
Model
Palo Alto
Zyphra is excited to release Zamba2-mini, a state-of-the-art small language model. Zamba2-mini achieves highly competitive evaluation scores and performance numbers and fits in a tiny memory footprint of <700MB at 4bit quantization. 7x drop in params for same performance ; Zamba2- mini (1.2B) ~ Llama2 7B
Paolo Glorioso, Quentin Anthony, Yury Tokpanov, James Whittington, Jonathan Pilault, Beren Millidge
Zamba2-mini (1.2B) Highlights
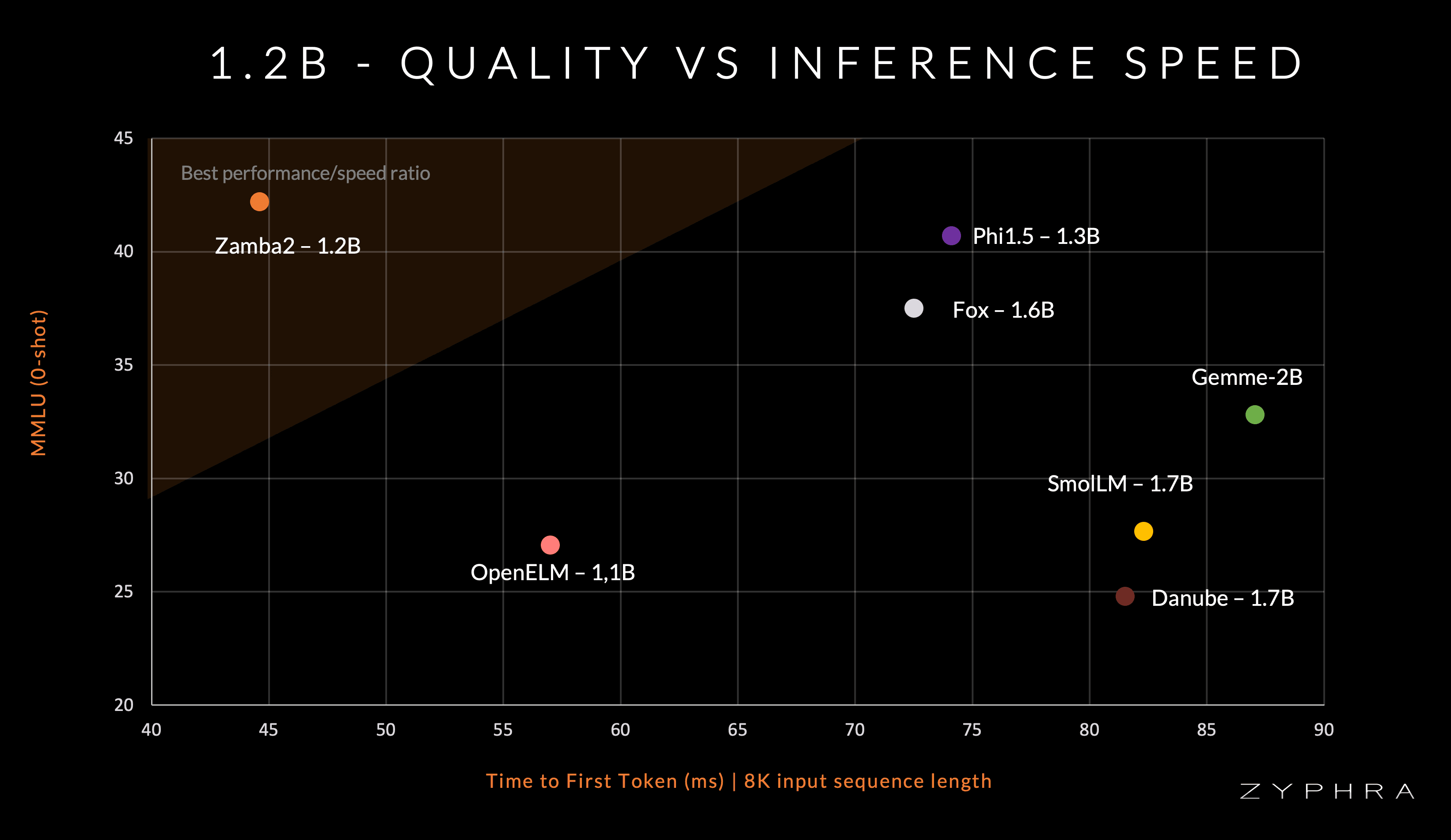
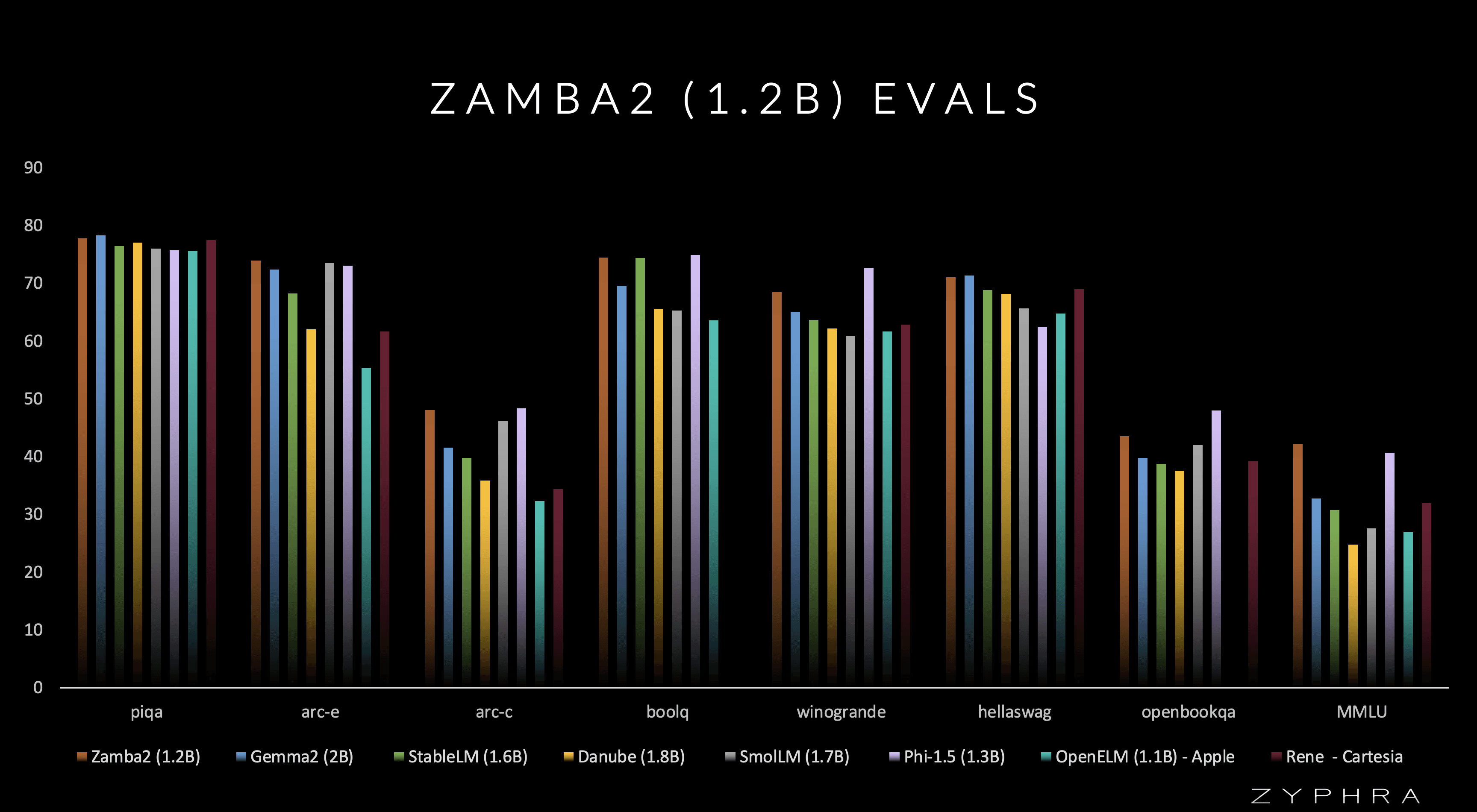
Zamba2-mini achieves SOTA evaluation benchmark performance and superior inference efficiency compared to models of a similar scale and larger such as Gemma-2B (Google), SmolLM-1.7B (Huggingface), OpenELM-1.1B (Apple), StableLM-1.6B (StabilityAI) and Phi-1.5 (Microsoft)
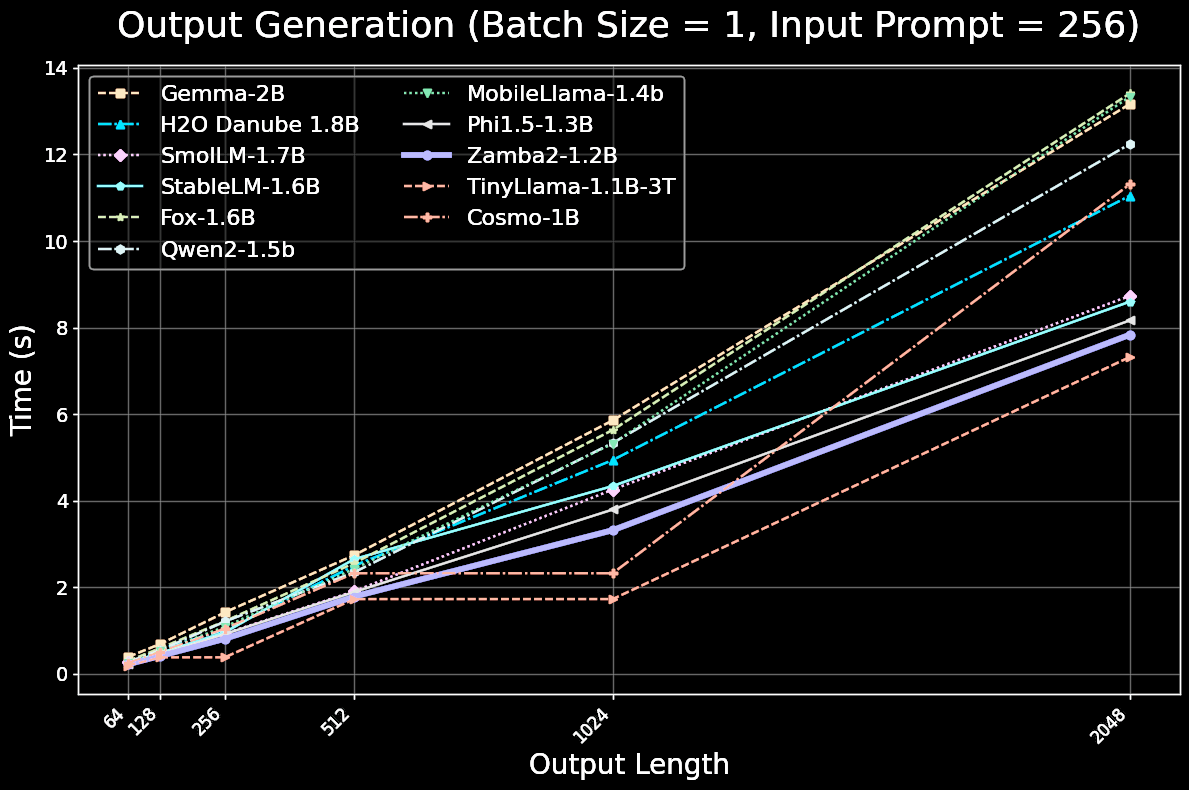
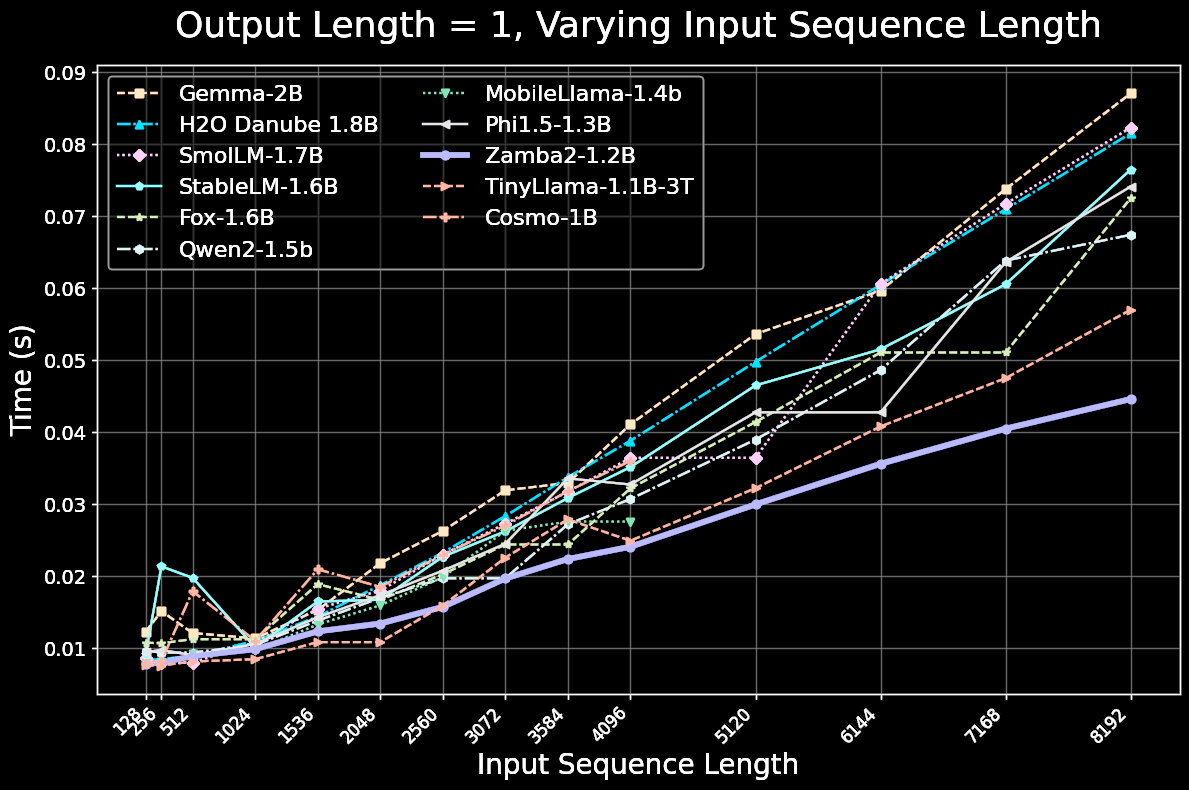
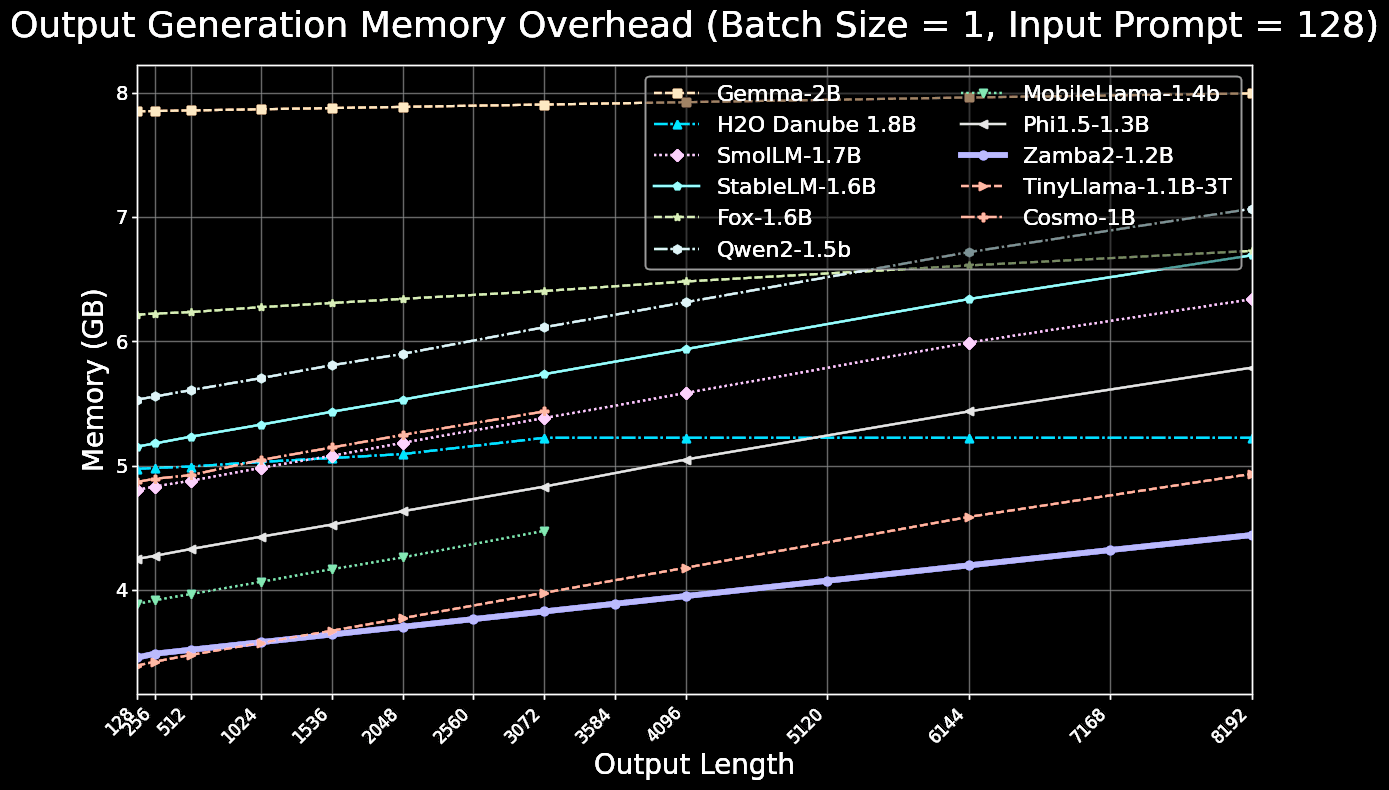
Zamba2-mini is extremely inference-efficient, achieving 1.67x faster time-to-first-token and a 23.3% reduction in memory overhead compared to Phi1.5-1.3B
We release the model weights open-source (Apache 2.0)
Zamba2-mini (1.2B) Efficiency
Zamba2-mini achieves the quality of a 2-3B dense transformer while only requiring the inference compute and memory of a <1B dense transformer. Much of our focus on designing hybrid models is to maintain the best of both worlds (the efficiency of SSM/RNN architectures, and the quality of the transformer architecture). Some of the main contributing factors of our model’s benefits over comparable dense transformers are:
Model Quality:
The shared transformer block allows more parameters to be allocated to the Mamba2 backbone. In turn, the shared transformer block preserves the rich cross-sequence dependencies of the attention computation.
Our 3 trillion token pre-training dataset, which is composed of a combination of Zyda and other openly-available datasets that are extensively filtered and deduplicated.
We have a separate "annealing" pre-training phase, which decays the learning rate over 100B very high-quality tokens.
Inference Efficiency:
Mamba2 blocks are extremely efficient, and have roughly 4 times the throughput of an equal-parameter transformer block.
Mamba blocks only have small hidden states to store and don't require a KV-cache, so we only need to store KV states for the invocations of the shared attention block.
We choose model sizings that are very amenable to parallelization on modern hardware (i.e. multiple streaming multiprocessors on GPUs, multiple cores on CPUs).
Due to these results, we believe Zamba2-mini offers a significant improvement over comparable small language models.
Zamba2-mini (1.2B) Evaluations
Zamba2-mini (1.2B) Inference Performance
Zamba2-mini (1.2B) Architecture
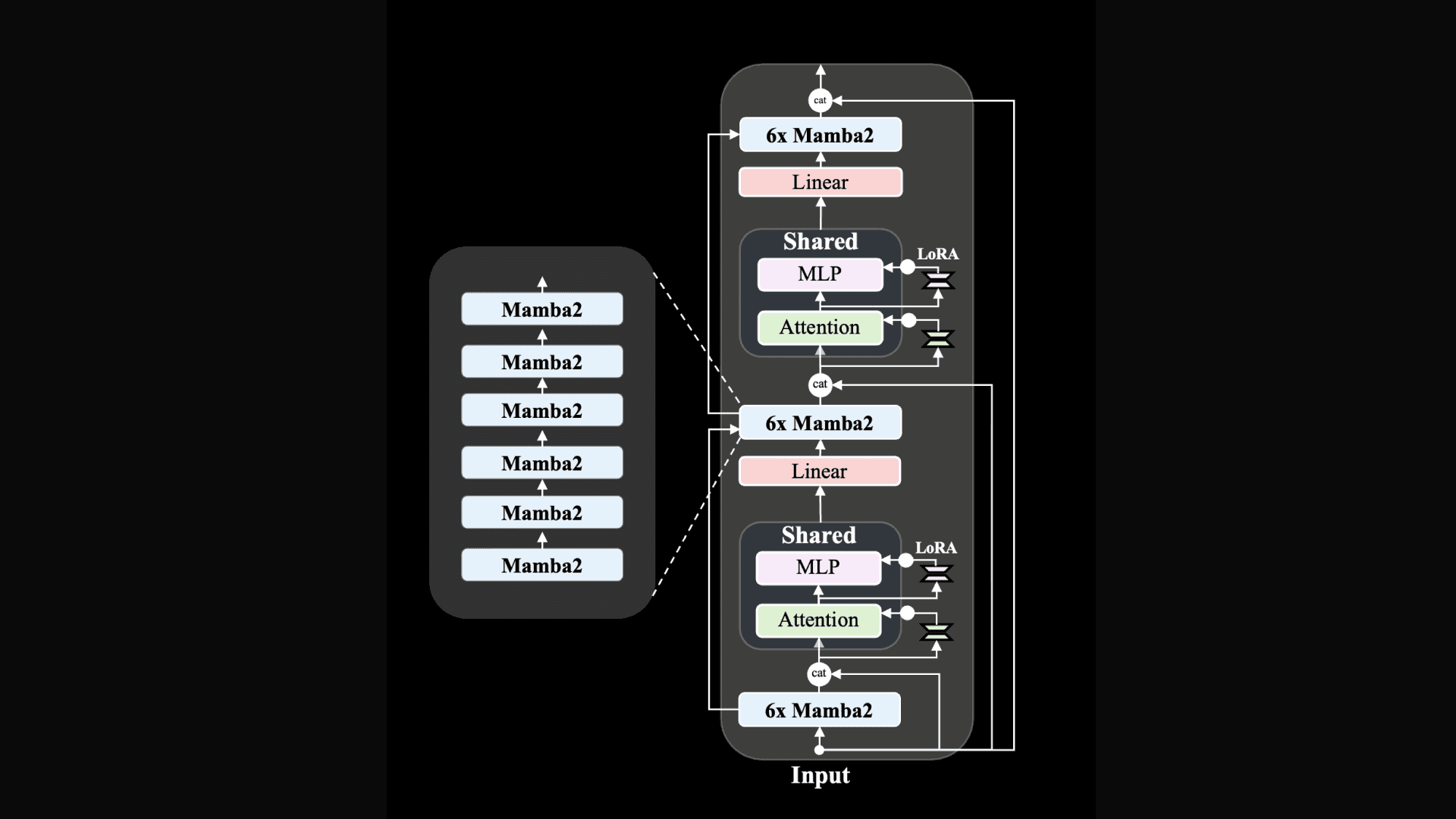
Zamba2-1.2B utilizes and extends our original Zamba hybrid SSM-attention architecture. The core Zamba architecture consists of a backbone of Mamba layers interleaved with one or more shared attention layers (one shared attention in Zamba1, two in Zamba2). This attention has shared weights to minimize the parameter cost of the model. We find that concatenating the original model embeddings to the input to this attention block improves performance, likely due to better maintenance of information across depth. The Zamba2 architecture also applies LoRA projection matrices to the shared attention and MLP blocks to gain some additional expressivity in each block and allow each shared block to specialize slightly to its own unique position while keeping the additional parameter overhead small.
Zamba2-mini makes some architectural improvements over Zamba1-7B:
Mamba1 blocks have been replaced with Mamba2 blocks
We apply a LoRA projector to both shared attention and MLP block, which allows the network to specialize the shared layers at each invocation of the shared layer across depth
We added Rotary Position embeddings to the shared attention layers which we found slightly improved performance.
Our architecture also differs from Zamba2-2.7B by utilizing LoRAs on the shared attention layers and using only a single shared layer instead of the alternating scheme employed in Zamba2-2.7B.
Zamba2-1.2B was pretrained for approximately 3T tokens on a dataset composed of Zyda and other open-access pre-training datasets (all aggressively filtered and deduplicated to ensure quality), then annealed on 100B of the highest-quality tokens.
Zamba2-1.2B will be released under an open source license, allowing researchers, developers, and companies to leverage its capabilities. We invite the broader AI community to explore Zamba's unique architecture and continue pushing the boundaries of efficient foundation models. A Huggingface integration is available here, and a pure-pytorch implementation is available here.
Zyphra's team is committed to democratizing advanced AI systems, exploring novel architectures on the frontier of performance, and advancing the scientific study and understanding of powerful models. We look forward to collaborating with others who share our vision.