
Research
Palo Alto, California
We empirically study a simple layer-pruning strategy for popular families of openweight pretrained LLMs, finding minimal degradation of performance on different question-answering benchmarks until after a large fraction (up to half) of the layers are removed. To prune these models, we identify the optimal block of layers to prune by considering similarity across layers; then, to “heal” the damage, we perform a small amount of finetuning. In particular, we use parameter-efficient finetuning (PEFT) methods, specifically quantization and Low Rank Adapters (QLoRA), such that each of our experiments can be performed on a single A100 GPU. From a practical perspective, these results suggest that layer pruning methods can complement other PEFT strategies to further reduce computational resources of finetuning on the one hand, and can improve the memory and latency of inference on the other hand. From a scientific perspective, the robustness of these LLMs to the deletion of layers implies either that current pretraining methods are not properly leveraging the parameters in the deeper layers of the network or that the shallow layers play a critical role in storing knowledge.
Paolo Glorioso, Beren Millidge, Daniel A Roberts (Sequoia Capital & MIT), Andrey Gromov (Meta FAIR), Kushal Tirumala (Meta FAIR) and Hassan Shapourian (Cisco)
Introduction
Large language models (LLMs) come with significant memory and computational demands, posing challenges in terms of efficiency and scalability which is especially important for on-device and local inference. Yet, there appears to be a substantial degree of redundancy in how the weights and internal representations of these models are utilized during inference. This redundancy indicates that it may be possible to optimize these models, reducing their memory and compute footprint without compromising performance. There are a number of techniques aimed at reducing these overheads for pre-trained language models. For instance, quantization can significantly reduce memory footprint of parameters, and pruning, as well as distillation, can reduce both memory usage and computational demands.
Design and Results
In this work, we introduce a straightforward pruning strategy which we apply to open-weight pre-trained LLMs. Specifically, we devise a method that identifies the most effective layers to prune by analyzing the similarity between representations at different layers. For a given pruning fraction, we remove the layers with the highest similarities and then "heal" the pruning-induced mismatch through a small amount of fine-tuning using QLoRA. Our key finding is that we can prune a significant portion of the deepest layers in the models while maintaining minimal degradation in downstream performance on multiple-choice benchmarks. For instance, in Llama-2-70B, we can prune nearly half of the layers before observing a significant drop in performance.
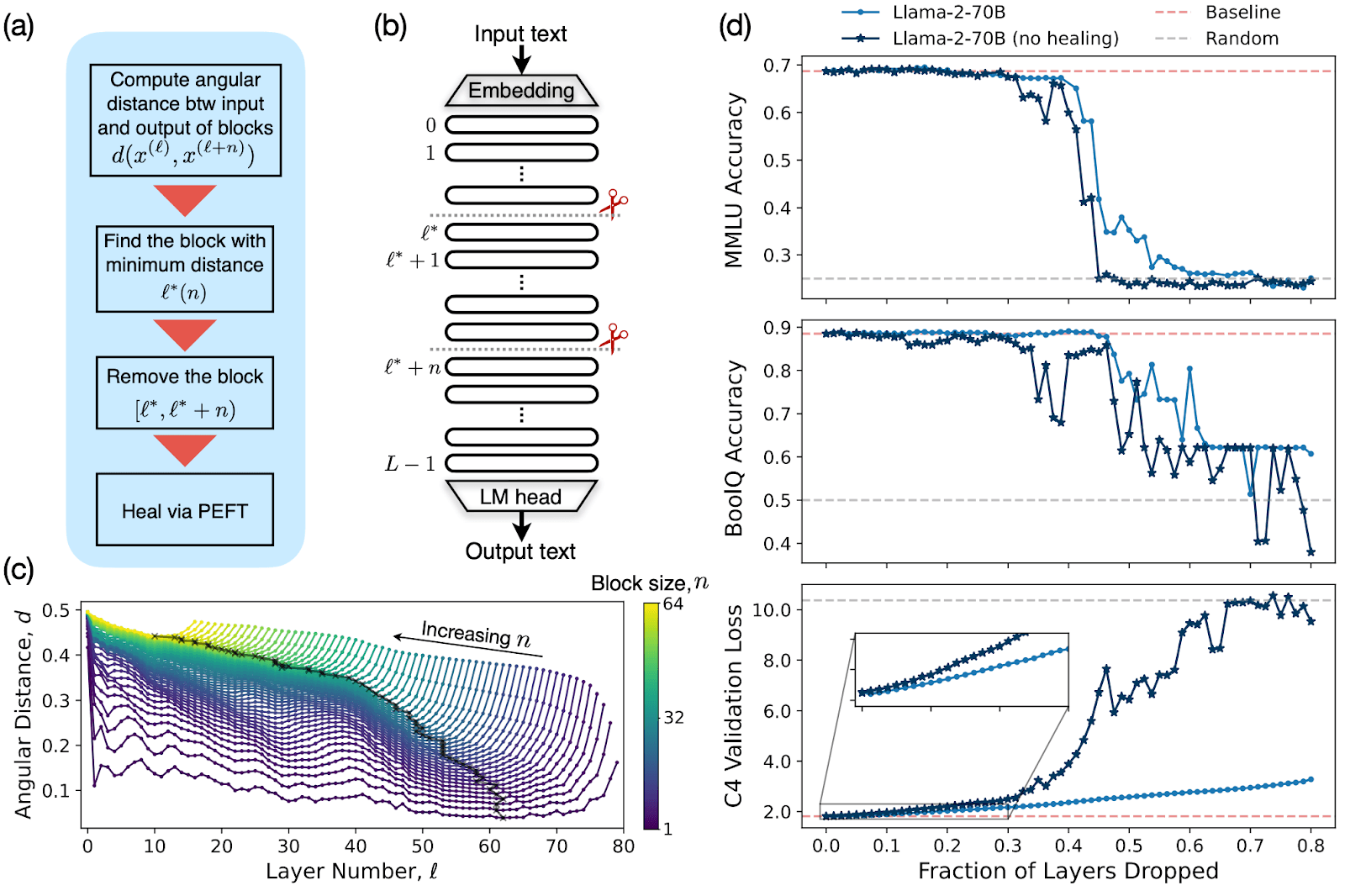
The Figure above shows an overview of the layer-pruning strategy and examples of the results for the Llama-2-70B model. (a): flowchart of the algorithm, where first we compute the angular distance between the outputs of layer \(\ell\) and \(\ell+n\), then we remove the block minimizing such similarity for a fixed \(n\), and finally we fine-tune the model to "heal" the effect of pruning. (b): a cartoon depicting the removal of \(n\) consecutive layers. (c): angular distance between the outputs of layer \(\ell\) and \(\ell+n\) for Llama-2-70B. (d): accuracies and C4 validation loss as a fraction of layers pruned for Llama-2-70B, with and without the fine-tuning step. These plots illustrate how the performance of two example multichoice benchmarks remains approximately constant up to pruning roughly 40% of the model's layers, and then abruptly drops. Note that, even without the healing step, performance is not degradated almost up until the transition happens. This underscores the effectiveness of the similarity-based pruning in choosing the best layers to drop.
We observed a similar behavior in performance in various open-weight models:
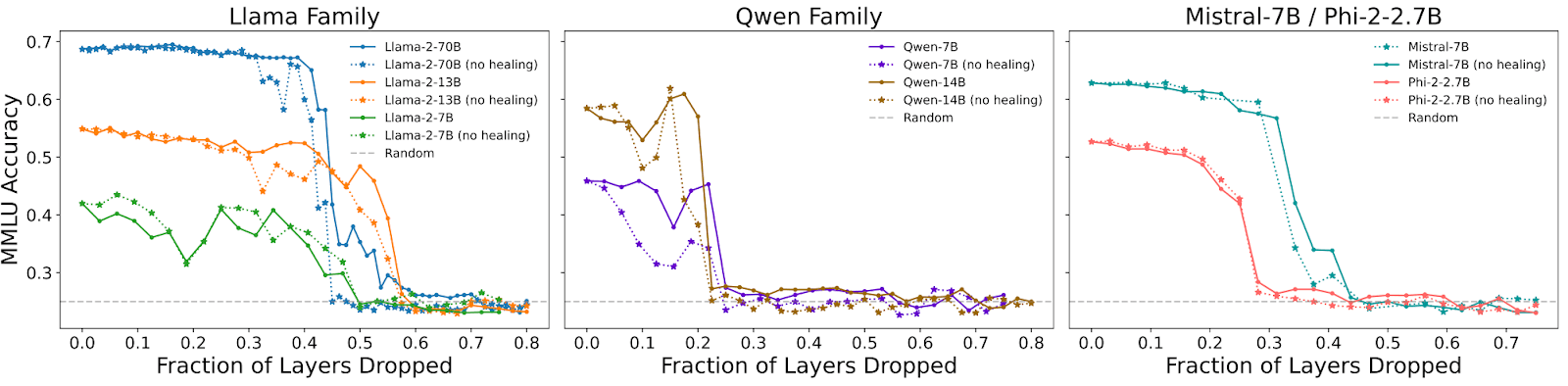
The figure below illustrates the similarity measure across blocks of layers in different models:
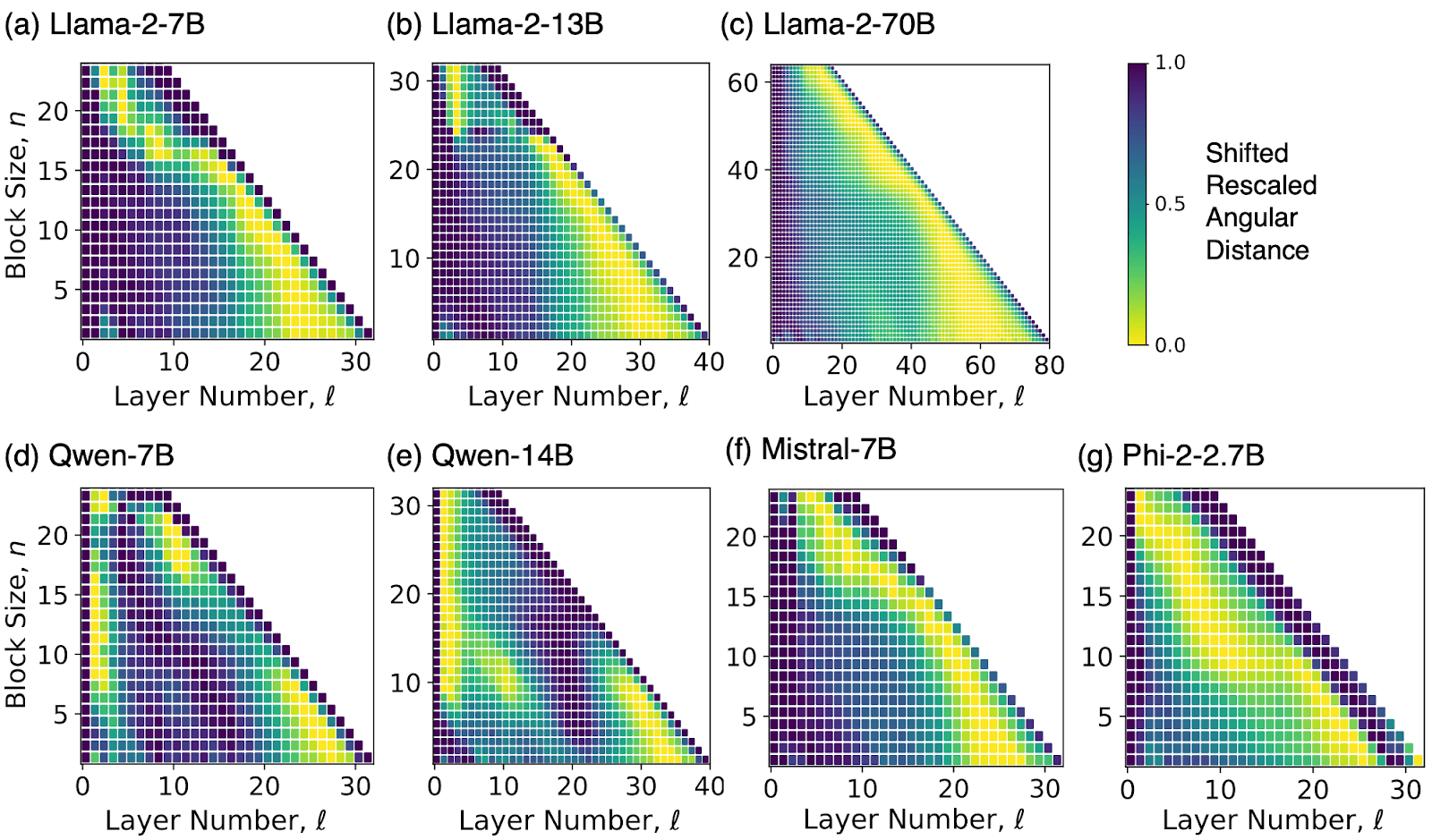
where the \(x\)-axis denotes the first layer to be dropped, \(\ell\), and the \(y\)-axis denotes the block size \(n\). This figure broadly suggests that: (i) the smallest distances are found across the deeper blocks, meaning deeper layers are typically quite similar to each other and can be more easily dropped; (ii) the distances across the deepest blocks – the blocks that include the last layer – take either maximal or nearly-maximal values, meaning one should never drop the final layer.
Conclusions
Pruning is an effective technique for reducing both the memory footprint and latency in large language models (LLMs). Notably, in our approach, latency reduction scales linearly with the number of layers pruned. From an interpretability standpoint, the robustness of models to the removal of deeper layers in downstream tasks suggests that the shallower layers might play a crucial role in retaining core knowledge. Moreover, post-training optimization methods such as pruning, quantization, and speculative decoding operate independently of each other, indicating that combining these techniques could yield significant benefits in further reducing overhead.