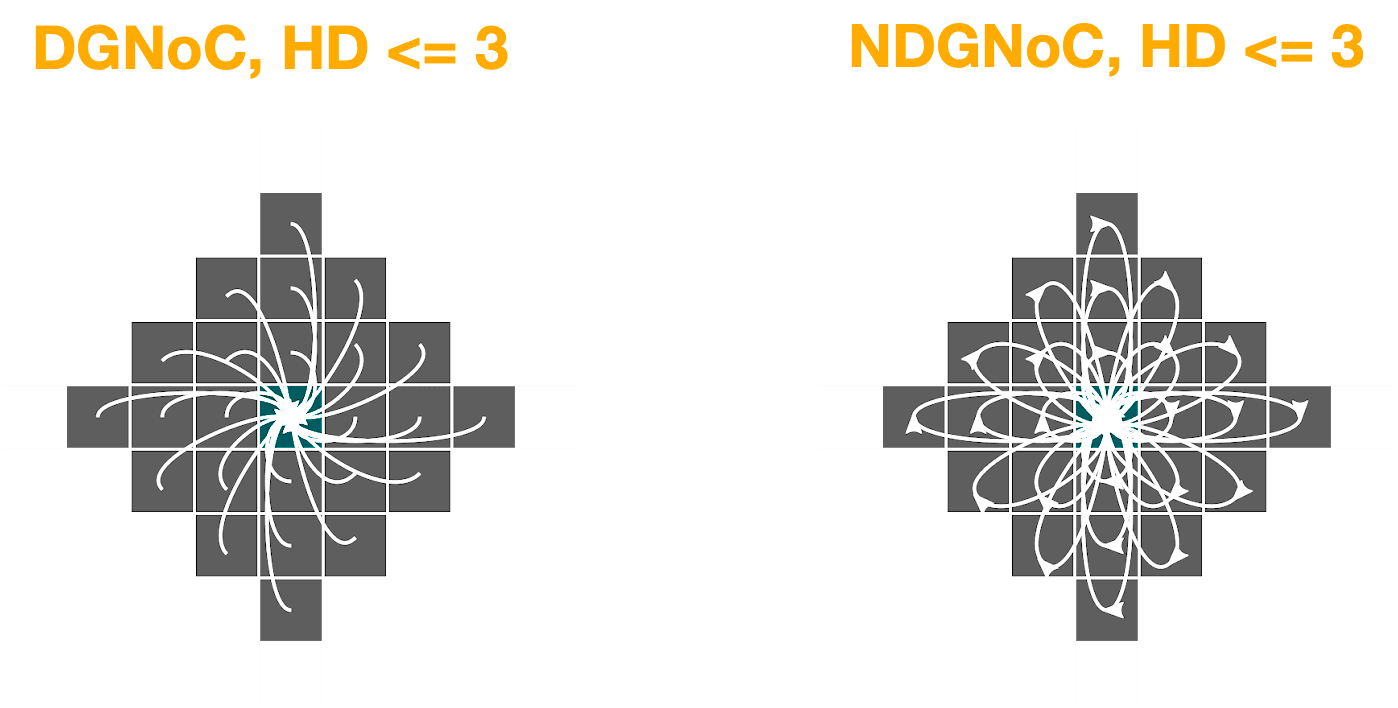
Figure 5. Left is showing the case of a directed graph, and the right one undirected. We make every node be connected to nodes within a given hamming distance.
Assuming a toroid topology, and having each node connected to its neighbors within a specified Hamming distance, we estimated the energy dissipation, bandwidth, and precise PPA outcomes for TSMC 5nm process. Utilizing our network compiler and a cycle-accurate emulator, we confirmed that PPA remains constant for a given network connectivity density, regardless of the number of nodes present in the NoC. This benchmark we developed enables quick performance evaluation based on the local connection density in a computational graph, eliminating the need to execute the network compiler for each workload.
In this video, we showcase a 10x10 torus NoC setup with 256 randomly established connections featuring varied bandwidths. The arrows linking nodes illustrate the pipelining stages set between the network's processing units. In the upper right, the x-axis displays the various connections defined, with the target bandwidths for these connections highlighted in dark blue. As the network simulation progresses, the empirical bandwidths achieved, shown in light blue, will be observed converging to or exceeding these target values. In the bottom right corner, we detail the latencies experienced for each connection.
Left: 10x10 torus NoC configuration with 256 randomly set connections of different bandwidths. Arrows between nodes depict the pipelining stages among the network's processing units.
Right Top: The x-axis shows various connections with target bandwidths in dark blue. As the simulation progresses, actual bandwidths, displayed in light blue, converge to or exceed these targets.
Right Bottom: Latencies experienced for each connection.