
Model
Palo Alto, California
Zyphra is proud to release Zamba, a novel 7B parameter foundation model.
Paolo Glorioso, Quentin Anthony, Yury Tokpanov, James Whittington, Jonathan Pilault, Adam Ibrahim, Beren Millidge
Zamba's Performance Highlights
Our novel architecture is more compute-efficient during training and inference compared to vanilla transformers, and demonstrates the scalability and performance capabilities of SSMs.
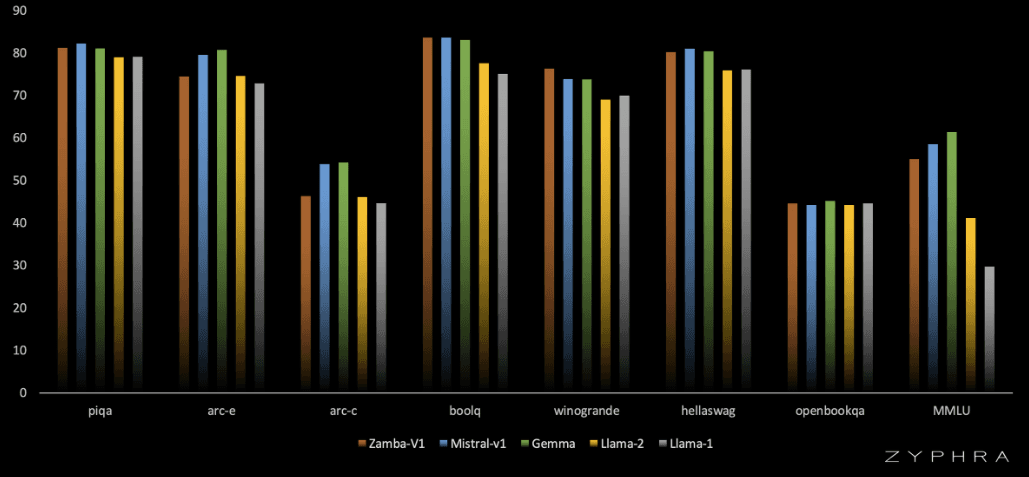
Approaching Mistral and Gemma levels of performance despite being trained on many times fewer tokens, and using open datasets.
Notably outperforms LLaMA-2 7B and OLMo-7B on a wide array of benchmarks despite requiring less than half of the training data.
We performed a two-phase training approach, initially using lower-quality web-data followed by high quality datasets. We release both the fully trained and original base model weights.
All checkpoints across training are provided open-source (Apache 2.0).
Achieved by a small team of 7 people, on 128 H100 GPUs, in 30 days.
Zamba's Architecture
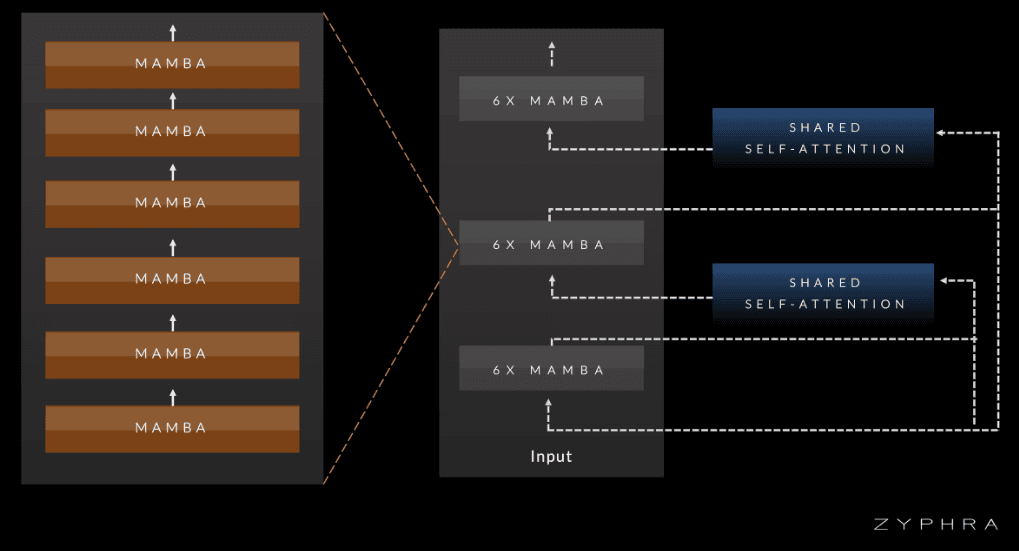
Zamba introduces a novel architecture, which combines Mamba blocks with a global shared attention layer applied every 6 Mamba blocks. This hybrid design allows Zamba to learn long-range dependencies and perform in-context learning more efficiently than conventional mamba models, while reducing the compute overhead during training and inference compared to vanilla transformer models.
While recently there has been much research and excitement around mixture-of-expert (MoE) architectures, which enable large parameter counts while keeping inference flops fixed, for many enthusiasts running LLMs on their local hardware, the key constraint is instead total GPU memory required to load the model parameters rather than the inference cost.
With Zamba, we explore the opposite direction – applying more flops to improve performance while keeping the total parameter count fixed. We achieve this by applying a global memory attention block with shared weights at every N layers to a standard Mamba backbone – we thus demonstrate that attention parameters can be effectively shared across layers while still retaining high performance, enabling an important reduction in the memory footprint of our model. We believe this approach provides a novel and interesting direction for allowing highly performant models to run locally on consumer GPU hardware.
We believe Zamba represents a major step towards developing compact, parameter and inference-efficient models that still outperform larger models trained on more data and with more compute.
Zamba Evals - 7B
Following recent results in the literature, we perform a two-phase training scheme, beginning with standard open web datasets, followed by an annealing phase of rapid decay on high quality tokens. We find that this appears to significantly improve model quality.
We trained on approximately 1 trillion tokens of open web datasets in the first phase, then approximately 50 billion tokens of high quality data in the second phase. We find that our base model after the first phase is highly competitive with Llama2 while after annealing our model is approaching state-of-the-art performance despite training on many times fewer tokens and thus likely using significantly less training flops. Unlike prior work, we release both the base and the final (annealed) model for comparisons.
All checkpoints are released open-source (Apache 2.0). Zyphra believes going beyond open-weights is critical to democratize powerful 7B models, and Zamba is notably the most performant model with open-weights + open-checkpoints by a large margin. We release all training checkpoints open-source as we believe that such artifacts are crucial for enabling interpretability researchers and the broader academic community to investigate training dynamics and model-representation phenomena and ultimately to improve our understanding of large-scale training. We intend to fully document all dataset and training hyperparameters in a forthcoming paper to ensure that Zamba is a fully reproducible research artifact.
Zamba will be released under an open source license, allowing researchers, developers, and companies to leverage its capabilities. We invite the broader AI community to explore Zamba's unique architecture and continue pushing the boundaries of efficient foundation models. A Huggingface integration and a full technical report will be released shortly.
Zyphra's team is committed to democratizing advanced AI systems, exploring novel architectures on the frontier of performance, and advancing the scientific study and understanding of powerful models. We look forward to collaborating with others who share our vision.