
Research
Palo Alto
This blog post discusses the relation between multi-hop question-answering and retrieval from graph-based databases. In particular, we develop a mathematical explanation for why graph databases are useful for answering multi-hop questions. We then implement a simple graph database to augment GPT-4o. We test our RAG system on a new needle-in-the-haystack dataset, called Babilong, and find our system is the best performing model thus far among models not fine-tuned on the dataset.
Nick Alonso, Beren Millidge
Introduction
Retrieval augmented generation (RAG) systems that use graph databases are becoming increasingly common in research and commercial applications. Graph databases represent properties of text chunks but also relations between text chunks in the database.
Although there is often an acknowledgement in the language modeling community that graph-based retrieval has advantages over more standard vector database techniques, there is a lack of rigorous explanations of what specifically these advantages are and why these advantages exist.
In this post, we discuss and illustrate the usefulness of graph-based RAG systems for multi-hop Question-Answering (QA) tasks. Multi-hop questions are those that require a chain of multiple retrieval steps to answer. We first describe multi-hop questions in more detail and then we:
develop a mathematical explanation for why graph-based retrieval systems can solve multi-hop queries that simple vector database retrieval systems cannot.
We implement a graph-based RAG system and prove its effectiveness by obtaining SoTA results (for non-fine-tuned models) on a recent needle-in-the haystack dataset including outperforming frontier long-context models.
What is a Multi-Hop Question?
Imagine we have a text database that consists of text chunks, and we want a language model to perform a question-answering task, which requires answering questions based on what is written in these texts.
Single hop questions require one retrieval step. For example, the question “Where did Michael Phelps get his undergraduate degree?” can be answered with a single retrieval step: retrieve all chunks related to Michael Phelps, and the answer (University of Michigan) should be contained in at least one of the retrieved items (for instance, a wikipedia page).
Multi-hop questions require multiple retrieval steps. For example, consider the question “Where did the most decorated Olympian of all time get their undergraduate degree?”. There is no guarantee that a model will retrieve the relevant chunks in a single step. To reliably answer this question correctly, two retrieval steps must be performed: First, retrieve documents related to ‘most decorated Olympian of all time’, which should link to Michael Phelps. Then retrieve documents related to Michael Phelps. This is why this is a multi-hop question: in order to reliably get the correct answer, we have to answer multiple single-hop questions, each requiring one retrieval step. Multi-hop questions thus require some degree of sequential reasoning over intermediate information, as opposed to all information being accessible from the beginning.
For a formal description of multi-hop questions see [1].
Graph-based RAG Implicity Performs Multi-Hop Retrieval
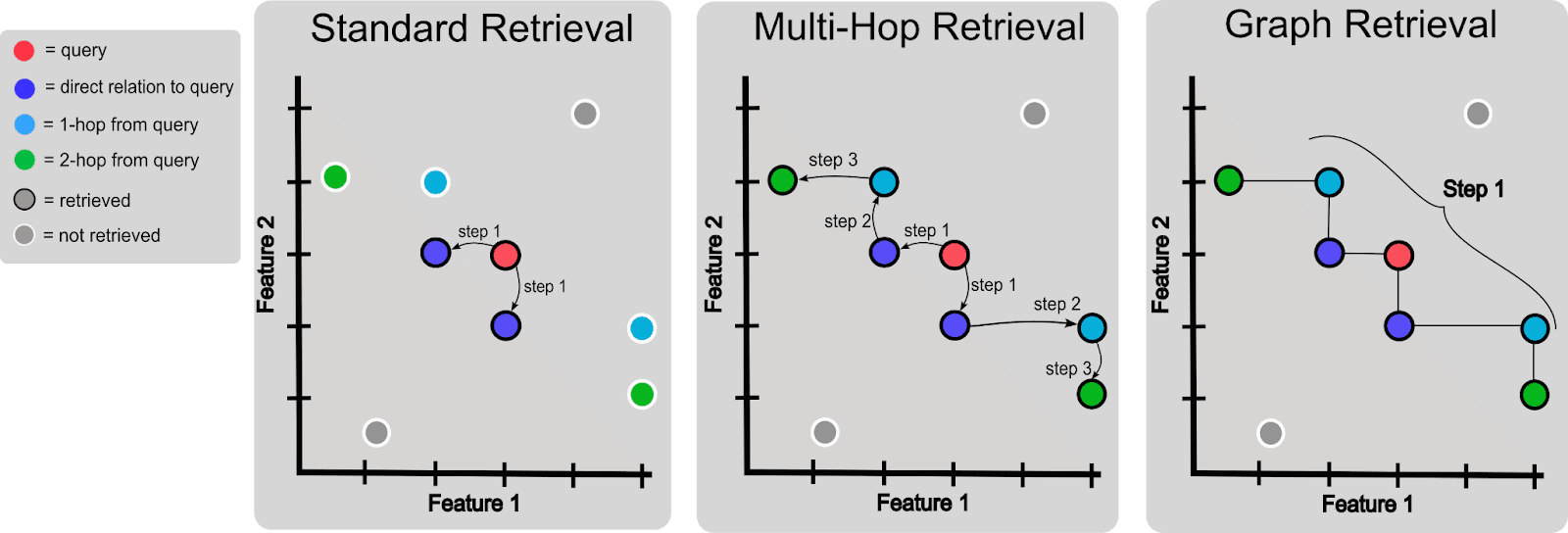
A simplified visualization of several retrieval methods. We visualize relatedness of query and items in a database (i.e., text chunks) as feature sharing (e.g., sharing of keywords or semantic features). In standard retrieval, a single retrieval step is performed where items directly related to (share a feature with) the query are retrieved (dark blue nodes). Multi-hop retrieval algorithms will first retrieve directly related items, then will retrieve items related to those retrieved items (light blue nodes), and so on. Graph retrieval algorithms can do this in a single step, by explicitly representing that items are related using an adjacency matrix, prior to retrieval, then use this adjacency matrix to retrieve directly (dark blue) and indirectly related (light blue and green) items in one step.
Recent SoTA results have been achieved on widely used Multi-hop QA benchmarks using RAG systems with graph structured databases (e.g., [2]). Why these graph databases provide a useful solution to multi-hop questions is not immediately obvious, since these systems are not explicitly doing multiple retrieval steps. Although there do exist intuitive, mechanistic explanations for why these recent graph-based-retrieval RAG systems perform well on multi-hop QA (see [2]), we have had a hard time finding a more precise, formal explanation. Here we provide some mathematical intuition for why graph-based retrieval is useful for multi-hop questions.
Standard RAG systems store text chunks using vector databases. Each text chunk is represented with a ‘key’ vector. Often these vectors are stored in a matrix \(K\), where each column stores one vector. At test time, documents are retrieved by mapping a query to a vector, \(q\), which is compared to all vectors in \(K\). If we use the common dot-product comparison, we can get the relevance of each document, \(r\), using a vector-matrix multiply: \(r = \sigma(K^{\top} q)\), where \(\sigma\) is a non-linearity (e.g., top-\(k\)).
Graph-based RAG systems also store a graph representing the relationships between text chunks in the database. For example, [2] represents weighted graph edges using the dot product between each chunk’s embedding vector. During retrieval, nodes/text chunks will be indexed by the first retrieval step (e.g., using \(r\) from the equation above) then nodes/text chunks related to these root nodes by the graph edges will also be retrieved. There are different ways to perform this retrieval step. We discuss two options in the next section.
We can do the equivalent of a multi-hop retrieval by stringing together multiple retrieval steps using a standard (non-graph) database. For example, let \(\sigma\) be a top-1 retrieval. Here is how to do three-hop retrieval:
\[r_{3-hop} = \sigma(K^{\top} K \sigma(K^{\top}K \sigma(K^{\top} q)))\]
At each step, we retrieve the top-1 key vector and then use this as the query vector for the next retrieval step. Instead of top-1 retrieval, we could also do a kind of tree-search, where we retrieve multiple keys each iteration, and following the branching paths, collecting multiple chunks each iteration, which is exactly what high performing multi-hop retrieval algorithms do (e.g., [3]).
Notice that \(K^{\top} K\) shows up multiple times in the equation above. This matrix, interestingly, stores the similarity values between each pair of keys. This matrix can be interpreted as a weighted adjacency matrix of a graph, where each key index represents a node and the similarity value between two keys represents the weight of the connections between the associated nodes.
Let’s consider a graph with an adjacency matrix \(A = K^{\top} K\). Rewriting the equation above with this new notation, we have
\[r_{3-hop} = \sigma(A \sigma(A \sigma(K^{\top} q)))\]
We can see this is a traversal on a graph where the starting nodes are set by the first operation, \(\sigma(K^{\top} q)\). Very similar sets of operations are involved in SOTA graph-based RAG systems, which set the graph edges based on the similarity between the keys (e.g., [2]). Thus, graph-based RAG systems like these implicitly perform operations equivalent to explicit multi-hop retrieval, helping explain why we see such methods perform well on multi-hop retrieval.
Topping the Babilong Leaderboard with a Graph-RAG System
We will now illustrate the usefulness of graph based RAG systems on a challenging benchmark dataset with multi-hop questions. In particular, we design a graph database that achieves promising results on a new question-answering task, called the Babilong benchmark [4]. Among models that are not fine-tuned specifically on Babilong, ours tops the leaderboard.
The Babilong benchmark is a new needle-in-the-haystack test. Needle-in-the-haystack tests involve answering questions which only refer to a small chunk of text embedded in a much larger document of irrelevant text. The difficulty in these tasks is getting the model to find and respond using the relevant text chunk, while ignoring the large amount of irrelevant text/noise that surrounds the relevant text chunk.
The Babilong dataset is hard: SoTA long context models, like GPT-4, struggle on the benchmark, and the baseline RAG systems tested thus far on the benchmark have failed. Only non-standard language model architectures that use recurrent neural networks, fine-tuned specifically for this narrow task, have done well thus far.
However, below we show that graph-based RAG models, which have yet to be tested on this benchmark, with simple improvements to prompting, perform very well. We show that the reason for this is that the harder questions on the benchmark are multi-hop questions, which can be readily answered using graph-based retrieval. Moreover, our approach does not require finetuning and thus can work with any base model while retaining its full LLM capabilities unlike models fine-tuned for this specific task which cannot perform general language modeling well.
The Dataset
The Babilong dataset consists of three texts per question. First, is the question.such as , ‘Where is the football?’, ‘What room is east of the kitchen?’. Secondly there are support sentences, which are sentences that are directly or indirectly required to answer the question, e.g. “Daniel picked up the football. Daniel went to the kitchen”. These are pulled from the bAbl QA dataset [5]. Finally, there is filler text. This text is irrelevant to the question (i.e., noise) and is used to add filler text between each support sentence. Models are tested under different amounts of filler text, measured in amount of added tokens (e.g., 0k, 8k, etc.). Filler text is pulled from the PG19 dataset [6].
There are five question types used in the benchmark, with 100 questions per type. Each question type requires a different number of supporting sentences to answer. Question types 1, 4 and 5 only require knowledge of one supporting sentence. While 2 and 3 require 2-3 supporting sentences.
Fixing the Prompting Issue
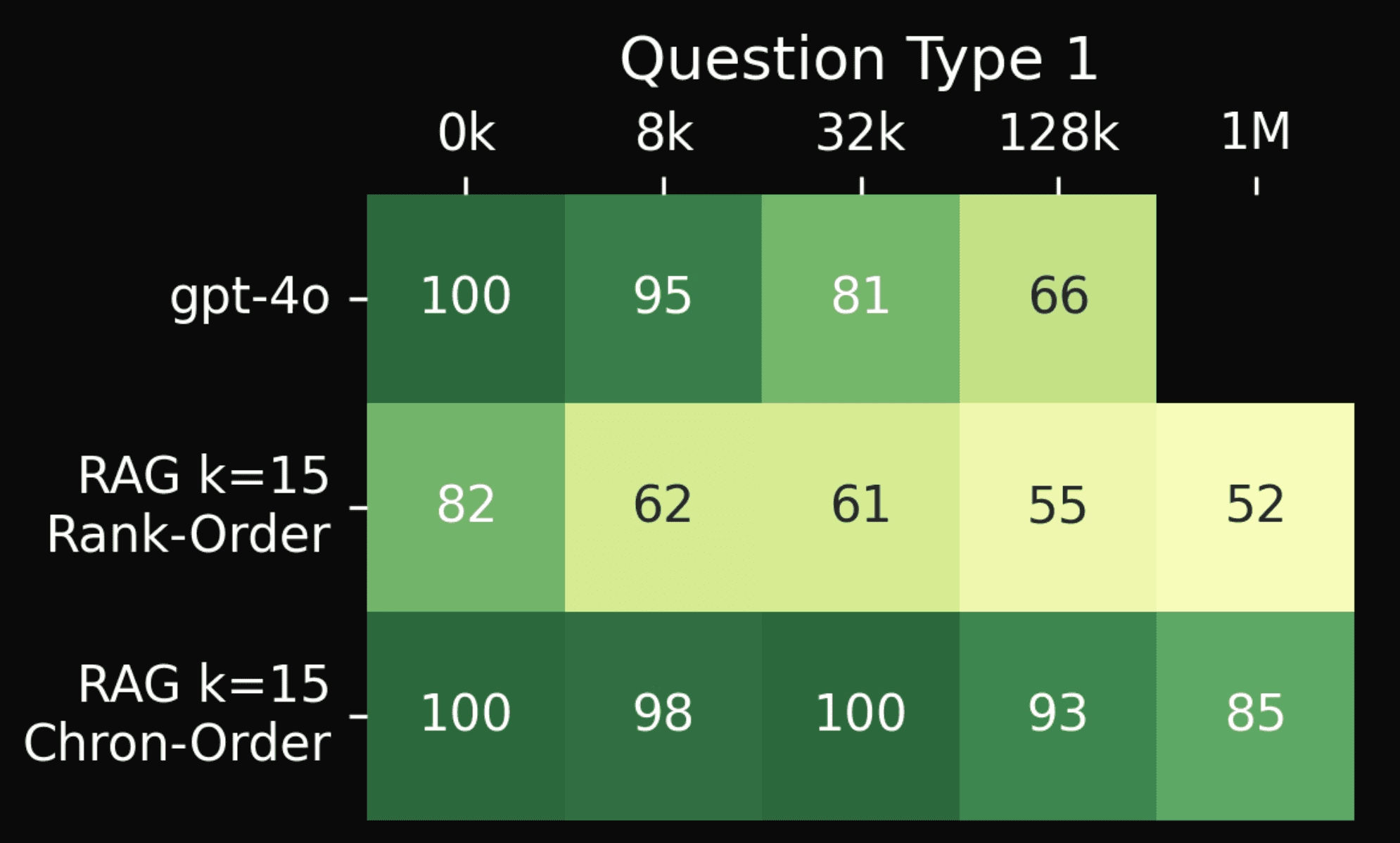
Test on question type 1. X-axis amount of added irrelevant text. Y-axis: model type. GPT-4o is the long-context baseline. RAG systems with chronologically ordered text chunks and rank ordered chunks tested on question types 2-5 with 0k and 8k irrelevant tokens added per question. The numbers represent the percentage of the question type answered correctly.
As a baseline, we test GPT-4o without RAG, using only its long context abilities. GPT-4o has a context length of 128k tokens. Each question is presented with a given document of support sentences surrounded by different amounts of irrelevant text. We test at 0k, 8k, 32k, 128k, and 1M added irrelevant tokens. For the GPT-4o baseline, the entire document is placed in the context. Since GPT-4o’s maximum context length is 128k tokens, we cannot run this baseline in the 1M context condition.
We begin by testing simple LLMs with RAG. These RAG systems use FAISS to create a vector database index. Dense vectors are created for each text chunk using the SoTA BERT based semantic embedder ‘Alibaba-NLP/gte-large-en-v1.5’. GPT-4o is used as the base language model. Following the best performing RAG baseline, we chunk text by sentences.
In the plot above, we test a simple alteration to the original baseline RAG systems that have been tested thus far on Babilong. These original RAG baselines tested on Babilong thus far order sentences by retrieval rank (higher the rank, closer the chunk is to the end of the prompt). However, it is clear that sentences must be presented in chronological order rather than rank order, since answering questions like ‘Where is the milk?’ requires knowing the order of events that changed the location of the milk.
We test both ordering methods on question type one with retrieval number set to 15 (top 15 sentences are retrieved from the document, around several hundred tokens). Similar to the original Babilong paper, we find the rank order method performs poorly. However, we find that chronological ordering dramatically improves performance on question type one, which goes from achieving between 52-82% accuracy to 85-100% accuracy.
Dealing with Multi-Hop Questions
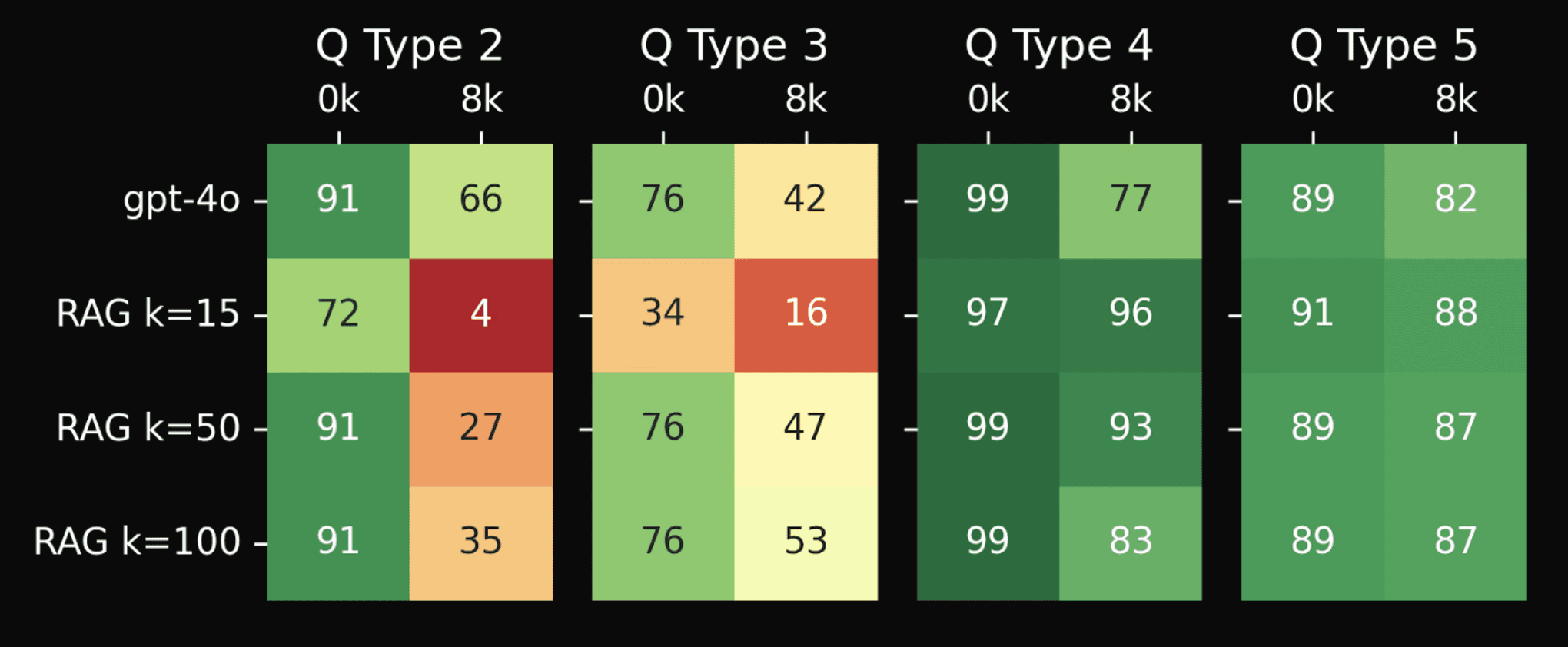
Simple RAG systems, with chronologically ordered text chunks, tested on question types 2-5 with 0k and 8k irrelevant tokens added per question. ‘RAG k=N’ means the N top scoring text chunks/sentences by similarity are retrieved and fed into the model.
However, simply chronologically ordering the sentences does not fix performance on question types 2 and 3, which we can see in the table above. In the table, we show results for a simple RAG system with various top-k settings and see that, even at only 8k document length, the RAG models fail on question types 2 and 3.
So why is RAG failing these questions? If we look more closely, we find it is because these are multi-hop questions, which cannot be answered with the single-hop retrieval of normal RAG.
For instance, an example of a type 2 question is ‘Where is the football?’ The difficulty is that no sentence in the supporting text alone explicitly states where the football is. Here are the relevant support sentences, (which are surrounded by large amounts of irrelevant text).
“...Daniel grabbed the football there…Daniel went to the kitchen.”
To answer the question, “Where is the football?”, the model must reason over two text chunks/sentences, not one, and only one sentence is directly related to the question (only one mentions ‘football’). This means it is highly unlikely that the second key sentence: ‘Daniel went to the kitchen’ would be retrieved given a query about the football. This is a clear example of a question that requires multiple hops: To answer the full question, first, we must answer “who had the football last?”, then we must answer “where did they last have the football?”
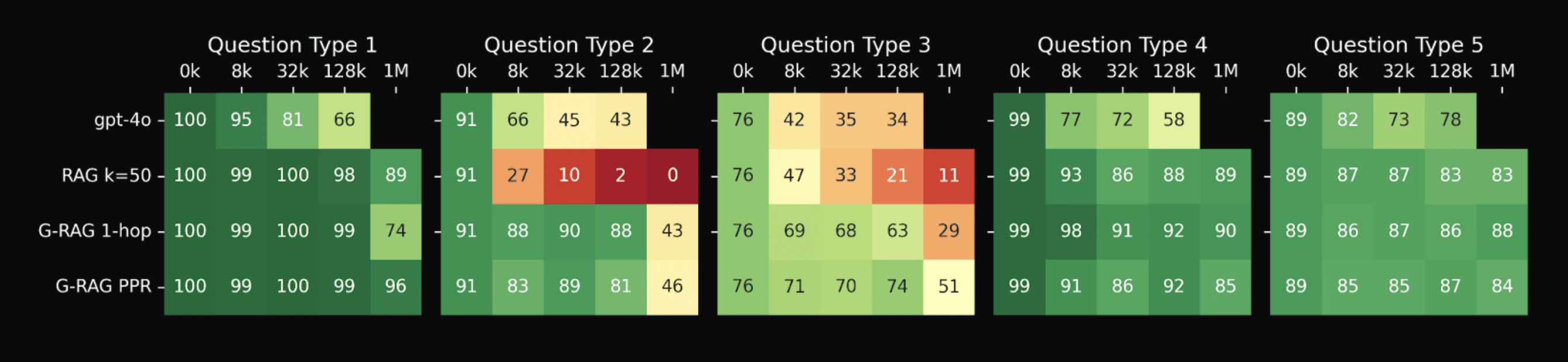
Simple RAG system compared to graph-based RAG systems tested on question types 1-5 with 0k through 1M irrelevant tokens added per question.
To improve performance on multi-hop questions, we created a simple graph-based RAG system. For each question, we create a weighted adjacency matrix that is the average of two matrices. First, we create a proximity matrix representing the cosine similarity between each sentences’ embedding vector and every other embedding vector. Second, we create a binary matrix representing whether or not two sentences share at least one keyword or not. Keywords are defined as nouns and named entities. Combining semantic search with keyword search has been found in studies to often improve performance over either method alone [7], which motivated us to combine them here.
Two retrieval mechanisms are tested:
First, we retrieve all chunks that have similarity >0.4 to the query and all nodes that are 1-hop from these nodes (G-RAG 1-hop). Duplicates are removed and chunks are ordered chronologically.
Second, we utilize personalized page rank (PPR) [8], the retrieval ranking algorithm on which Google search was originally based. Getting into the details of PPR is outside the scope of this post, but suffice to say that the way PPR ranks nodes is based on the initial distribution, which we set using the similarity values to the query, and distance from these initial nodes on the graph, as well as the structure of the graph itself (G-RAG PPR).
We can see in the table above, that the graph-based RAG models greatly outperform standard RAG on question 2 and 3, while matching on the remaining questions. G-RAG PPR performs slightly better at the 1M document length than the 1-hop model. Interestingly, our RAG models often perform significantly better than the pure long context gpt4o model despite the gpt4o model having direct access in its context to all the information needed to answer the questions (up to document length of 128k). We believe this is because the large amount of irrelevant information can distract the long context model, while RAG removes the majority of this irrelevant text from the context, letting the model reason over primarily relevant information. It may also reflect a weakness in the context length extension methods currently published in the literature and which appear to be used by frontier labs which primarily interpolate the position embeddings and then perform a small finetuning on long context data, which may result in significantly weaker representations and capacity at long contexts than pretraining at these contexts from scratch.
Comparing to the Leaderboard
How does our graph-based RAG model compare to SoTA results? In the tables below, we compare the top models from the Huggingface leaderboard [9] (as of 8/20/2024) to our Graph-based RAG PPR model. The best performing models, at the time of this post, are based on the recurrent neural networks fine-tuned to the Babilong dataset. First, the RMT [10] is a transformer model that encodes a set of memory embeddings that act as a hidden state that is recurrently updated for each provided text chunk. RMT-retrieval is a variant that also has long-term memory embeddings, retrieved from a store of long-term memory vectors [11]. ARMT is a variant of RMT with a long-term associative memory mechanism. ARMT has yet to be described in a publication. Mamba [11] is a state space model. Pretrained Mamba performs poorly, but when fine-tuned (Mamba-ft) on Babilong, the model does well. All RMT and Mamba models are fine-tuned exclusively on the Babilong dataset and have not been proven to be capable general language models.
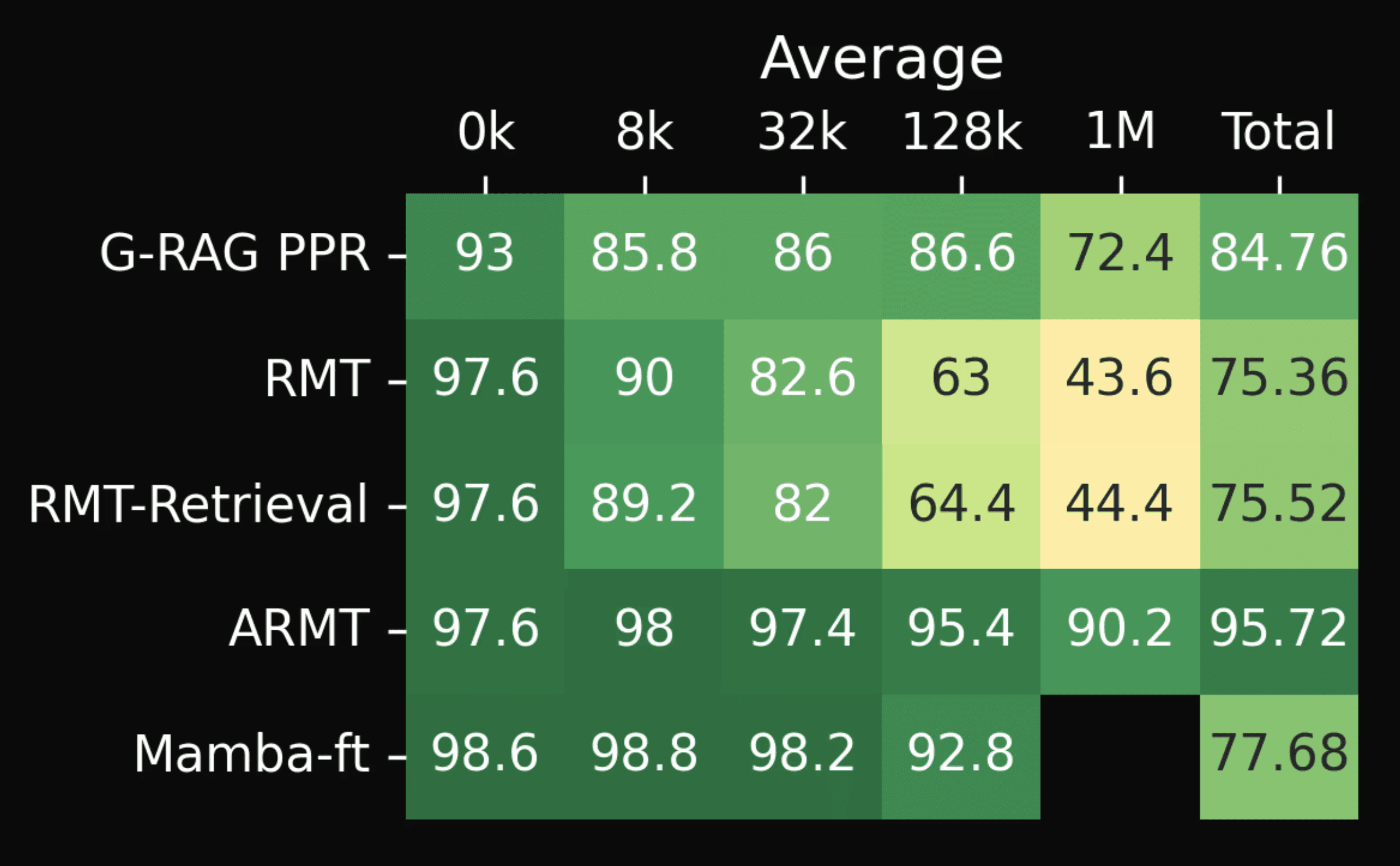
Comparison of graph-based RAG with personalized page rank to RMT and Mamba models fine-tuned for Babilong. Columns 0k through 1M show scores averaged across question types. The ‘Total’ column is averaged across question types and irrelevant text length. Scores for RMT and Mamba models are pulled from the current Huggingface leaderboard.
G-RAG PPR performs closely to RMT and RMT-retrieval at shorter document lengths, while outperforming them at longer document lengths. Mamba-ft performs very well but cannot support context past 1M tokens due to, what the Babilong authors say, are OOM errors. ARMT still tops the leaderboard, essentially solving the Babilong benchmark.
It is important to emphasize, however, that the RMT models and Mamba are finetuned only on the Babilong dataset, and thus are unlikely to be useful general language models. G-RAG PPR should perform well on most QA tasks, since RAG using PPR has shown to be highly effective on other QA datasets, while retaining the general usefulness of the original language model whose parameters are untouched. If we average across all questions and text lengths (the ‘Total’ column in the table above), we find that of all of the models on the leaderboard that do not fine-tune parameters, our G-RAG PPR model performs the best. For the scores of other non-finetuned models, see [9].
However, it should be noted that we, due to compute limitations, did not test at the longest length of 10 million tokens. In the future, we aim to make our graph database cheap enough to generate so we can test on these ultra-long documents.
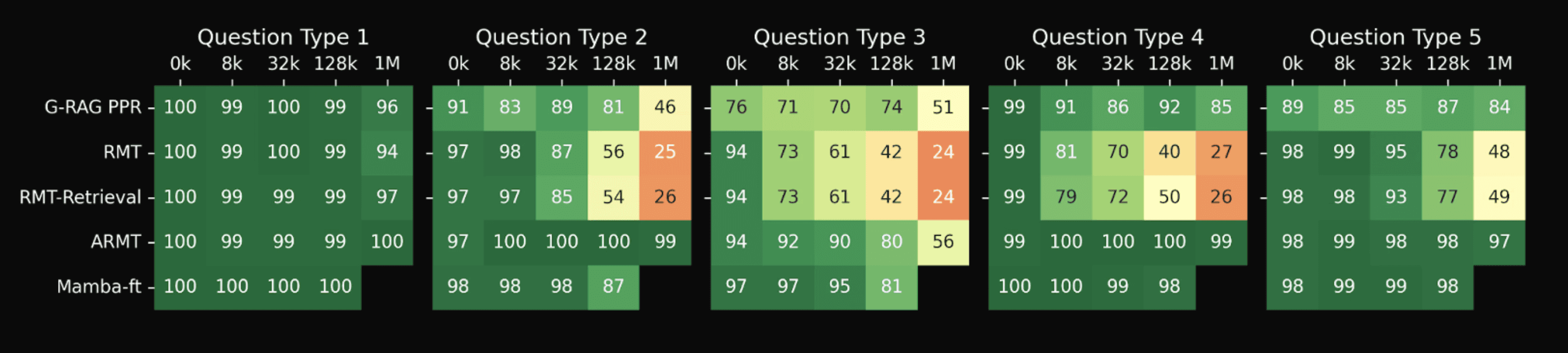
Detailed comparison of our graph-based RAG w/ personalized page rank to models fine-tuned for Babilong.
The Cost of Long-Context versus RAG
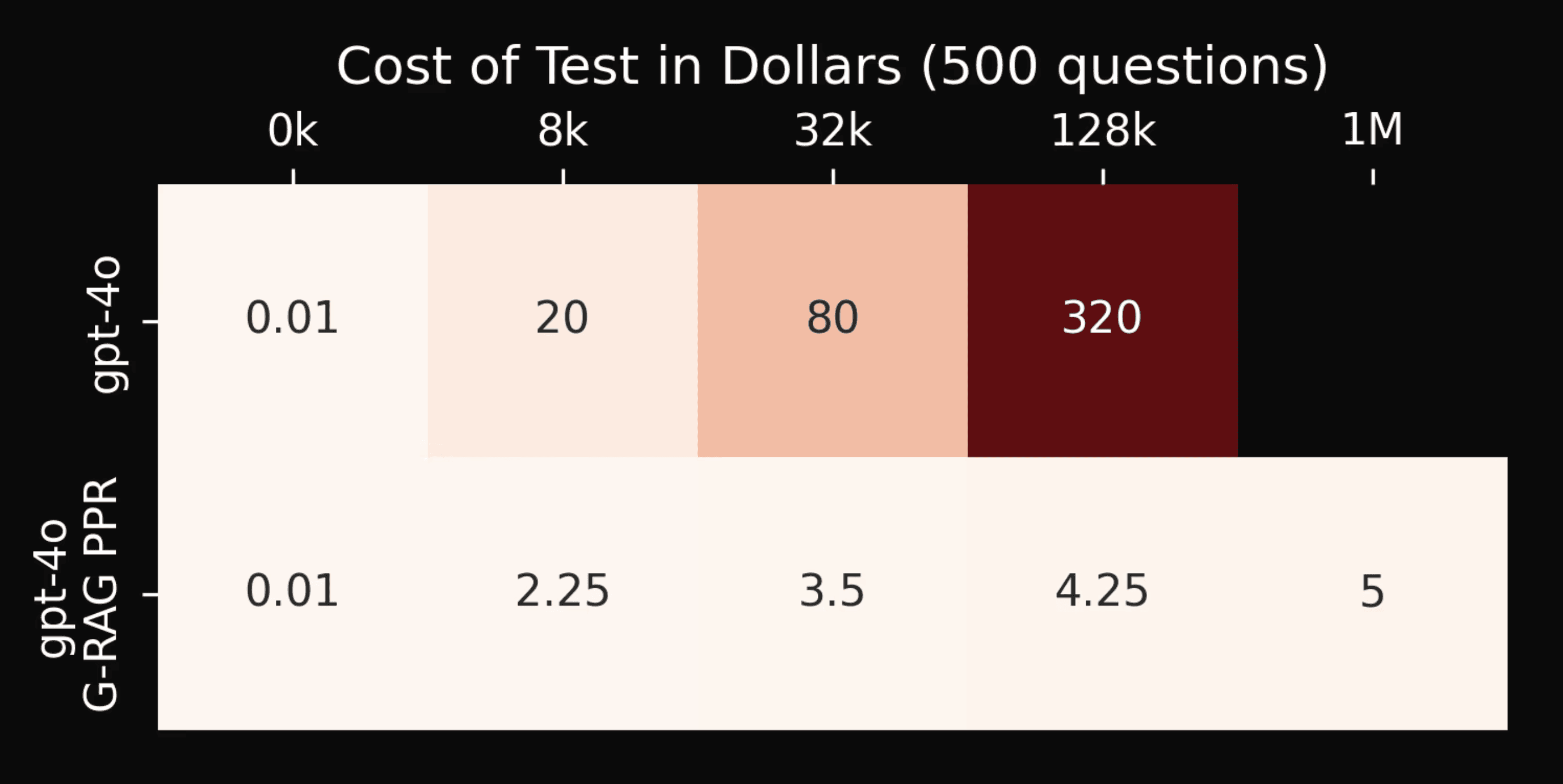
It is worth noting that it was much cheaper to run our RAG models with GPT-4o on Babilong than it was to run GPT-4o with a full context. We provide a rough estimate of the cost in the table above (in U.S. dollars). Our RAG systems only need to retrieve a small subset of text from the document, drastically reducing cost for long documents, since API calls are charged per input and output token. Thus, on QA tasks like Babilong, there is a clear cost advantage (over 75x cheaper) for our RAG systems over relying on long-context abilities of LLMs in addition to our RAG system’s performance advantages.
Conclusion
We mathematically showed graph-based retrieval is implicitly performing multi-hop retrieval and demonstrate that graph-based databases thus provide a principled, simple approach to dealing with multi-hop queries.
We demonstrated that a simple graph based RAG system can significantly improve performance over standard RAG systems on such questions from Babilong, and in doing so, achieved top results on the Babilong benchmark.
We demonstrate that RAG based systems can significantly outperform state-of-the-art long context models in both capability and cost on challenging QA benchmarks.
References
[1] Mavi, V., Jangra, A., & Adam, J. (2024). Multi-hop Question Answering. Foundations and Trends® in Information Retrieval, 17(5), 457-586.
[2] Gutiérrez, B. J., Shu, Y., Gu, Y., Yasunaga, M., & Su, Y. (2024). HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. arXiv preprint arXiv:2405.14831.
[3] Zhang, J., Zhang, H., Zhang, D., Yong, L., & Huang, S. (2024, June). End-to-End Beam Retrieval for Multi-Hop Question Answering. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) (pp. 1718-1731).
[4] Kuratov, Y., Bulatov, A., Anokhin, P., Rodkin, I., Sorokin, D., Sorokin, A., & Burtsev, M. (2024). BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack. arXiv preprint arXiv:2406.10149.
[5] Weston, J., Bordes, A., Chopra, S., Rush, A. M., Van Merriënboer, B., Joulin, A., & Mikolov, T. (2015). Towards ai-complete question answering: A set of prerequisite toy tasks. arXiv preprint arXiv:1502.05698.
[6] Rae, J. W., Potapenko, A., Jayakumar, S. M., & Lillicrap, T. P. (2019). Compressive transformers for long-range sequence modelling. arXiv preprint arXiv:1911.05507.
[7] Bruch, S., Gai, S., & Ingber, A. (2023). An analysis of fusion functions for hybrid retrieval. ACM Transactions on Information Systems, 42(1), 1-35.
[8] Page, L., Brin, S., Motwani, R., & Winograd, T. (1999). The PageRank citation ranking: Bringing order to the web. Stanford infolab.
[9] https://huggingface.co/spaces/RMT-team/babilong
[10] Bulatov, A., Kuratov, Y., & Burtsev, M. (2022). Recurrent memory transformer. Advances in Neural Information Processing Systems, 35, 11079-11091.
[11] Kuratov, Y., Bulatov, A., Anokhin, P., Sorokin, D., Sorokin, A., & Burtsev, M. (2024). In search of needles in a 10m haystack: Recurrent memory finds what llms miss. arXiv preprint arXiv:2402.10790.
[12] Gu, A., & Dao, T. (2023). Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752.