
Research
San Francisco, California
In collaboration with AWS, Zyphra Research evaluated the AWS Trainium/Inferentia¹ hardware stack and AWS Neuron software stack for its potential use in workloads where communication and memory movement dominate cost, including decode-bounded inference, long-context attention, and MoE-style models. To test this regime, we implemented Domino-style tensor-parallel communication overlap within the AWS Neuron inference stack and benchmarked Llama 3-8B across varying NeuronCore counts on Inferentia2. Our results improve aggregate output throughput and reduce both time-to-first-token and time per output token, with the clearest gains appearing at higher tensor-parallel widths where collective communication becomes a larger portion of the critical path. This work demonstrates Zyphra’s ability to optimize across the Trainium/Inferentia stack and highlights the systems work required to unlock performance across multiple hardware ecosystems.
Introduction
Zyphra Research trains open-weight multimodal foundation models and conducts fundamental research across neural network architectures, learning algorithms, and systems performance for heterogeneous silicon. We evaluate accelerators by workload fit, available capacity, cost, achievable performance, and the engineering effort required to reach that performance. This lets us match each workload to the hardware regime where it performs best.
In collaboration with AWS, we evaluated the broader Trainium/Inferentia hardware and software stacks because its memory capacity, scale-up topology, and dedicated communication resources are well aligned with workloads where memory movement and collectives dominate cost, including decode-bounded inference, long-context workloads, and MoE-style models. To test this regime, we added Domino-style communication overlap to the AWS Neuron inference stack and benchmarked Llama 3-8B across varying NeuronCore counts on an Inferentia2 node. The results show improved aggregate output throughput, time-to-first-token, and time per output token, with the clearest gains appearing at higher tensor-parallel widths. This work demonstrates Zyphra’s ability to build on and optimize the broader AWS Trainium/Inferentia stack, and it is a step toward understanding how Trainium/Inferentia hardware can support Zyphra’s training and inference workloads.
Background
Intra-node Communication Fabric
In order to better motivate the design choices in this work, we first contrast the Inferentia2 hardware against comparable SKUs from other vendors.
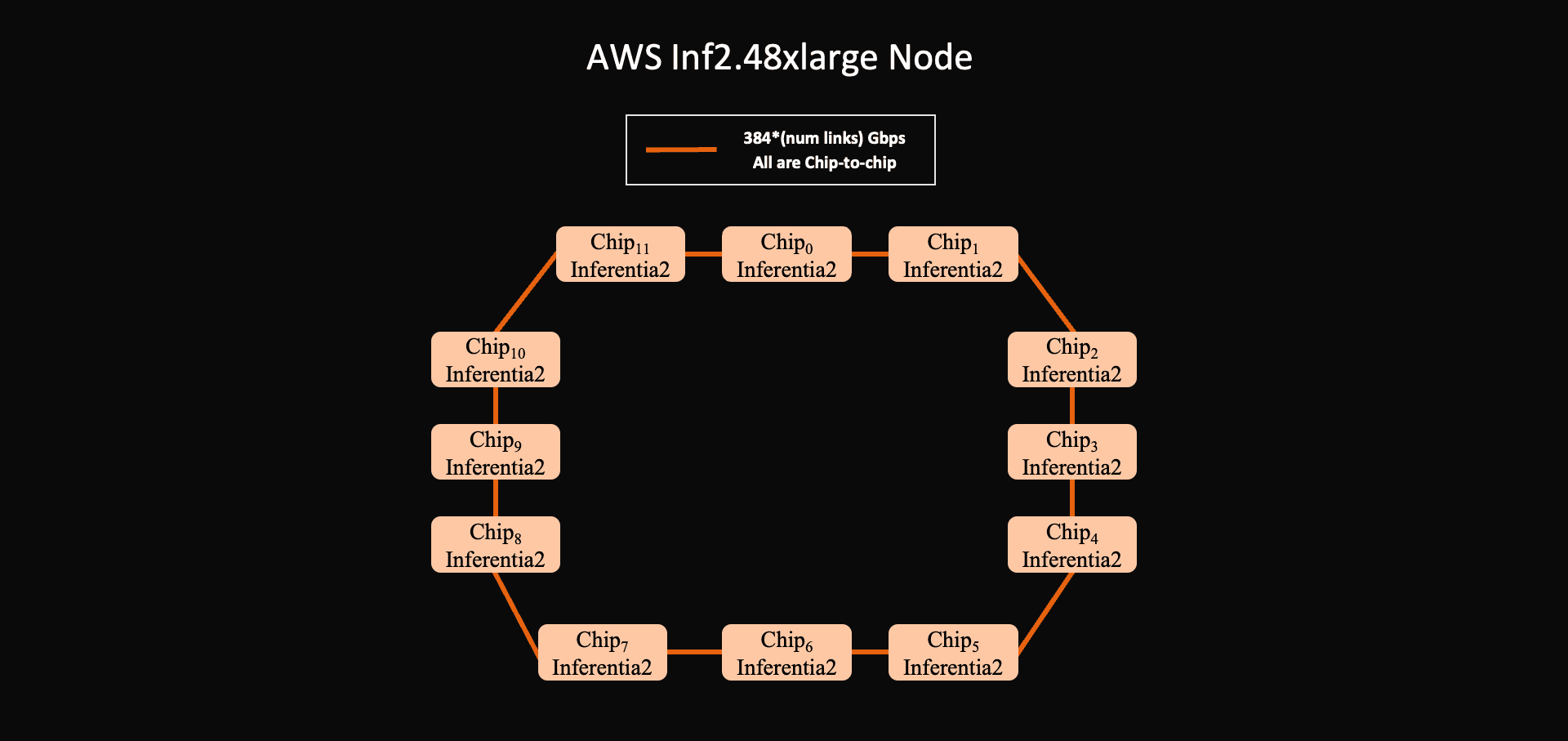
AWS Neuron / Inf2: NeuronLink ring. An Inf2.48xlarge contains 12 Inferentia2 chips connected by NeuronLink-v2 in a ring topology. Each chip has direct physical links only to its ring neighbors, so traffic between non-neighbor chips takes extra hops. This requires all parallelism topologies and communication middleware to be centered around ring algorithms. Each link supports 96 GiB/s of bidirectional bandwidth.
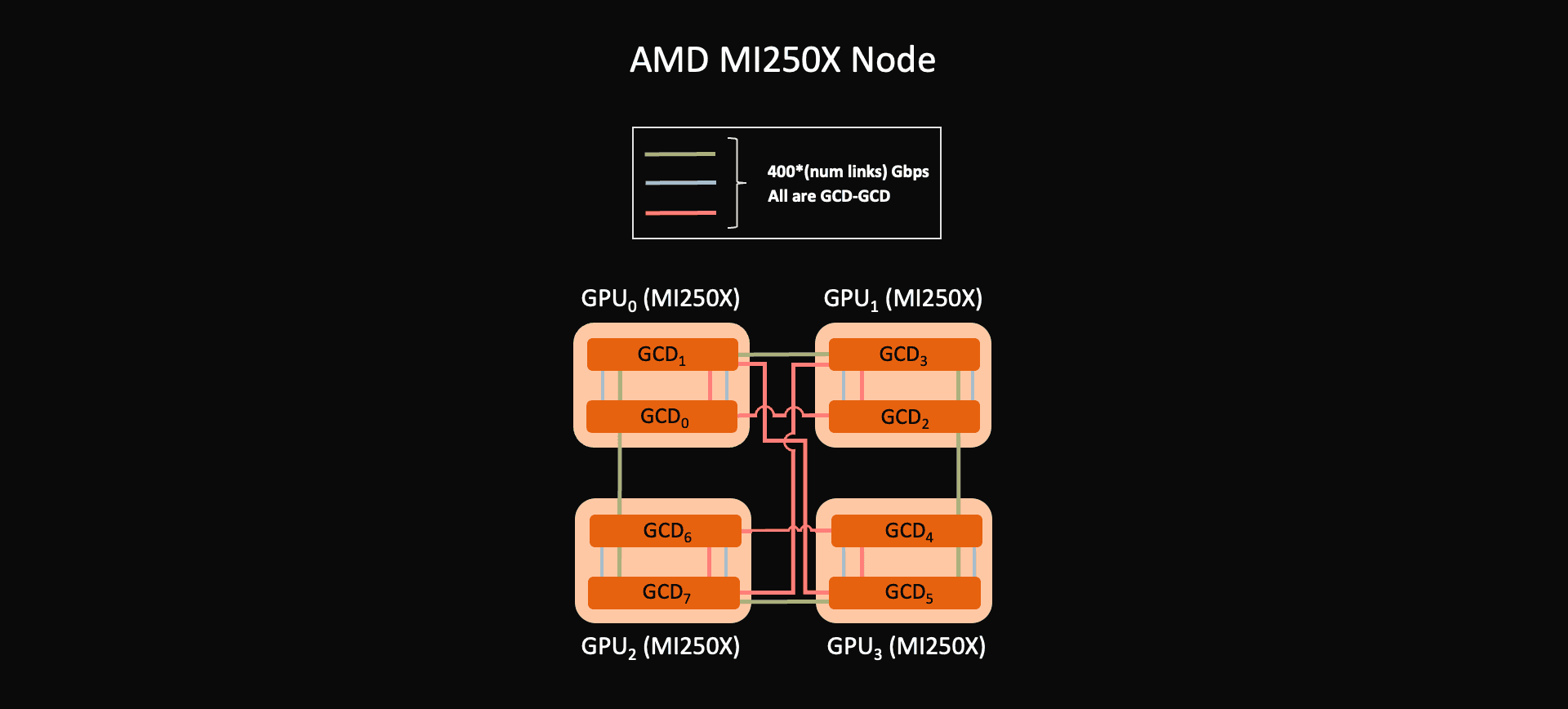
AMD MI250X: Infinity Fabric point-to-point links. Each MI250X GPU contains two GCDs (graphics compute dies). The two GCDs inside a module are connected by high-bandwidth in-package Infinity Fabric, and external Infinity Fabric links connect GCDs across GPUs. This is still a point-to-point fabric rather than a switch fabric. The GPU-to-GPU Infinity Fabric link supports 100 GB/s bidirectional bandwidth, and the GCD-to-GCD Infinity Fabric link supports 400 GB/s bidirectional bandwidth.
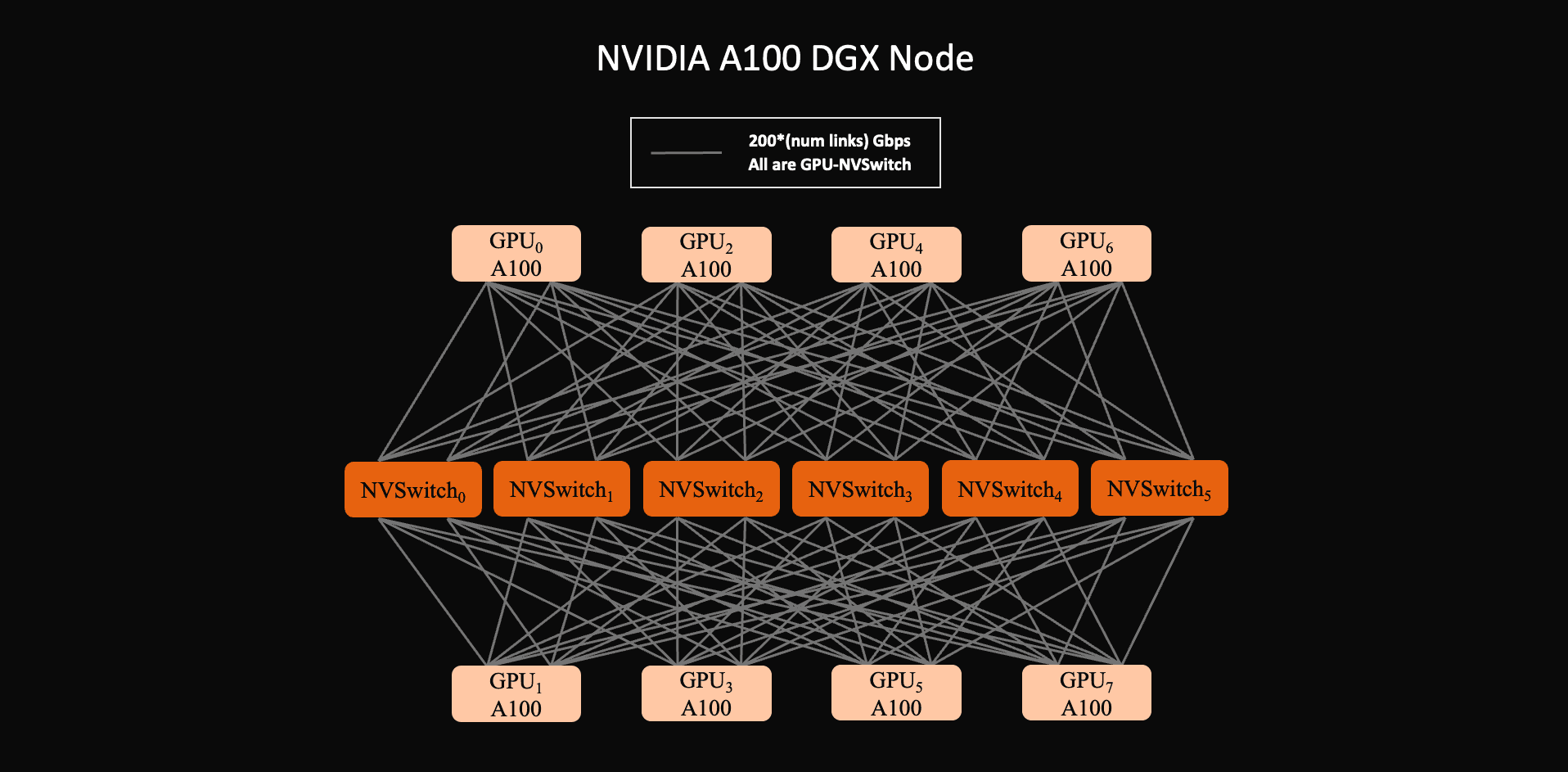
NVIDIA A100 / HGX A100: NVLink through NVSwitch. HGX A100 uses eight A100 GPUs and six NVSwitch chips. Each A100 has 12 NVLink ports, and each NVSwitch is a non-blocking switch connected to all eight GPUs. As a result, any A100 can communicate with any other A100 at full NVLink bidirectional speed, up to 600 GB/s per GPU. This adds switch silicon, board complexity, power, and platform cost, but it greatly simplifies communication middleware and parallelism schemes.
Compute Organization
AWS Neuron / Inf2: two NeuronCores per chip with separate engines. Each Inferentia2 chip has two NeuronCore-v2 cores. Each NeuronCore-v2 contains a Tensor Engine, Vector Engine, Scalar Engine, and GPSIMD Engine, and the Inf2 silicon also includes dedicated collective compute engines. The Tensor Engine is a systolic-array unit for GEMM, convolution, and related tensor operations. The Vector Engine handles operations such as AXPY, layer normalization, pooling, and other vector-style work. The Scalar Engine handles scalar operations and control-oriented work. The GPSIMD Engine consists of programmable 512-bit vector processors for custom operators. The practical consequence is that performance depends on keeping several distinct hardware engines active at once. For this benchmark, the key target is to run tensor-engine tiles while collective communication is in flight.
NVIDIA A100: SMs with CUDA cores and Tensor Cores. Each A100 is organized around streaming multiprocessors. The A100 implementation has 108 SMs; each SM has FP32 CUDA cores for general GPU work and Tensor Cores for matrix operations. Tensor Cores handle the dense BF16/FP16/TF32 matrix math used in attention and MLP GEMMs, while CUDA cores and other SM resources handle elementwise operations, indexing, reductions, and so on.
AMD MI250X: two GCDs, SIMD units and matrix cores. MI250X contains two GCDs, and each GCD is exposed as a distinct GPU device and logical rank. Each MI250 GCD has 104 active compute units, with each compute unit subdivided into SIMD units for wavefront execution. The compute units also include matrix cores similar to NVIDIA tensor cores for matrix-matrix operations. The principal challenge when co-designing for MI250X GPUs is that, because of the two logical GCDs, all two-level parallelism topologies become three-level. Instead of one intra-node mesh and an inter-node mesh, we have an intra-GPU mesh across GCDs, an intra-node mesh across GPUs, and an inter-node mesh. Future generations of AMD GPUs (MI300X) unified multiple compute dies behind a single logical device, so the programming model no longer splits them into separate ranks. The internal fabric connecting the dies still exists but is managed below the application-visible abstraction.
Communication Overlap on Inferentia2
Language model inference performance depends on compute throughput, memory bandwidth, and the intra-node communication fabric. Prefill demands heavy compute from the accelerator, while autoregressive decode streams weights and KV cache from high-bandwidth memory (HBM) with very limited compute required per generated token. When weights and caches are too large to fit within a single accelerator’s HBM, we must parallelize across accelerators. Tensor parallelism (TP) is one such parallelism scheme which requires two high-volume collectives in every transformer block. Long-context attention and large-model² inference add more communication and memory movement, so hiding the communication latency by overlapping it with compute is critical to achieve acceptable performance.
Overlapping communication and computation on Inferentia2 chips is especially important. The Trainium hardware line tends to have a more even ratio of empirical FLOPs to intra-node communication latency and bandwidth than comparable accelerators. Specifically, Trainium1/Inferentia2 sits at roughly 225 BF16 FLOP/byte, while comparable generations of TPUs and GPUs sit in the range of 300–600 BF16 FLOP/byte. This makes the architecture more balanced for workloads with lower arithmetic intensity, such as decode, MoE expert routing, grouped GEMMs, KV-cache reads, and long-context attention.
In terms of intra-node topology, each Inf2.48xlarge contains 12 Inferentia2³ chips, each with two NeuronCore-v2 cores and local HBM. Each Inferentia2 node connects chips in a ring point-to-point fabric called NeuronLink. In a switched fabric like NVLink, a rank can communicate with any other rank through the switch at full bandwidth. In a point-to-point ring, each chip has direct links only to its neighbors. Traffic between non-neighbor chips must traverse intermediate hops, and multiple transfers can contend for the same physical link. A tensor-parallel all-reduce or all-gather that ignores the ring layout can therefore lead to congested links and follow longer-hop paths ultimately resulting in longer synchronization time and worse final performance.
While larger intra-node topologies allow more parallelism to traverse high-bandwidth NeuronLink interconnects rather than inter-node elastic fabric adaptor (EFA) links, the benefit depends on laying out those parallel axes carefully within the ring. Communication operations must be overlapped with computation so that each hop does not become a layer-level barrier.
In terms of compute, each NeuronCore has specialized resources for tensor, vector, scalar, and general-purpose operations. Trainium systems also include dedicated collective communication hardware resources. To maximize performance the kernel must keep computation and communication active simultaneously, preserve efficient tensor-engine tiles, and keep collective latency off the critical path when possible.
With these hardware factors in mind, we evaluated if AWS Inferentia2 can support the same style of systems work that we use on other accelerator stacks, such as topology-aware parallelism, custom kernels, communication scheduling, and model-specific tuning. We choose Domino as a representative feature to implement within the AWS Neuron software stack.
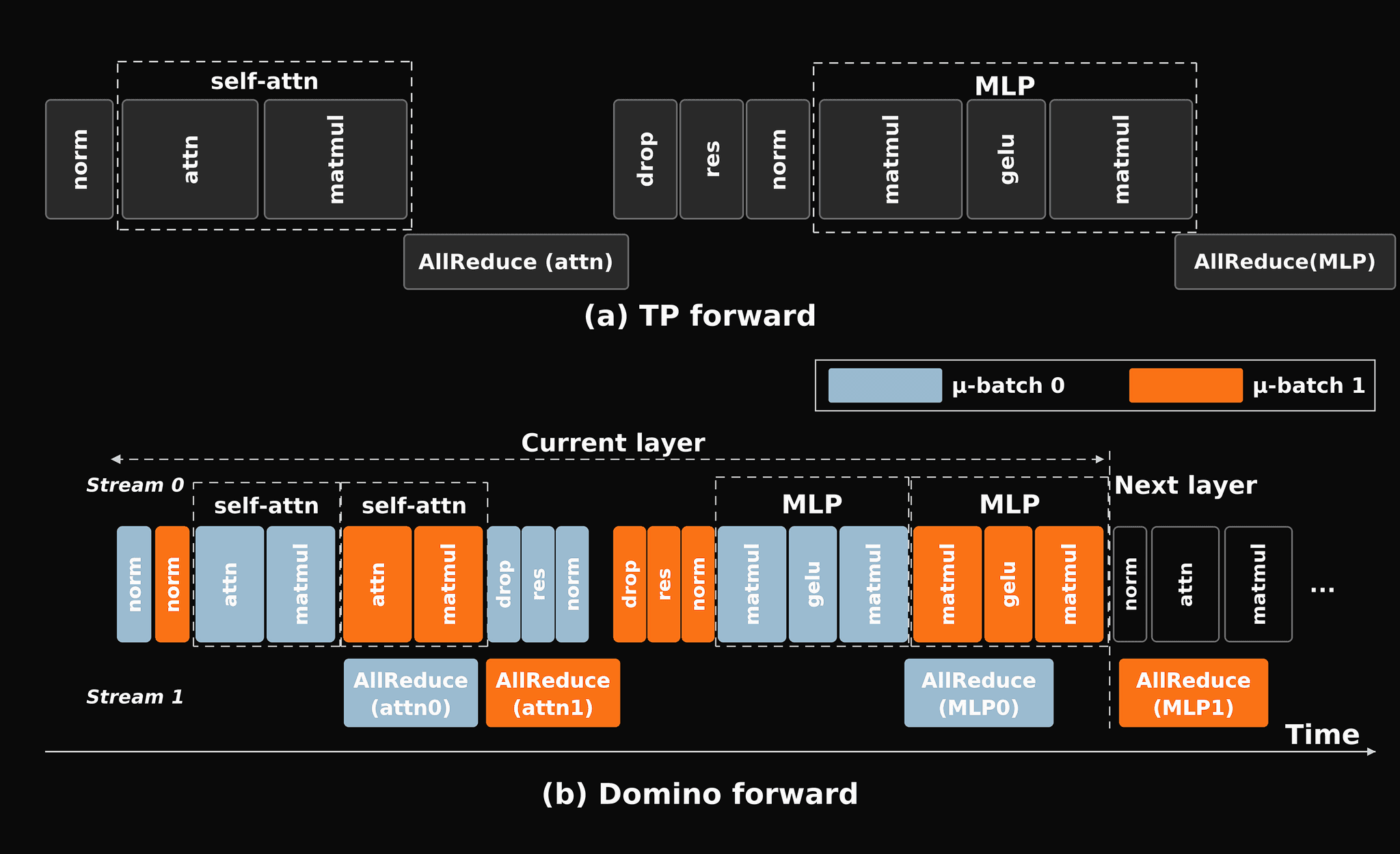
Figure adapted from Domino paper. Transformer block (i.e., 1 self-attn and 1 MLP) forward phase. Upper figure is vanilla TP implementation, and bottom figure is Domino implementation.
Tensor Parallelism and Domino Scheduling
Tensor parallelism splits an attention or MLP block across accelerator devices. Each rank computes partial projections or partial outputs, then communication collectives move activations back into the layout required by the next sublayer.
The cost of those collectives grows with tensor-parallel width, message size, topology, collective algorithm, and runtime scheduling. Decode has limited compute per token to cover communication. Prefill has more compute per request, but collective placement still affects TTFT.
Domino provides a scheduling method for this problem by overlapping computation with TP communication across multiple batches during inference or training. While this requires deep knowledge of the underlying computation kernels of attention and MLPs, it does not require changes to the computation kernels themselves.
Neuron Implementation
We first assembled a Llama 3-8B inference path using the best-performing NKI kernels available within the Neuron ecosystem. Then, we carried out systematic testing of the Neuron communication semantics, since Domino depends on overlapping communication and computation. On GPU systems, developers often reason about overlap through streams, NCCL kernels, and SM allocation. On Neuron, the relevant mechanism is the interaction between the compiler, collective interface, NeuronCore execution engines, and dedicated communication resources.
We first built small communication/computation microbenchmarks to understand the semantics of a matmul computation operation and a collective communication operation with no data dependency, and how to schedule concurrent execution on Neuron hardware.
After characterizing overlap behavior, we expressed the Llama 3-8B tensor-parallel regions as tiled compute and collective regions. The compiler was configured to allow communication/computation overlap and to create a two-stage pipeline. This allowed one tile to execute useful compute while another tile was inside a communication collective. We inserted fine-grained communication and computation synchronization to enable the compiler to maximize overlap. As such, our optimization is shape-dependent. Tile size affects tensor-engine efficiency, SBUF and PSUM pressure, vector and scalar work, collective message size, synchronization placement, and compiler scheduling. The results below use the best schedule we found for these Llama 3-8B shapes during this proof of concept, but more adaptive schemes will be explored in the future.
We adapted the Domino TP schedule around the fact that NeuronLink exposes a point-to-point graph rather than a switched all-to-all fabric. Our objective is to minimize hop count and keep all ring participants carrying traffic. This expresses a collective into a sequence of nearest-neighbor ring steps, which keeps routing local and distributes traffic across independent links as much as possible. There are many classical ring algorithms for collective communication so this is conceptually simple to implement. Modifications to tiled compute scheduling were relatively minor compared to the Domino implementation. Instead of launching an activation collective at the boundary of a matmul, we instead sliced the activation stream into tiles aligned with the NKI matmul schedule. While tile i was in a ring collective, tile i+1 could execute on the tensor engine, with fine-grained synchronization only at the points where the next block needed the communicated shard.
Benchmark Framing
Any reported benchmark combines hardware capability with software maturity. On one side, peak empirical FLOPs and HBM bandwidth only describe idealized workloads. On the other side, model-level benchmarks are impacted by the current state of an ecosystem’s compiler, kernels, collectives, runtime, and model implementation.
We use model-level benchmarks to locate bottlenecks in the current software state, and then use lower-level analysis to identify which part of the stack limits the final benchmark result. For this project, the question was how much exposed tensor-parallel collective latency could be removed from an NKI⁴-based Llama 3-8B inference path through Domino TP overlap on Inferentia2.
We tested using Llama 3-8B with inputs of 1,024 and 4,096, outputs of 512, batch sizes 4 and 8, and tensor-parallel configurations up to 24 NeuronCores. The 1,024-token input runs used 4, 8, 16, and 24 NeuronCores. The 4,096-token prompt runs used 2, 4, 8, 16, and 24 NeuronCores.
We report aggregate output throughput, time-to-first-token, and time per output token. Aggregate output throughput is generated tokens per second across the batch after prefill. Time-to-first-token, or TTFT, is latency until the first generated token and primarily measures the prefill path for fixed-shape runs. Time per output token, or TPOT, is the average latency for generated tokens after the first token and primarily measures decode.
The runs use fixed shapes and no live traffic. Effects from queueing behavior, random arrivals, prefix caching, KV-cache fragmentation, hierarchical caching, request routing, multi-tenant interference, and serving-engine scheduling are not measured in this benchmark.
Results
The figures below show the full scaling curves across NeuronCore counts. Each plot compares the baseline path against the Domino communication-overlap schedule for batch sizes 4 and 8. The main trend is that the benefit of overlap grows as tensor-parallel width increases.
Aggregate Output Throughput
Domino improves aggregate output throughput across the measured prompt lengths and batch sizes, with the largest gains occurring at the highest NeuronCore counts. This pattern is consistent with the expected behavior of a communication-overlap schedule, since wider tensor parallelism exposes more collective latency, and the schedule has more latency available to hide.
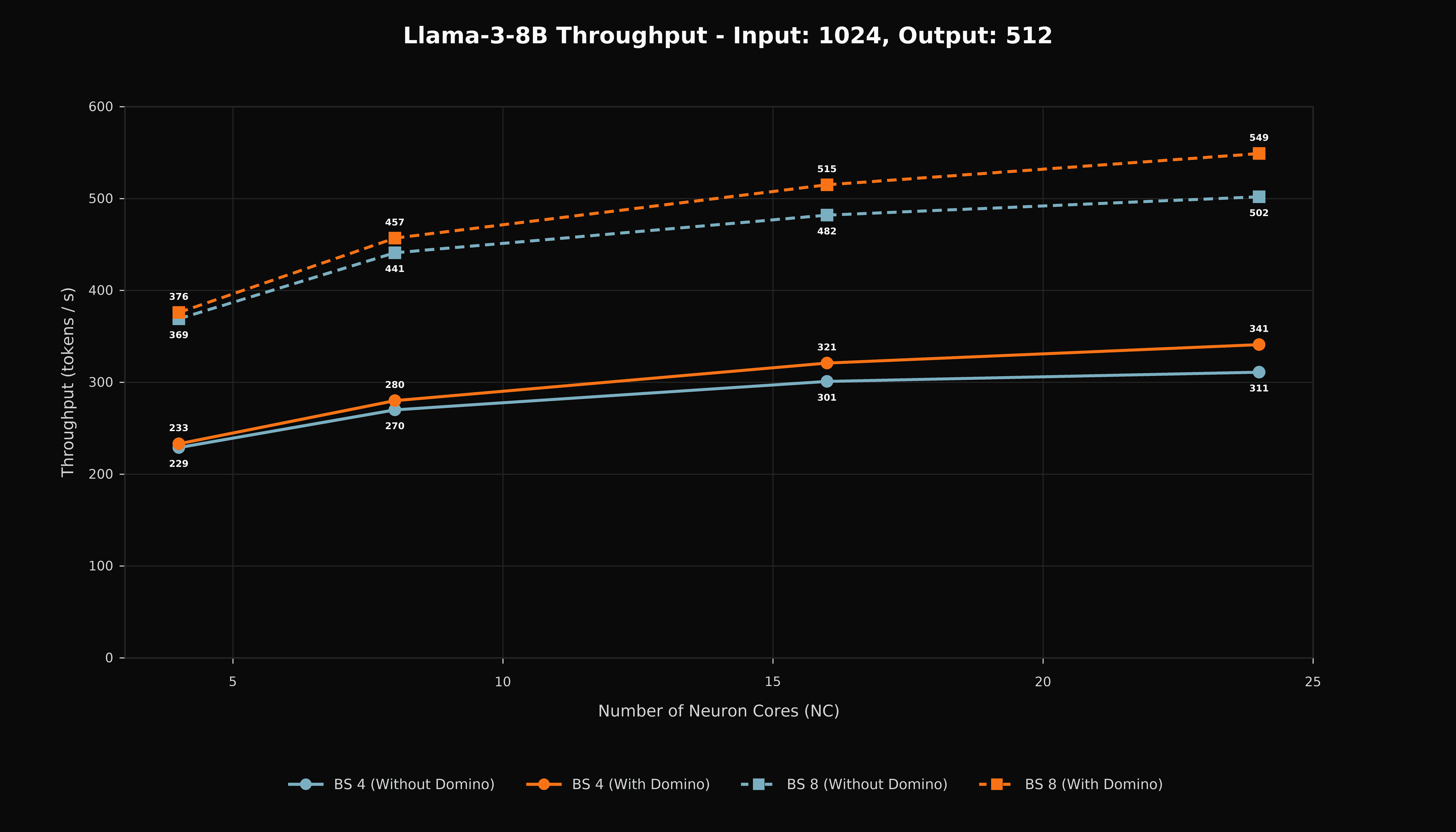
Figure 1. Aggregate output throughput for Llama 3-8B with a 1,024-token input and 512-token output.
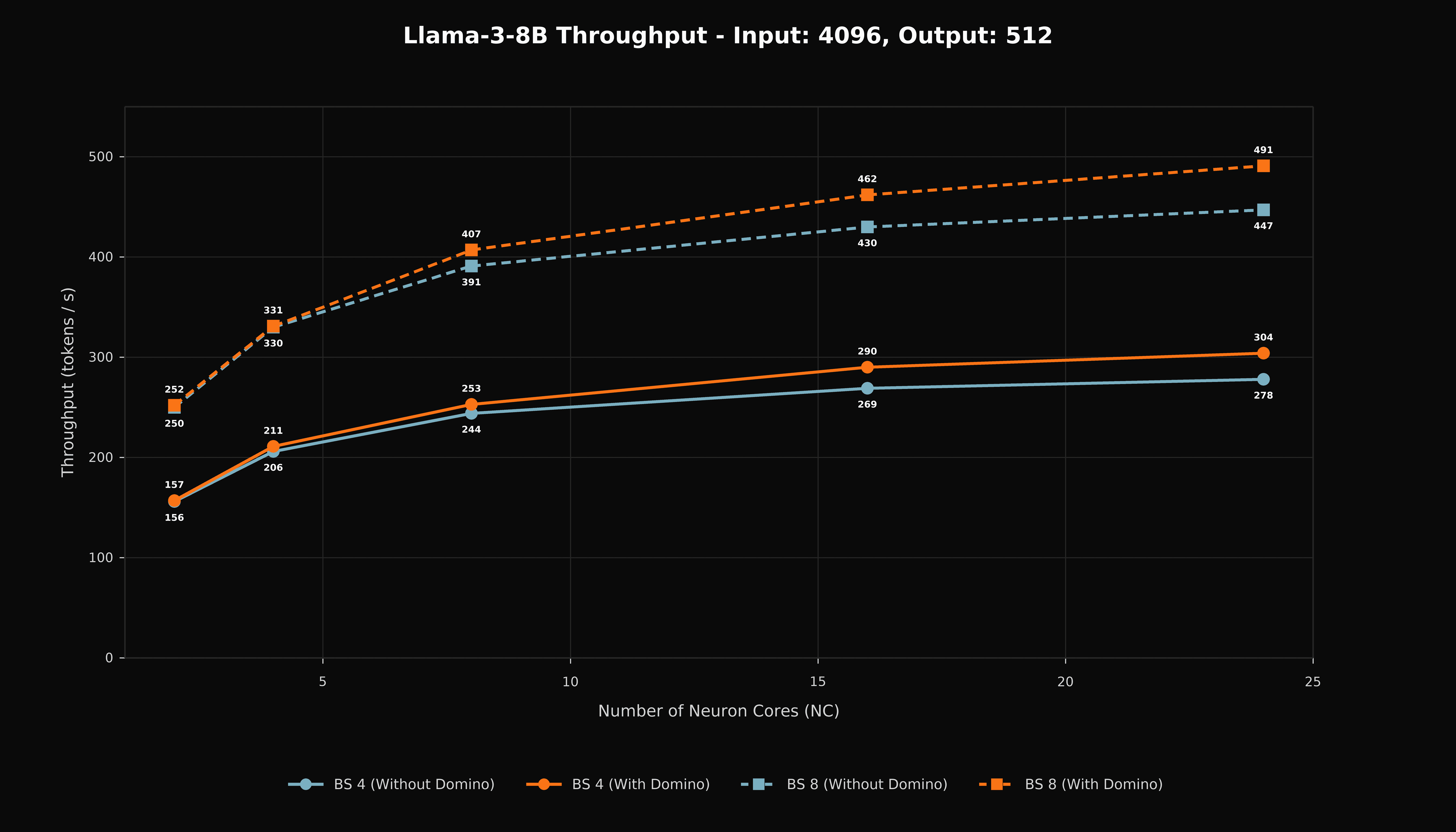
Figure 2. Aggregate output throughput for Llama 3-8B with a 4,096-token input and 512-token output.
Time-to-First-Token
TTFT improves across the measured 24-NeuronCore configurations. The prefill path has more compute than decode, so the size of the gain depends on the balance among compute tile duration, collective duration, memory movement, and synchronization placement.
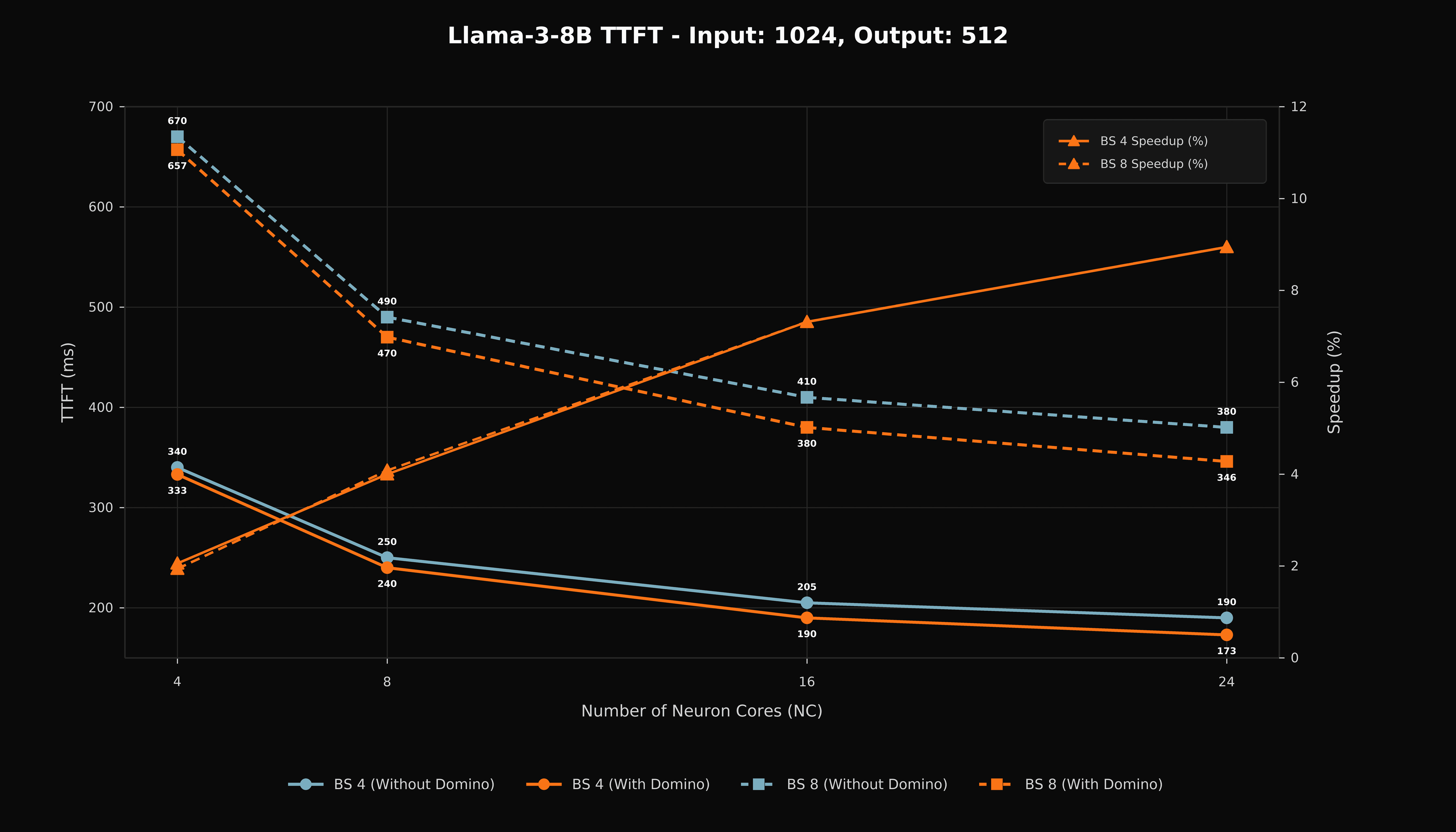
Figure 3. Time-to-first-token for Llama 3-8B with a 1,024-token input and 512-token output.
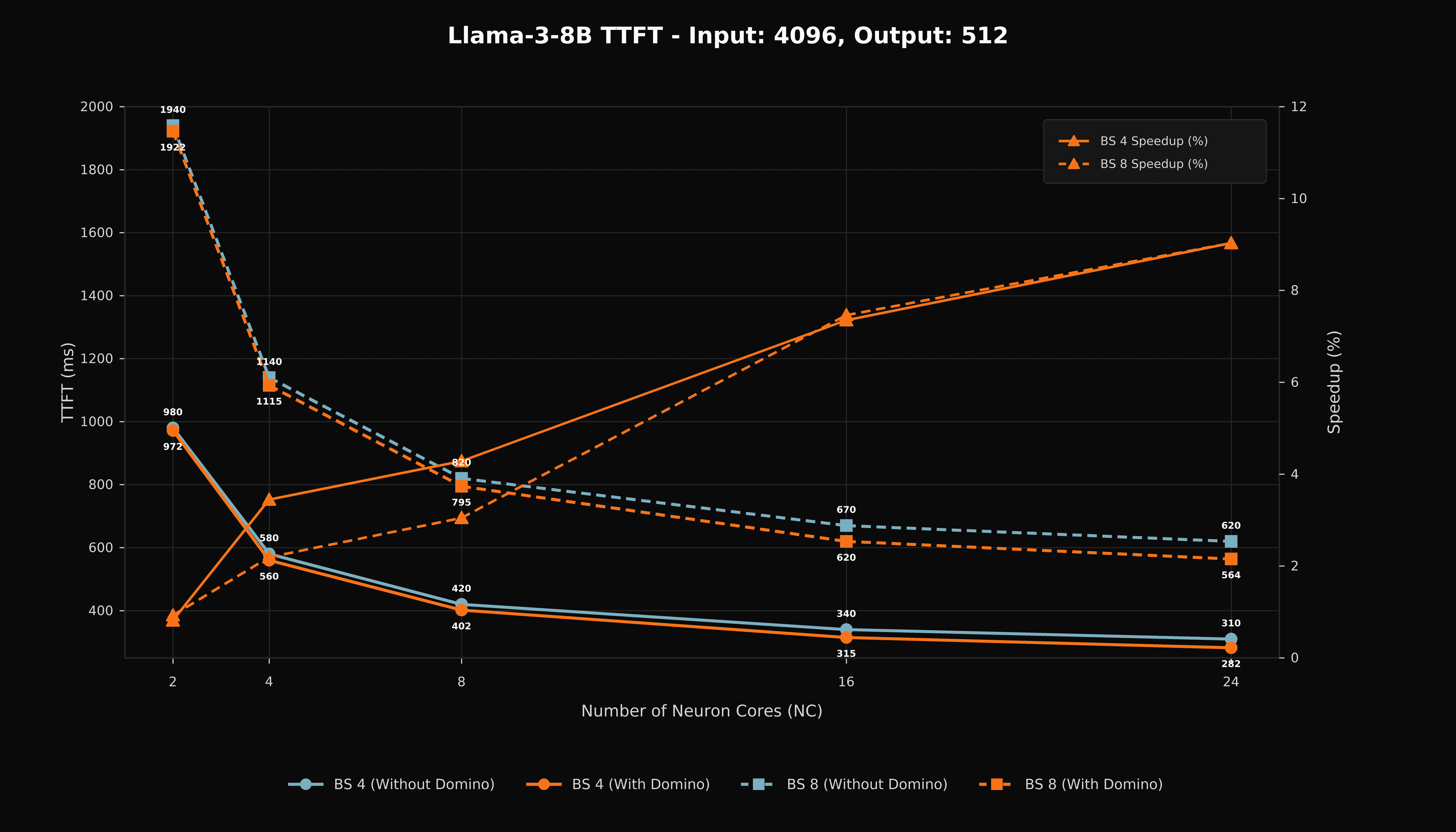
Figure 4. Time-to-first-token for Llama 3-8B with a 4,096-token input and 512-token output.
Time Per Output Token
TPOT reductions track the throughput gains. Decode provides a direct measurement of exposed collective latency because each generated token contains limited compute. The TPOT results show that the Domino schedule reduces critical-path communication time in the high-NeuronCore configurations.
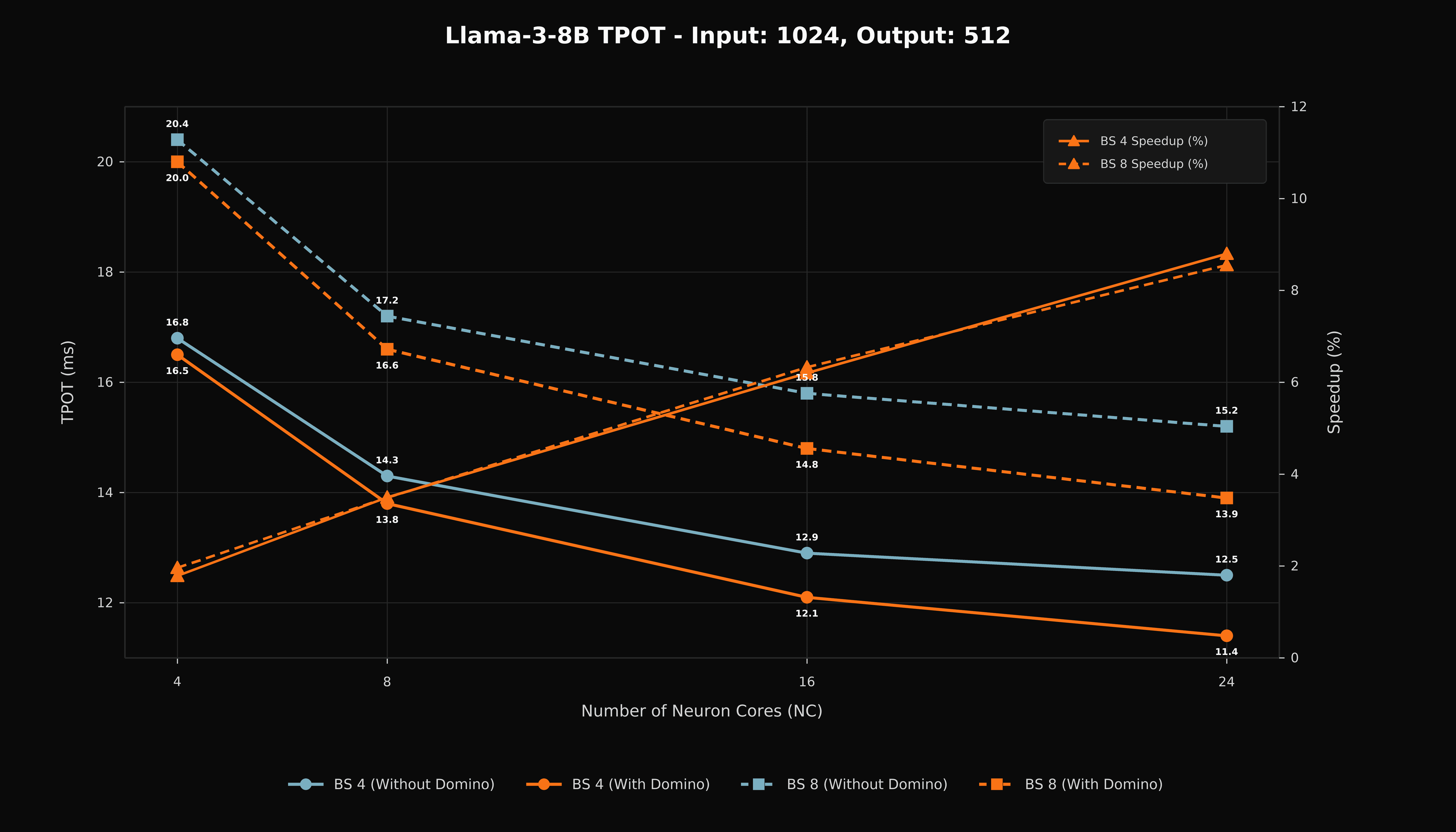
Figure 5. Time per output token for Llama 3-8B with a 1,024-token input and 512-token output.
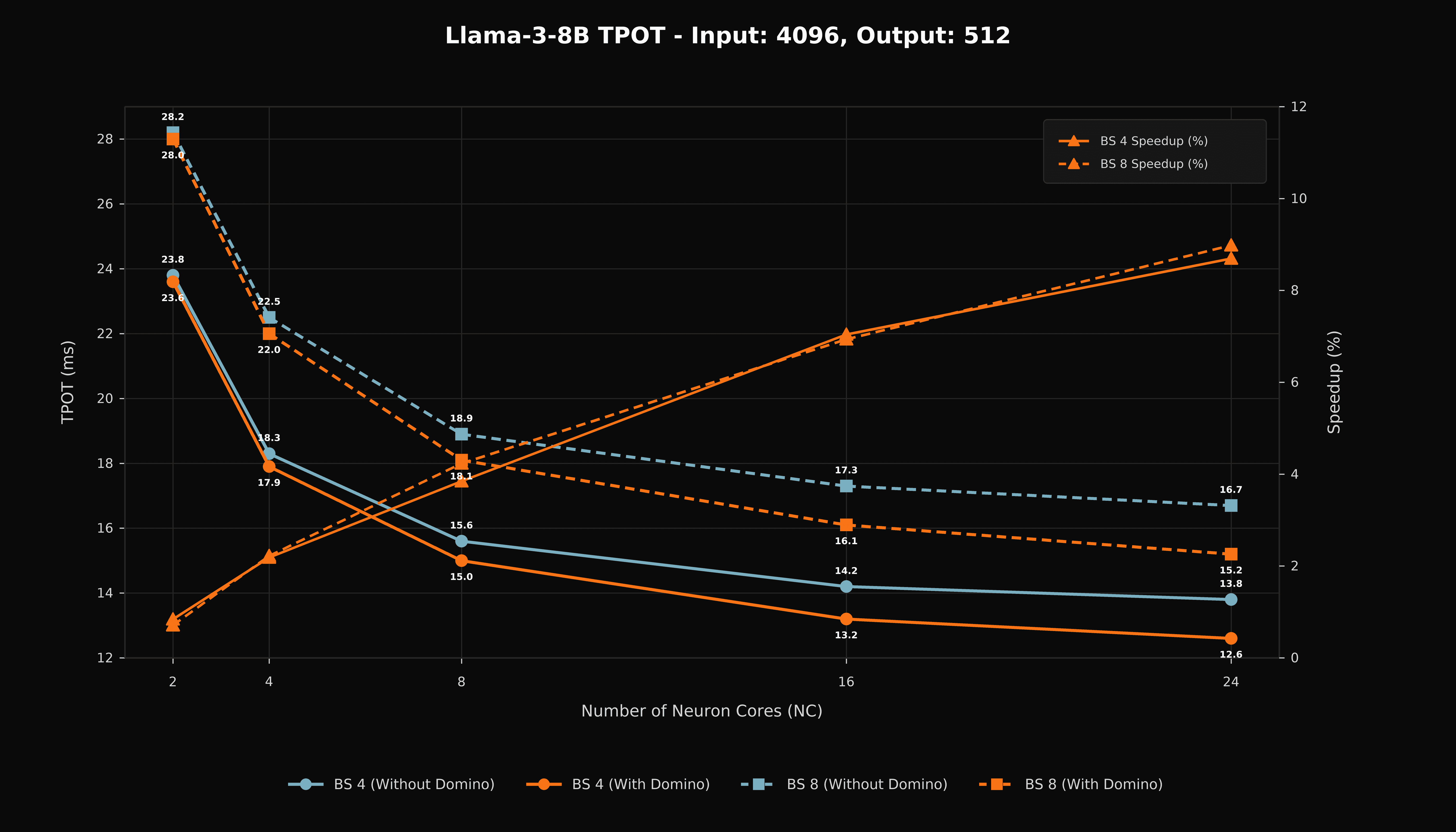
Figure 6. Time per output token for Llama 3-8B with a 4,096-token input and 512-token output.
Implications for Trainium Hardware
Trainium’s most useful regimes are those that can use all of the distinct hardware elements on Trainium concurrently, and those that can exploit the more balanced ratio of computation to communication. Trainium has more hardware elements to manage, but using them concurrently unlocks more expressivity than a bulk-synchronous kernel can offer on a GPU. Looking forward, we see the Trainium hardware ecosystem furthering Zyphra’s training and inference needs in the following regimes:
Inference workloads sensitive to memory and communication fabric bandwidth. Decode and MoE workloads can require less arithmetic per byte than dense prefill. Trainium’s arithmetic intensity and HBM capacity make this class of workload attractive at its provider TCO point. Performance depends on how well the stack streams weights and KV cache, keeps tensor-engine tiles efficient, and overlaps communication with computation.
Larger scale-up parallelism schemes. Trainium2 and Trainium2 Ultra provide larger NeuronLink scale-up domains than earlier Trainium1/Inferentia2 systems like those evaluated in this work. Larger scale-up domains make it possible to keep tensor parallelism, activation sharding, and other latency-sensitive parallel dimensions inside the high-bandwidth fabric. The ring topology of Inferentia2 and the 2D torus topology of Trainium2 requires topology-aware mapping and collectives, especially as the parallelism mesh grows.
Future Work
Extend to larger models. Llama 3-8B is a controlled test case to demonstrate feasibility. Larger dense models, MoE models, and longer-context workloads will have their own hardware and software challenges for us to address.
Connect to training. This work only implements the forward-pass portion of Domino. Training additionally requires backward-pass collectives, activation recomputation, and gradient accounting, which should further increase the value of communication overlap. In the longer term, after implementing these backward kernels, Trainium instances could power some of the training of novel model architecture and multimodality work that we perform within Zyphra Research.
Integrate with serving. While we ensured our implementation was within acceptable forward-pass tolerances, it needs validation inside a production serving engine. Request scheduling, batching, KV-cache management, prefix caching, speculative decoding, and multi-tenant traffic can change end-to-end user-visible performance and must be explored further.
Conclusion
We have demonstrated that by implementing and optimizing Domino-style tensor slicing and scheduling, we can improve inference on the Inferentia2 hardware. The gains are most visible at higher NeuronCore counts, where tensor-parallel collective latency is a larger part of the critical path.
Our result provides a concrete measurement of communication/computation overlap in a transformer workload. It also identifies the systems work that matters for Trainium, including topology-aware tensor parallelism, compiler-visible tiled schedules, efficient collectives, and model implementations that keep compute and communication engines active at the same time.
Our view of accelerator performance and optimization remains workload-driven. We ultimately choose hardware based on capacity, cost, achievable performance, and optimization effort. Trainium has strong potential for workloads where memory bandwidth, communication topology, and dedicated communication resources can be converted into lower inference cost or higher training throughput through software work. Domino is one piece of that conversion path.