
Research
San Francisco, California
At Zyphra, we are deeply invested in optimizing the user experience for AI. We believe the future of AI will involve a combination of cloud and edge deployment strategies with an increasing shift towards on-device inference for various use cases. In particular, we have been looking closely at how to improve the experience on edge devices by carefully designing and crafting hardware-aware models, and by applying personalization techniques. Our Zamba series of models, exemplifies our commitment to innovative foundation model R&D with useful applications on the edge.
This blog post discusses the key factors to consider when deploying models on edge devices. We emphasize the significant hardware constraints of these devices, and identify techniques to efficiently utilize local hardware resources - quantization, low-rank adapters, and real-time parameter offloading from storage.
We explore two case studies on Memory Bandwidth and Memory Capacity for iPhone 15 Pro (Apple) and Jetson Orin (Nvidia) edge platforms.
Andrew Greene, Kamil Rocki, Tomas Figliolia, Travis Oliphant, Beren Millidge
The Challenges and Benefits of Edge LLM Deployment
Deploying models locally has many benefits. Edge deployments can utilize existing compute resources which are often idle, meaning that inference does not require expensive and in-demand data-center Graphical Processing Units (GPUs). With local deployments, sensitive and personal data is never present on remote servers, enhancing user privacy and enabling regulatory compliance. Furthermore, processing data locally can significantly enhance the user experience by reducing model latency. Finally, model personalization can be made more dynamic by storing different weights on different devices – this enables models to be tailored directly on the device to suit individual user preferences and needs. In contrast, this can be challenging to achieve on cloud servers which must batch queries to maintain cost-efficiency.
Ultimately, powerful local models, capable of performing meaningful linguistic, multimodal, and even intellectual work, will likely be deployed on a large variety of edge devices which are specialized for relevant tasks or personalized for local users. These edge models can also be integrated with larger cloud models, e.g. by routing challenging queries to cloud models, or by offloading compute to the cloud where required. This synthesis of cloud and local compute will maximize efficiency in terms of cost and power and enable the widespread and ubiquitous deployment of AI systems.
However, deploying language models (LMs) on local devices also presents a unique set of challenges compared to data center deployments. Edge devices have vastly fewer system resources than data centers - increasing the size of models on edge devices is significantly more difficult than in data centers because memory bandwidth/capacity and processing cores are comparatively limited. We aim to address this by optimizing model architecture for parameter and compute efficiency, a process we have begun with the Zamba model series. Zamba models utilize a novel parameter sharing approach to reduce both the resident set size (RSS), and the number of floating-point operations (FLOP) required to generate the next token. The consequence of this design is higher FLOP efficiency, which directly translates to lower latency and higher throughput.
To achieve more general capabilities and utility, models must be embedded in a scaffolded system allowing, for instance, database or internet lookups (where available), or tool calling, to target specialized use-cases. Creating a general scaffolding system for on-device models is complex, given the variety and heterogeneity of environments and requirements.
The third challenge lies in the heterogenous and often complex architectures of edge devices. The figure below shows the typical architecture of an edge SoC (System-on-a-Chip), highlighting specialized accelerators like the Neural Engine found in the iPhone. It also illustrates the available memory access bandwidths.
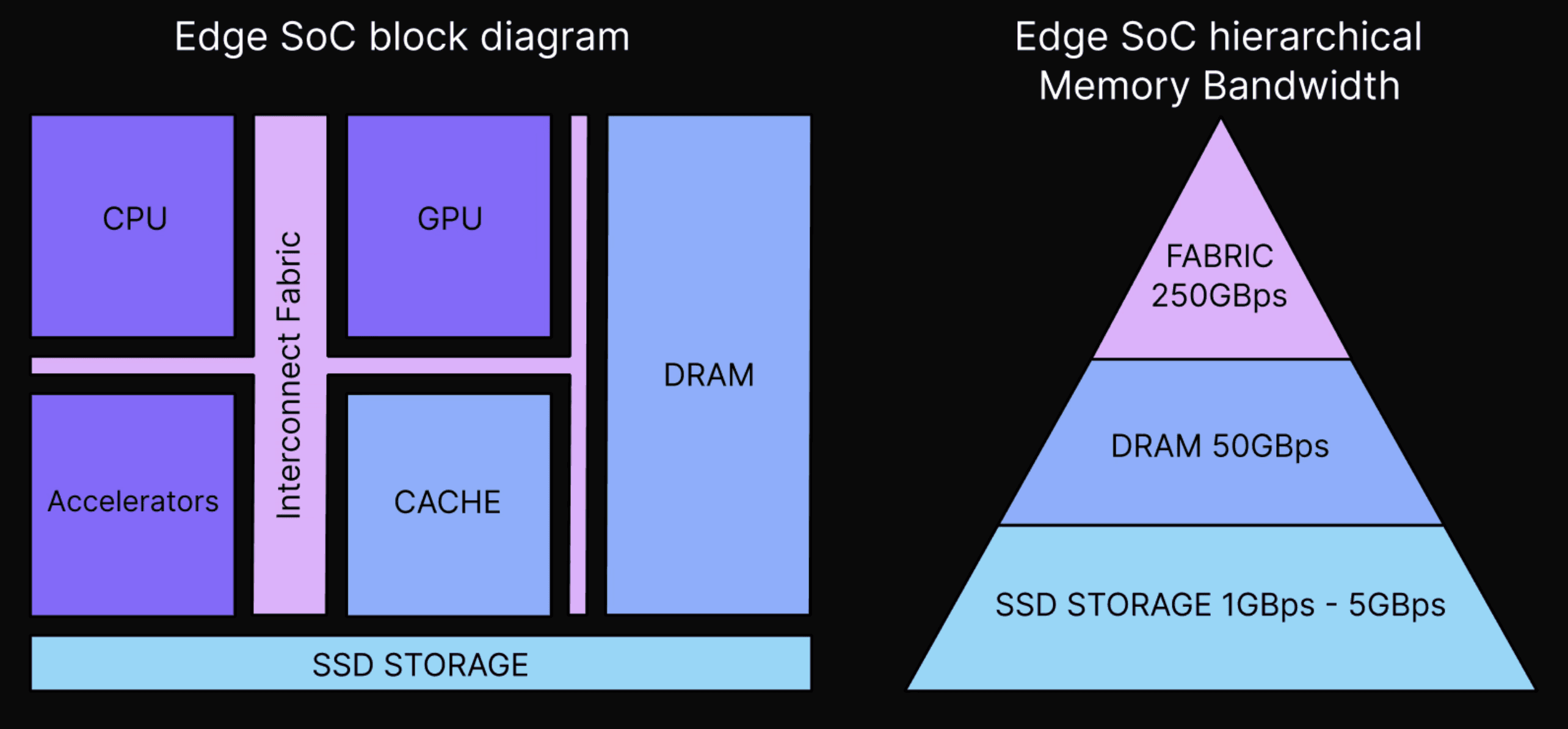
Such edge SoCs typically comprise multiple hardware resources, some optimized for ML workloads, such as local GPUs or Neural Processing Units (NPUs). Available resources vary depending on the device. Consequently, to maximize hardware utilization, the software platforms for serving edge models need to consider both effective multitasking, and splitting of work between different processors, which adds implementation complexity. Additionally, the runtime software ecosystem is fragmented and immature, presenting a large number of compile targets.
Nevertheless, the core constraint of edge devices is typically the same as data-center GPUs – memory bandwidth. Memory bandwidth is primarily utilized to load model parameters from RAM into the compute units of the device. In data centers, mini-batching is used to circumvent this memory bound. However, edge deployments typically infer one batch at a time (single-batch/batch size = 1 inference). Thus, optimizing model architecture and inference libraries to reduce memory bandwidth requirements for single-batch inference is critical.
Case study 1 - Memory Bandwidth
To illustrate some constraints on the edge, let’s consider two practical examples. The first concerns Apple’s iPhone 15 Pro, and the second concerns NVIDIA’s Jetson Orin (64GB).
iPhone 15 Pro has the following specifications (estimated from [14] and [15]):
CPU: 6-core (2 high-performance, 4 efficiency cores)
GPU: 6-core custom Apple GPU
Neural Engine (NPU): 16-core NPU
Memory Bandwidth: Approximately 51.2 GB/s (LPDDR5)
SSD Bandwidth: Approximately 1 GB/s
CPU Performance: Approximately ~256 GFLOPs (FP16) peak performance
GPU Performance: Approximately ~2.1 TFLOPS peak performance
Neural Engine Performance: Approximately 35 TOPs (Tera Operations per Second) peak performance
Jetson Orin (estimated from [11][12][13]):
CPU: 12-core Arm Cortex-A78AE v8.2 @ 2.2 GHz
GPU: 2048-core Ampere architecture GPU with 64 Tensor cores @ 1.3GHz
Memory bandwidth: 204.8 GB/s (64GB 256-bit LPDDR5)
SSD Bandwidth: Approximately 1.5GB/s
CPU Performance: ~1.6 TOPS INT8, ~400 GFLOPs FP16
GPU Performance: 85 INT8 TOPs, ~42.5 FP16 TFLOPs (dense), 5.3 FP32 TFLOPs
Now, let’s consider deploying the LLaMA3 8B model on this device. The model has the following attributes:
Number of parameters: ~8 billion
Quantization: 4-bit (0.5 bytes per parameter)
Model size: 8 billion parameters ~ 4 GB
Assume a compute bound regime; let’s calculate the possible tokens per second one could achieve on this device. Just to make things simple we will make the assumption that the number of flops required for LLaMA3 8B is approximately 16 GFLOPS. We assume this because most operations are done in the MLP layers of transformers, which require 1 multiply and 1 add per parameter, and that batch size is equal to 1.
Apple iPhone 15 pro:
CPU:
\[T_{\textit{compute}} \approx \frac{16 \times 10^{9}\textit{ FLOPs}}{256 \times 10^{9}\textit{ FLOPs}/\textit{s}} = 62.5\textit{ms} \rightarrow 16\textit{tps}\]
GPU:
\[T_{\textit{compute}} \approx \frac{16 \times 10^{9}\textit{ FLOPs}}{2.1 \times 10^{12}\textit{ FLOPs}/\textit{s}} = 7.62\textit{ms} \rightarrow 131.25\textit{tps}\]
Neural Engine:
\[T_{\textit{compute}} \approx \frac{16 \times 10^{9}\textit{ FLOPs}}{35 \times 10^{12}\textit{ FLOPs}/\textit{s}} = 0.457\textit{ms} \rightarrow 2187.5\textit{tps}\]
Jetson Orin:
CPU:
\[T_{\textit{compute}} \approx \frac{16 \times 10^{9}\textit{ FLOPs}}{400 \times 10^{9}\textit{ FLOPs}/\textit{s}} = 40\textit{ms} \rightarrow 25\textit{tps}\]
GPU:
\[T_{\textit{compute}} \approx \frac{16 \times 10^{9}\textit{ FLOPs}}{42.5 \times 10^{12}\textit{ FLOPs}/\textit{s}} = 0.376\textit{ms} \rightarrow 2656\textit{tps}\]
Let's now estimate the number of tokens that can be processed per second under a memory-bound scenario, where memory bandwidth is the limiting factor. Given a memory bandwidth of 51.2GBps for the iPhone and 204.8GBps for Jetson’s Orin, a 4-bit quantization scheme, and the requirement that model weights must be read at least once per token, we can calculate the number of tokens per second as follows:
Apple iPhone 15 pro:
\[\frac{\text{Memory Bandwidth}}{\text{Model Size}} = \frac{51.2\text{ GB}\textit{ps}}{4 \text{ GB}} = 12.8\textit{tps}\]
Jetson Orin:
\[\frac{\text{Memory Bandwidth}}{\text{Model Size}} = \frac{204.8\text{ GB}\textit{ps}}{4 \text{ GB}} = 51.2\textit{tps}\]
Beyond loading the model weights, there is additional overhead from reading and writing activations, which increases the total data that must be transferred for each token generated. Assuming the activations per layer are substantial—potentially hundreds of MBs per layer, depending on the architecture—we estimate that the model size expands from 4GB to 6GB due to these activations. Consequently:
Apple iPhone 15 pro:
\[\frac{\text{Memory Bandwidth}}{\text{Model Size}} = \frac{51.2\text{ GB}\textit{ps}}{6 \text{ GB}} = 8.53\textit{tps}\]
Jetson Orin:
\[\frac{\text{Memory Bandwidth}}{\text{Model Size}} = \frac{204.8\text{ GB}\textit{ps}}{6 \text{ GB}} = 34.13\textit{tps}\]
It's evident that, regardless of the compute core selected, memory bandwidth remains the most critical limiting factor on the edge. This theoretical value closely matches actual performance measurements, with variations mainly due to the precise size of activations and context length. To address this, Zyphra is prioritizing techniques that reduce bandwidth utilization, such as quantization, the use of LoRA adapters [1], approximate matrix multiplication methods such as randomized linear algebra, and SVD decomposition. Additionally, focusing on SSM models, which have a very compact memory activation footprint, further minimizes bandwidth used for activations [2, 3].
Case study 2 - Memory Capacity
In the previous case study, we focused on memory bandwidth, but here we will shift our attention to the issue of memory capacity. Edge devices are limited by the amount of available off-chip memory (usually a variant of Double Data Rate memory or DDR for short), so one approach to deploying larger models is to use storage for offloading model parameters, where only a portion of the model resides in DRAM at a time and the rest is in SSD storage. Alpha \(\alpha\) represents the proportion of the model in storage, and \(M_{\text{model}}\) represents the model size. The amount of data retrieved from DDR must be at least the total model size, as the part of the model in storage will be loaded momentarily into DDR before transfer to the compute cores. Whatever bandwidth we use from DDR, one will have to take into account the following identity:
\[\frac{M_{\textit{model}}\cdot(1-\alpha)}{\text{DDR}_{\textit{BW}}} = \frac{M_{\textit{model}}\cdot\alpha}{\text{SSD}_{\textit{BW}}} \rightarrow \alpha = \frac{1}{1+\frac{\text{DDR}_{\textit{BW}}}{\text{SSD}_{\textit{BW}}}}\]
This indicates that to avoid bandwidth limitations, the selected alpha must satisfy this specific condition. Referring back to the iPhone example, where the DDR to SSD bandwidth ratio is about 50, alpha would need to be 0.0196. This means that only 2% of the model can be loaded from storage while still maximizing DRAM bandwidth, which is not very practical. Considering the previous equation, but this time treating the DDR bandwidth as the unknown variable. This would yield the following result:
\[\text{DDR}_{\textit{BW}} = (\frac{1}{\alpha}-1)\cdot\text{SSD}_{\textit{BW}}\]
With an equal distribution between SSD and DDR (i.e. half the parameters offloaded; alpha = 0.5), the DDR bandwidth utilized would need to match that of the SSD. This would result in a significant reduction in the effective DDR bandwidth used. This necessarily results in significant slowdowns: as per the previous example, DDR memory bandwidth (not FLOPs) is the primary bottleneck on performance. Specifically, in the case of the iPhone, where the SSD bandwidth is 1GBps and the maximum DDR bandwidth is 50GBps, this configuration would reduce DDR bandwidth utilization by a factor of 50 (50/1). This reduction would lead to a 50x slowdown in tokens per second, which is entirely unacceptable.
It’s evident that maximizing SSD bandwidth is challenging, yet the vast storage capacity it offers is incredibly valuable. This is why we’re focused on advancing research in this area. At Zyphra, our team brings together expertise in chip design and model development, actively pursuing applied research to tackle this intricate and compelling issue at the edge.
Addressing the Challenges
Optimizing models for the edge requires technical advances in many areas, which we are pursuing at Zyphra. To improve the performance per memory bandwidth of a model, we are exploring a number of techniques: advanced quantization, matrix compression through low-rank approximations, parameter-sharing techniques, and designing and exploiting unstructured sparsity in model parameters and activations. Another approach is to exploit structured sparsity in the form of sparsely activated models such as Mixture of Experts [7] which perform extremely strongly per bit of memory bandwidth required in inference. To address the high memory footprint of such models, they must be carefully designed such that parameters can be offloaded to cheaper, more abundant storage, such as SSD or disk.
The software ecosystem for deployment of models on edge devices is also fragmented. There are tools that compile models for runtime execution, such as IREE and ExecuTorch, which can optimize model execution for different environments, leveraging hardware-specific optimizations to improve performance. There are also different tensor backends, whose operations are optimized for different runtimes. Hardware-specificity typically increases training and inference throughput [4, 5, 6]. We aim to collaborate with and build upon these, and other projects to create general libraries for optimizing model deployment and serving across a wide range of hardware platforms.
Serving Architecture for Local Models
To make local models ubiquitous, one of our goals at Zyphra is to build a general serving framework and architecture to run local models and their associated scaffolding efficiently across a wide range of devices. This architecture will require both a highly optimized and efficient inference runtime, as well as being capable of inferencing existing model architectures and exploiting sparsity efficiently. Such a system must also support task scheduling to integrate the hardware state with potential user requests to optimize the response given the constraints. For instance, this system could assess availability of access to internet APIs or cloud models for task offloading, detect when there is space available for on-device finetuning and personalization, and decide when to run background batch tasks vs handling user requests. Additionally, such a system must efficiently dispatch and route work to a variety of hardware cores on an SoC with differing capabilities and strengths. This system will have several components:
Serving Runtime: For features such as AI assistants capable of real-time communication with a user, it is crucial that edge models run efficiently so as not to dominate all hardware resources or to drain battery capacity unnecessarily while maintaining latency and throughput requirements. Many inference optimization techniques have been developed for data-center serving, such as Flash-Attention, Flash-Decoding, Speculative Decoding, Tree-Attention and Paged-Attention. Edge runtime optimizations are yet in their infancy; porting and optimizing these techniques to local devices, as well as devising novel approaches tailored to edge hardware, is critically important.
Storage and Data Handling: Memory bandwidth is a significant constraint in edge computing, and weights are often large since performance tends to scale with parameter size, so careful memory management is crucial. Larger more performant models may require offloading [8, 9] or efficient exploitation of sparsity, which must be efficiently implemented. Moreover, quantization to low-bit precision is vital for deployment and must also be well-supported.
Task Management: While simply inferencing a local model is important, more general use-cases require complex interactions of the model with the local device, its OS, and the user. We envision a general scaffolding system surrounding the ML models which can perform manage task priority and queuing when multiple requests are made to local models simultaneously, modules to handle interfacing with external systems such as the host OS, and external API calls, and general libraries for on-device personalization and finetuning.
Personalization
Local devices running inference at low batch sizes to handle specific use-cases or individual users enables a degree of model personalization, such as full finetuning, that would be highly inefficient to replicate in the cloud. This provides one of the key advantages of local model deployments – the ability to tailor your model to your own needs. To this end, we are exploring a number of approaches that allow the on-device customization of model behavior and parameters.
Low-rank adaptors (LoRA) for fine-tuning: We are exploring the use of low-rank adapters for fine-tuning the weights that represent the embedded user entities. Fine-tuning with LoRA has been widely proven to be effective, significantly reducing the number of parameters requiring training [1]. These user-specific adapters make the approach more suitable for deployment on resource-constrained edge devices, enabling efficient on-device personalization, with lower memory footprint and, potentially, on device fine-tuning. LoRAs can also be trained in a quantized fashion significantly reducing the memory requirements of training compared to inference.
Context-Aware Adaptation: We aim to design models that are context-aware, adjusting their responses based on the user’s current environment and recent interactions. Modifying activations based on the current context, such as time of day or user’s location, can be achieved locally using low-rank adaptation or other techniques such as activation steering. Activation steering can help generate responses that are more aligned with an individual user’s style, tone, and preferences and enable flexible control and adaptation of the model’s ‘personality’ to user feedback.
User Feedback Integration: Integrating direct user feedback into the model refinement process helps in tailoring the responses more accurately to user preferences. On-device implementation of RLHF and other preference optimization methods offers an advanced approach to personalization. By collecting and utilizing real-time user feedback directly on the device, models can be continually fine-tuned to better align with individual preferences without relying on cloud-based processing. This approach not only enhances personalization accuracy but also addresses privacy concerns, as sensitive user data remains on the user’s device. Moreover, on-device RLHF enables faster adaptation to user feedback, improving the responsiveness and relevance of the personalized experience. Additionally, by implementing adaptive proactiveness, one could more quickly converge to the user's requirements, rather than passively waiting for the model to align with what is implicitly expected.
Long-term Memory Systems: We are exploring the use of long-term memory retrieval systems to allow for personalization to data generated over the course of the local model’s interaction with a user. For instance, in a conversational context, the conversation history with a user can be stored on-device privately and can then be retrieved from during current conversations, enabling interactions that utilize information from significantly beyond the standard context window. We have released preliminary work addressing the challenges of such systems beyond those encountered in standard information-retrieval settings.
Overall, we believe that local, private, and personalized models offer compelling advantages in many domains and are required to achieve ubiquitous, personal AI. Zyphra aims to achieve highly performant models for local devices through careful co-design of model architecture with hardware constraints to maximize hardware utilization, memory-bandwidth and flop efficiency. Moreover, Zyphra aims to enable the online and on-device personalization of AI models for specific use-cases and specific users which we believe will unlock significant utility.
Citations
[1] Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke Zettlemoyer, “QLORA: Efficient Finetuning of Quantized LLMs,” arXiv preprint arXiv:2305.14314v1 [cs.LG], May 2023 (https://arxiv.org/pdf/2305.14314)
[2] Paolo Glorioso, Quentin Anthony, Yury Tokpanov, James Whittington, Jonathan Pilault, Adam Ibrahim, Beren Millidge, “Zamba: A Compact 7B SSM Hybrid Model,” arXiv preprint arXiv:2405.16712v1 [cs.LG], May 2024 (https://arxiv.org/pdf/2405.16712)
[3] Opher Lieber, Barak Lenz, Hofit Bata, et al, “Jamba: A Hybrid Transformer-Mamba Language Model,” arXiv preprint arXiv:2403.19887v2 [cs.CL], Jul 2024 (https://arxiv.org/pdf/2403.19887)
[4] Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré, “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness,” arXiv:2205.14135v2 [cs.LG], Jun 2022 (https://arxiv.org/pdf/2205.14135).
[5] Tri Dao, “FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning,” arXiv:2307.08691v1 [cs.LG], Jul 2023 (https://arxiv.org/pdf/2307.08691)
[6] Jay Shah, Ganesh Bikshandi , Ying Zhang , Vijay Thakkar , Pradeep Ramani, and Tri Dao, “FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision,” arXiv:2407.08608v2 [cs.LG], Jul 2024 (https://arxiv.org/pdf/2407.08608)
[7] Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, Jiayi Huang, “A Survey on Mixture of Experts,” arXiv preprint arXiv:2407.06204v2 [cs.LG], Aug 2024 (https://arxiv.org/pdf/2407.06204)
[8] Artom Eliseev and Denis Mazur, “Fast Inference of Mixture-of-Experts Language Models with Offloading,” arXiv preprint arXiv:2312.17238v1 [cs.LG], Dec 2023 (https://arxiv.org/pdf/2312.17238)
[9] Leyang Xue, Yao Fu, Zhan Lu, Luo Mai, Mahesh Marina, “MoE-Infinity: Offloading-Efficient MoE Model Serving”, arXiv preprint arXiv:2401.14361, Jan 2024
[10] Tim Dettmers, Luke Zettlemoyer, “The case for 4-bit precision: k-bit Inference Scaling Laws”, arXiv preprint arXiv:2212.09720 [cs.LG], Dec 2022
[11] https://developer.arm.com/documentation/102651/a/What-are-dot-product-intructions-
[13] https://developer.arm.com/Processors/Cortex-A78AE
[14] https://nanoreview.net/en/soc-compare/apple-a17-pro-vs-apple-a15-bionic