
Research
Palo Alto, California
Zyphra is excited to announce Tree Attention, a novel method for efficiently parallelizing multi-GPU transformer decoding with significant advantages in speed and memory. For instance, we estimate that Tree Attention can decode at the 1M sequence length over 8x faster than existing Ring Attention while requiring 2x less communication volume or more. Moreover, Tree Attention achieves an asymptotic advantage over Ring Attention in the number of devices so the benefit increases dramatically for larger clusters.
Vasudev Shyam, Jonathan Pilault, Emily Shepperd, Quentin Anthony, Beren Millidge
Introduction
There has been a recent surge in the context length of large-scale LLM models which has enabled contexts to expand from 8K to 128K to over 1M in length. Such long contexts enable qualitatively new capabilities such as holding entire textbooks or datasets ‘in memory’, supercharging in-context learning, and enabling novel modalities such as native video understanding.
However, due to the quadratic complexity of attention, naively computing long contexts is extremely compute and memory intensive. Memory especially becomes a major bottleneck because of the need to store a KV cache which grows linearly with the context size. Due to the limited GPU VRAM available, long contexts require splitting the KV cache, and hence attention computation, across multiple GPUs. Existing methods to achieve this, such as Ring Attention, shard the KV cache across devices and compute attention on their local KV cache shard, and then pass the results to neighboring devices in a ring.
Design
Tree Attention instead cleverly parallelizes the core decoding computation, allowing the reduction across devices to occur in a tree pattern, using logarithmic instead of linear time, and with less communication overhead. Tree attention is simple to implement in only a few lines of Jax using only existing Jax and NCCL primitives.
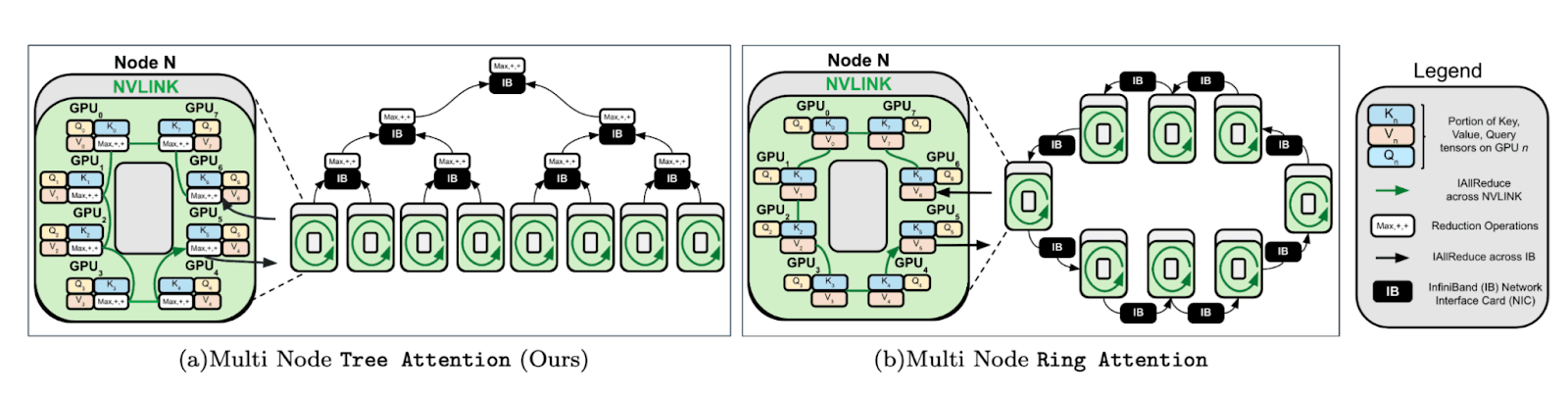
Tree Attention originated with our attempts to understand the energy function of self-attention. Self-attention has been linked to Hopfield Networks and other associative memory networks, which are defined through a mathematical object called an energy function which defines the ‘goodness’ of different configurations of the internal state of the network. Prior work has been unable to fully formulate an energy function for self-attention, instead changing the operation slightly or requiring the tying of the K and V weights. We derive the first correct energy function for self-attention which clarifies the links between transformers, Hopfield Networks, and Bayesian Inference.
Examining our energy function, we noticed that core operations – the reduction of the logsumexp and max across the sequence axis – is associative. This means that this reduction can be computed in parallel using an associative scan (a tree reduction for decoding), similar to state-space models. A core insight in the field of automatic differentiation is that if a function can be computed efficiently, so can its gradient. Since the gradient of our energy function is the self-attention operation, given we can compute the energy function in an efficient parallelizable way, we must also be able to compute self-attention itself in an equally efficient manner. We call this algorithm Tree Attention.
In the accompanying paper we show that Tree Attention achieves a complexity logarithmic in the number of devices instead of linear like Ring Attention. This means that Tree Attention achieves an asymptotic complexity improvement over existing methods. Moreover, we explicitly calculate memory usage and communication volumes and can show that these are significantly smaller for tree than ring attention.
Results
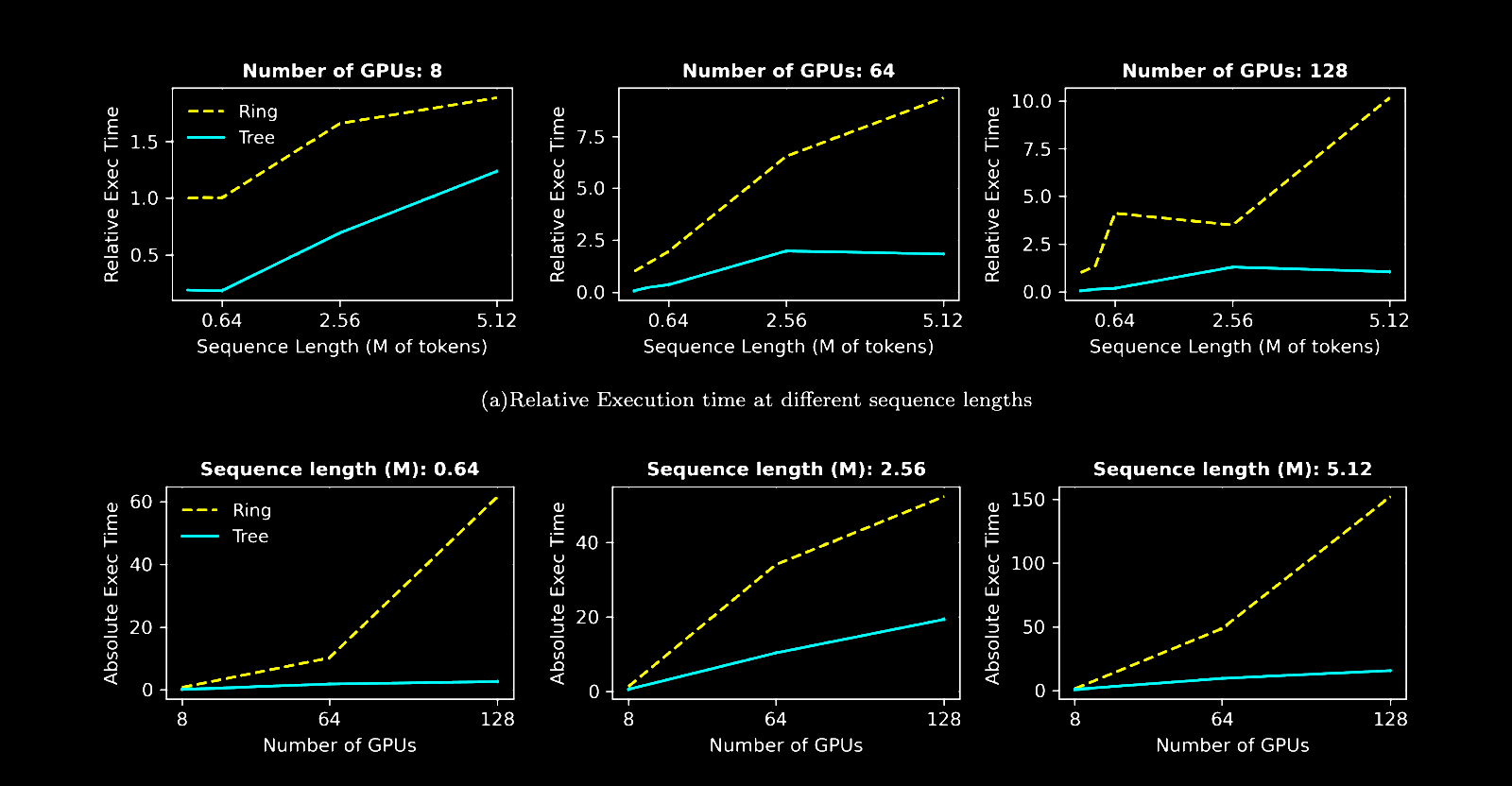
While it has compelling theoretical properties, we also demonstrate empirically that our Tree Attention algorithm significantly outperforms Ring Attention. We time decoding latency computation for both tree and ring attention and show that as both the sequence length and the number of GPUs grow, that tree attention significantly and asymptotically outperforms ring attention, confirming our theoretical results.
We also explicitly measured peak memory usage of tree vs ring attention. Again, we observe that the theoretical benefits of tree attention are borne out in practice.
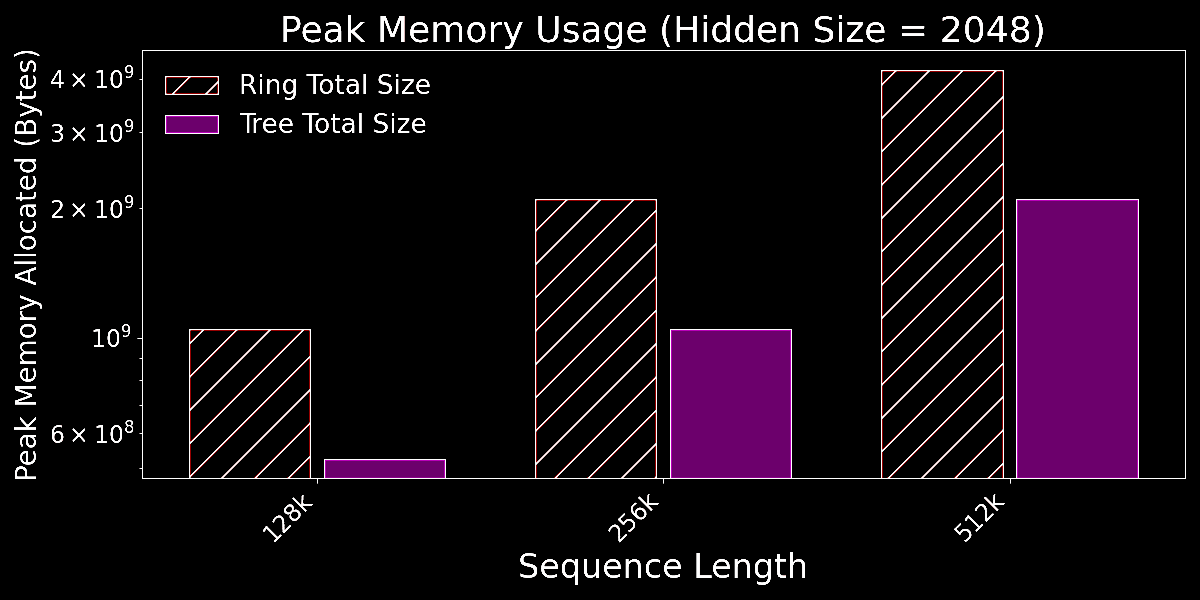
The reduced peak memory requirements of tree attention are a consequence of the algorithm requiring significantly lower communication volume compared to ring attention. Ring attention communicates keys and values for the whole chunk of the sequence present on any device whereas the tree decoding algorithm requires the communication of partially reduced results that do not scale with the sequence length but rather with only the hidden dimension of the model. This enables relatively significant gains in latency even for a relatively small number of devices.
Conclusion
Overall, our tree attention algorithm offers compelling speedups over existing methods such as ring attention, enabling the efficient generation from extremely long context lengths and substantially improving the performance of generating on a fixed hardware budget.