
Research
San Francisco, California
Zyphra introduces the Norm-AGnostic residual network (NAG), a residual architecture that treats the residual stream as a computational rotation system. NAG decomposes the residual stream into separate norm and direction lanes: layers operate solely upon the normalized direction through controlled orthogonal rotations, while norm is carried separately as a confidence-like signal. This lets layers contribute consistently across depth and enables an interpretable form of Mixture-of-Depths adaptive computation, where FLOPs saved by skipping layers can be traded for training on more tokens under a fixed compute budget. To our knowledge, this is the first practical justification for sparse depth as a pretraining-time scaling axis for efficient deep models.
Tomás Figliolia, Beren Millidge
Introduction
Residual connections are one of the central architectural inventions behind modern deep learning. They help address vanishing and exploding gradients by giving information and gradients a direct path through the network. In modern Transformers, this path is often described as the residual stream: a persistent computational state that each layer reads from, updates, and passes forward.
But this simple and powerful mechanism has a subtle flaw. As residual layers repeatedly add updates into the same stream, the norm of that stream grows with depth. A later layer therefore writes into a much larger accumulated state than an earlier layer, so an update of the same absolute size has a smaller relative effect on the representation. Deep layers can become progressively less influential while still costing the same FLOPs, memory, parameters, and training time.
We see signs of this throughout modern Transformer models. Deeper layers often behave close to identity maps, residual states become increasingly similar with depth, and pruning methods can remove substantial depth with surprisingly modest degradation. Taken together, these observations suggest that current architectures often leave capacity on the table: they add depth, but do not always turn that depth into useful computation.
At Zyphra, we view this as an architectural efficiency problem. Ideally, comparable parameters should have an equal opportunity to affect the residual state. But if a layer-40 parameter can only weakly affect the model because it writes into a much larger residual stream than a layer-4 parameter, then the architecture is paying the same cost for parameters with unequal influence.
The problem is especially clear in standard pre-norm Transformers. Each layer receives a normalized version of the residual stream, computes an update, and then adds that update back to the unnormalized stream. This normalization is crucial for training stability, but it also means that the layer has limited direct access to the actual scale of the state it is modifying. The result is a norm-dependent mismatch: the same update may strongly rotate a small residual vector, but barely perturb a large one. Across many layers, this mismatch can compound, forcing later layers to produce increasingly large updates to achieve the same angular change.
Our Norm-AGnostic Residual Network (NAG) is designed to directly target this failure mode. Instead of letting each layer add an unconstrained update into an ever-growing residual stream, NAG separates the residual stream into a normalized direction component and a separate norm component. Layers operate on the direction of the representation and contribute controlled angular updates, while the norm is transported separately. This makes layer contributions agnostic to the accumulated residual norm, preventing deep layers from being systematically diluted.
In this way, NAG gives a more equal footing between layers. Deeper parameters are no longer forced to write into a larger and harder-to-move state than earlier parameters. The goal is simple: turn added depth into useful computation, rather than leaving capacity on the table.
Norm-Agnostic Residual Networks
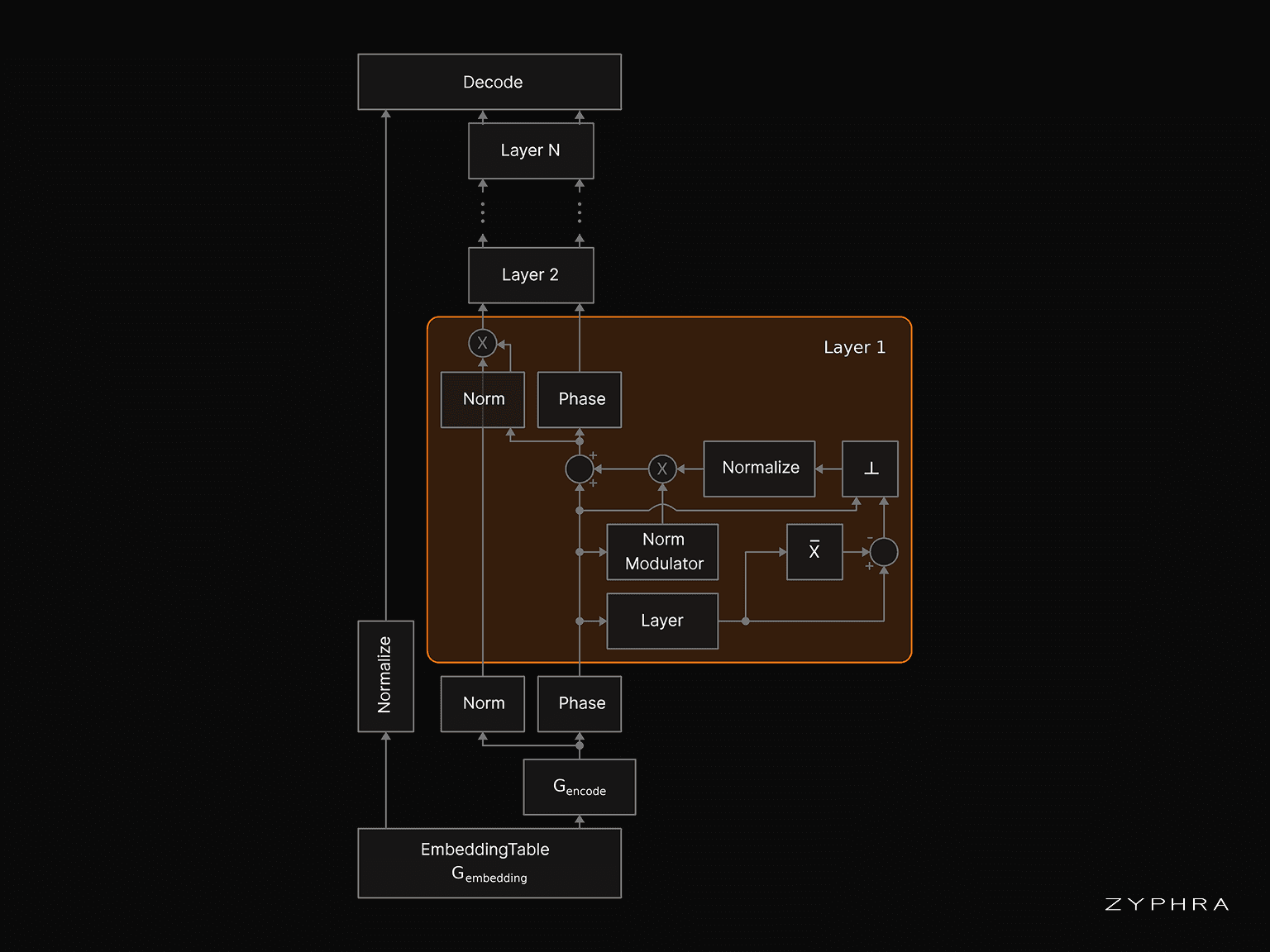
Schematic of the norm-agnostic architecture. The residual stream is decomposed into separately propagated norm and direction components. Each layer operates only on the direction component: it computes an update, removes its mean, orthogonalizes it with respect to the incoming residual-stream direction, re-normalizes it, applies norm modulation, and adds the resulting direction update back into the direction-only residual stream. The induced norm increase is then transported to the norm lane.
NAG tightly controls the geometry of the residual stream. Instead of treating the residual stream as a single vector whose magnitude and direction are entangled, NAG separates it into two components: a phase lane and a norm lane. The phase lane stores the normalized direction of the residual stream: the high-dimensional representational content that each layer reads from and updates. The norm lane stores the accumulated residual-stream scale separately and transports it through the network as a scalar gain.
This separation also improves the numerical structure of the computation. The high-dimensional phase lane is repeatedly re-normalized so that it remains bounded, reducing the numerical issues that come from carrying a rapidly growing residual vector through depth. Meanwhile, the norm information is preserved in a separate scalar lane, where it can be tracked accurately and cheaply, for example in high precision or log space.
The NAG residual update is designed so that each layer makes a calibrated change to the residual direction. First, the layer computes an update from the normalized residual direction. NAG then centers this update to zero mean and removes the component parallel to the current residual direction, leaving only the orthogonal component. Finally, this orthogonal update is normalized and scaled by a learned layer scale and an input-dependent norm-modulator gain.
Because the update is orthogonal to the current residual direction, the layer’s contribution has a clean geometric interpretation. Adding the update increases the squared norm of the phase vector by a controlled amount; NAG then transports this induced gain to the norm lane and re-normalizes the phase lane. The net effect is a calibrated change in the residual direction, rather than an unconstrained write into an ever-growing stream.
Intuitively, we can think of the NAG update as follows: each layer asks, given the current direction of the residual stream, how much should I move it, and in what orthogonal direction?
This prevents layer updates from becoming norm-blind perturbations that compound through depth. Instead of writing an unconstrained vector into an ever-growing stream, each layer applies a calibrated directional update whose relative effect is controlled.
At decoding time, the final residual direction is compared to normalized embedding vectors, while the accumulated norm acts as an inverse temperature. From the perspective of NAG, the residual norm is not an incidental byproduct of depth. It becomes a learned confidence-like inverse-temperature signal.
Results
We evaluate NAG on a series of MoE Transformer models with matched total parameter counts and matched forward-pass parameter counts. We vary the width-to-depth ratio so that some models are shallower and wider, while others are deeper and narrower.
The loss figure below shows that NAG achieves lower training loss than the corresponding baseline across all tested configurations. The improvement is visible at every width-to-depth ratio: NAG reduces loss by 0.0118 at ratio 80, 0.0189 at ratio 60, 0.0220 at ratio 40, 0.0219 at ratio 30, and 0.0285 at ratio 20. The largest gains appear in the deepest configurations, matching the core hypothesis: if residual norm growth reduces the impact of deeper layers, then mitigating this effect should matter more as depth increases.
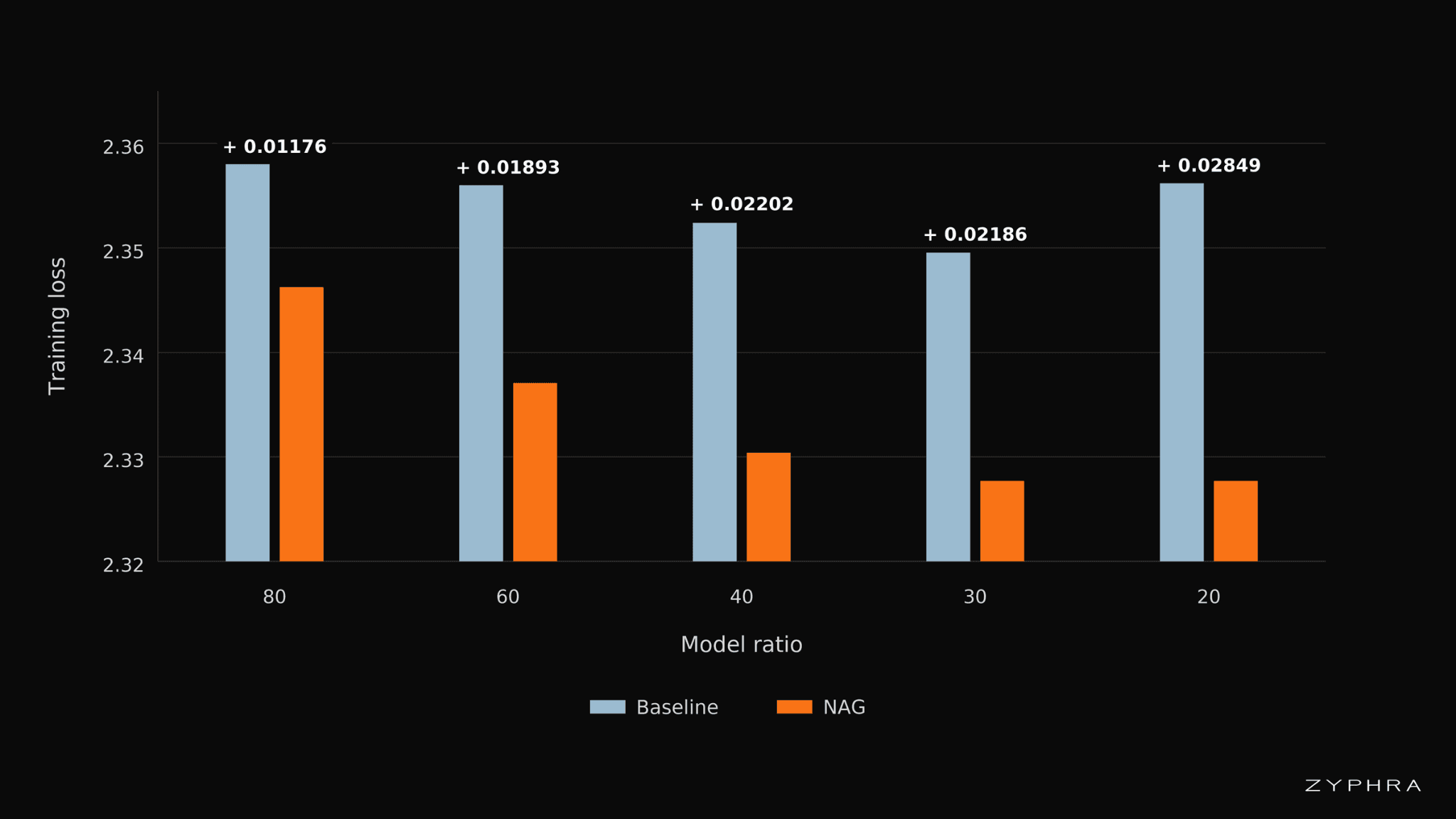
Training losses for the baseline and norm-agnostic MoE models across model ratios. Labels above each pair report the loss difference, computed as baseline loss minus NAG loss. NAG improves over the baseline at every model ratio, with the largest gain observed in the deepest configurations.
We also measure how much the residual stream rotates as tokens move through the network. This is a proxy for whether added layers continue to meaningfully change the representation, rather than behaving like near-identity maps. In the NAG models, cumulative rotation grows much more consistently with depth, suggesting that additional layers continue to contribute useful representational change. In the baseline models, cumulative rotation grows more weakly, consistent with later layers becoming progressively less effective. This is the behavior we would expect if NAG gives deeper layers a more equal opportunity to affect the residual state.
NAG also substantially reduces uncontrolled residual-stream norm growth. In our ablations, standard residual models can reach residual-stream norms more than two orders of magnitude larger than their NAG counterparts. For the model ratio of 80, the baseline residual-stream norm reaches roughly 120× the corresponding NAG norm, as shown in the norm and cumulative-rotation figure below. This level of norm growth in the baseline case implies that later layers must either substantially upweight their outputs by orders of magnitude or else become effectively irrelevant.
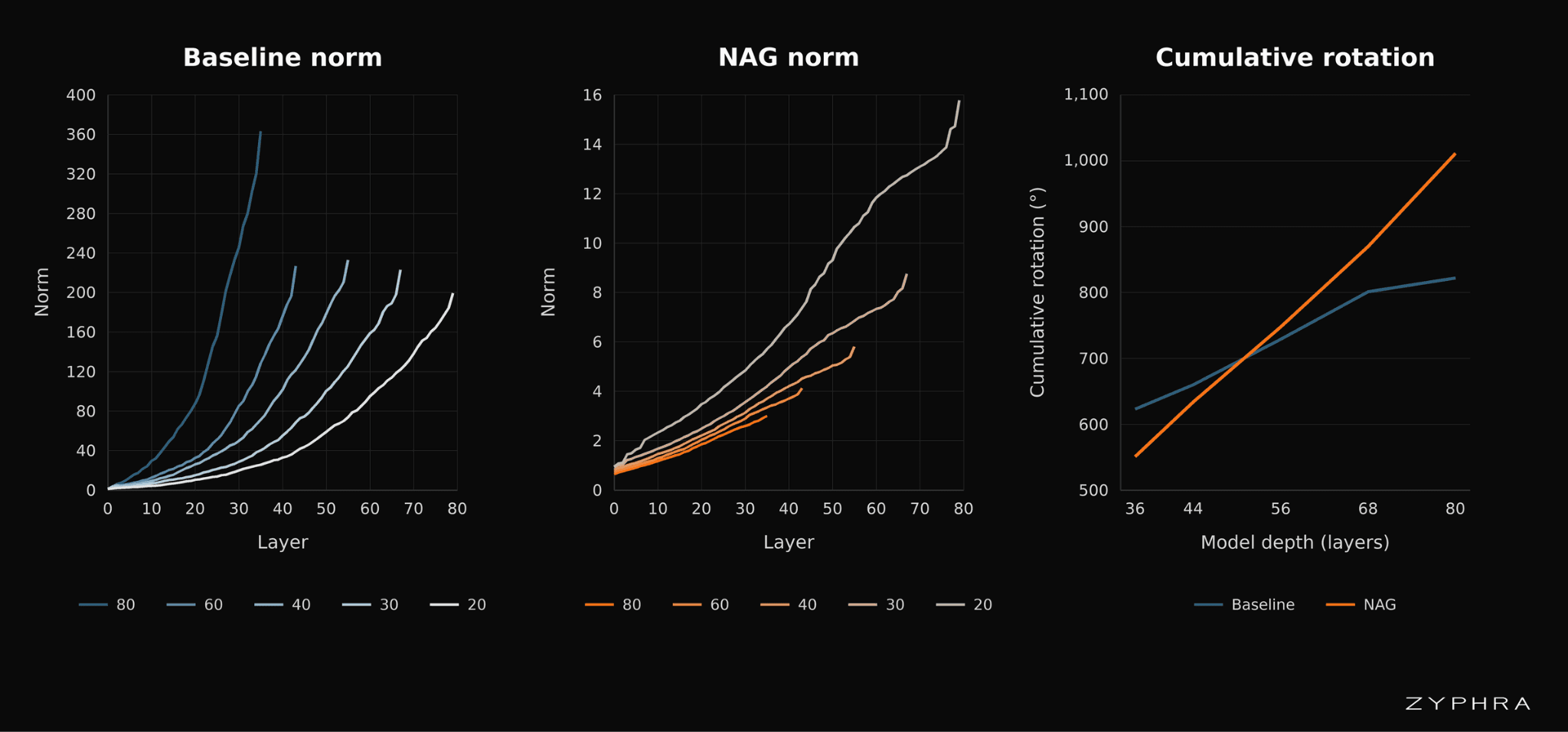
Layer-wise norms and cumulative embedding rotation across model depths. Left: baseline norm values for model ratios 80, 60, 40, 30, and 20. Middle: NAG norm values for the same ratios, shown on a different y-axis scale. Right: average cumulative embedding rotation, in degrees, with and without NAG.
From norm-agnostic residual streams to adaptive depth
Once each layer’s contribution has a geometric interpretation, a new possibility emerges.
Before computing an expensive layer, NAG can estimate how much that layer is allowed to rotate the residual stream relative to that layer’s own maximum possible rotation. This depends only on the current residual direction and the layer’s lightweight norm modulator. If this rotation is very small, then computing the full layer is unlikely to meaningfully change the model state.
This gives a natural criterion for Mixture-of-Depths (MoD).
Standard MoD methods typically use a learned router to decide whether a token should execute a layer. In NAG, the routing score has a direct meaning: it measures the fraction of the layer’s maximum possible rotation that would be realized for the current token.
If the token lies in a region of residual space where the layer is predicted to contribute only a small rotation, the layer can be skipped. If the token lies in a region where the layer is expected to strongly rotate the residual stream, the layer is executed.
This makes adaptive depth interpretable. The model is not skipping layers because of an opaque routing score. It is skipping layers because the residual-stream geometry indicates that those layers would have only a small effect on the current state.
Hard skipping, however, can create a sharp discontinuity. Just below the threshold, a layer would contribute nothing; just above it, the full layer computation would suddenly be executed. To make this transition smoother, we add a learned fallback direction. When a layer is skipped, the model still contributes a cheap learned direction controlled by the same norm modulator. This gives skipped layers a lightweight substitute contribution while preserving the compute savings.
The result is a dynamic computational path through depth. Some tokens may skip many layers, while others may use more of the model’s serial computation. This gives us a direct way to make depth sparse: many layers exist, but not every token needs to execute each one of them.
The key question is whether this sparse use of depth preserves the benefits of depth. We test that next.
Results: sparse depth without losing the benefits of depth
We test NAG-MoD by skipping attention blocks, MLP/MoE blocks, and both block types together. Loss increases gradually as the skip rate grows, showing that both attention and MLP/MoE computation can be made sparse token-wise without catastrophic degradation.
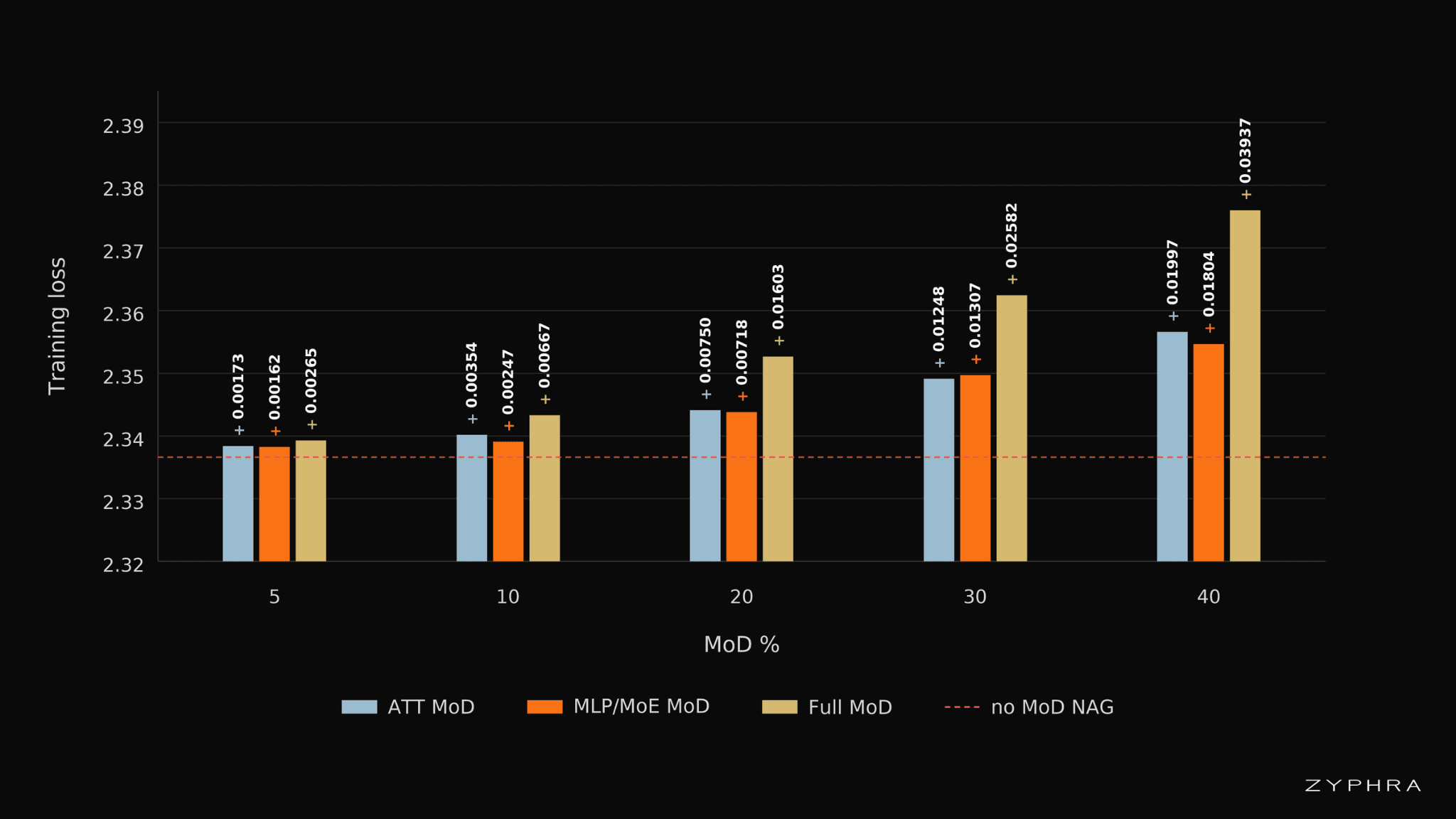
Training losses for attention-only, MLP/MoE-only, and full MoD ablations across different skipping percentages. The no-MoD baseline loss is 2.33661. Labels above each bar report the loss increase relative to the baseline. We observe that increasing the MoD skipping rate on a fixed model size (and thus decreasing FLOPs) leads to a small but roughly linear increase in loss. In NAG models, skipping attention leads to roughly the same loss increase as skipping MLP/MoE.
We then compare NAG-MoD against a router-based MoD baseline. NAG-MoD achieves substantially lower loss at every skip rate. The advantage becomes especially large at high skip rates, achieving a loss difference of 0.0671 for the highest skipping rate of 40%, indicating that geometry-based depth routing is a better criterion than a generic learned router in this setting.
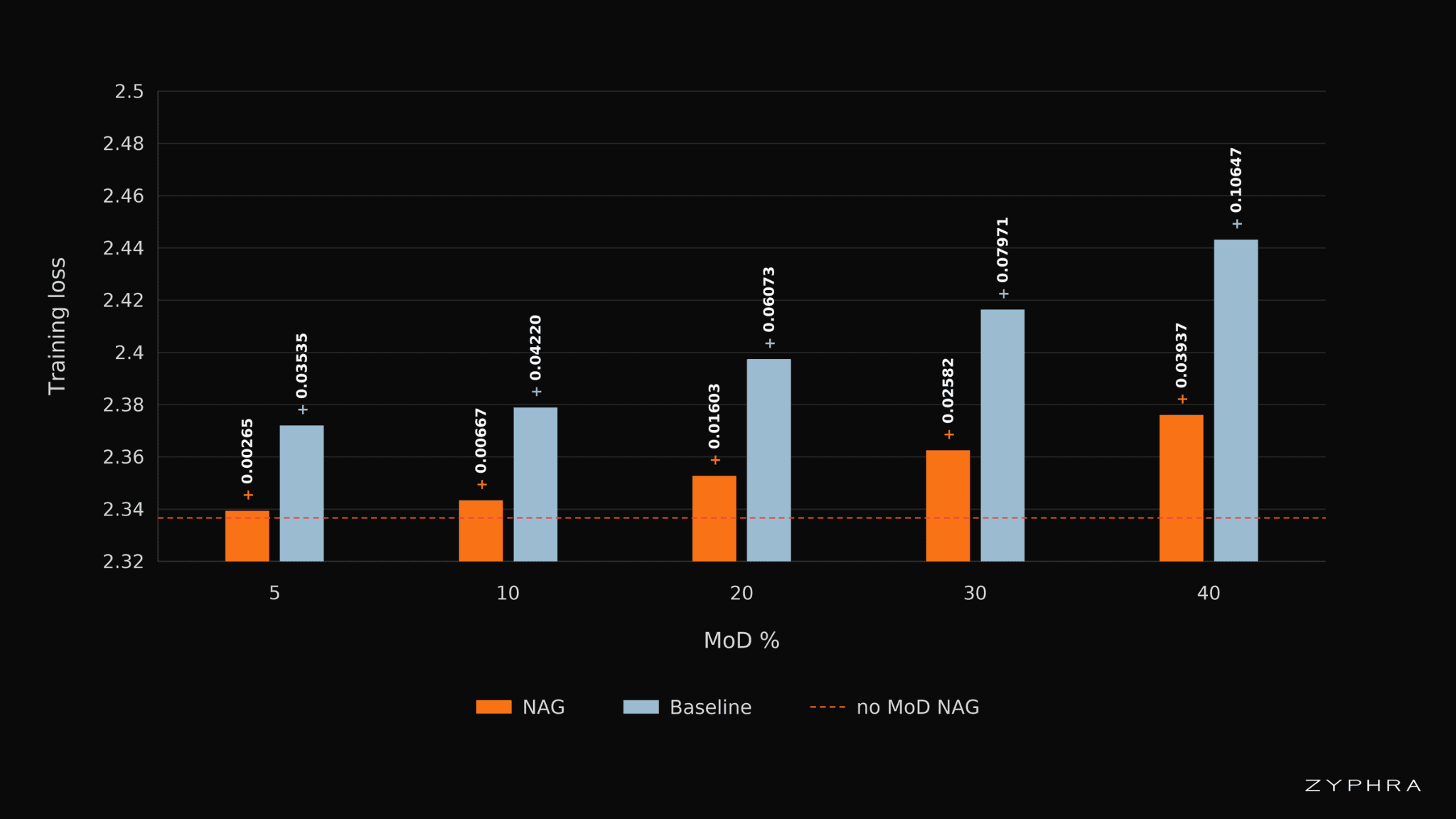
Training losses for NAG and baseline. The no-MoD NAG loss is 2.33661, and the corresponding BASELINE loss is 2.35539. Labels above each bar report the loss increase relative to the no-MoD NAG model.
This matters because MoD is usually framed as an inference-time accuracy-compute tradeoff: skip layers to make the model cheaper, accepting some degradation. NAG changes this picture by making the degradation from sparse depth much smaller.
If skipping reduces the per-token cost of the forward pass, then under a fixed training-compute budget, the saved compute can be reinvested into training on more tokens. We test this directly in iso-FLOP pretraining ablations. At 20-25% MoD, NAG-MoD essentially matches the no-MoD baseline under the same training compute, while reducing both the forward pass compute and executed forward-pass parameters.
This suggests that sparse depth can be a pretraining-time scaling strategy, not merely a post-training compression trick. Instead of treating depth as a fixed cost paid equally for every token, NAG-MoD lets the model allocate serial computation where it is most useful.
Mixture-of-Experts made it possible to scale width sparsely: many parameters exist, but only a subset are activated for each token. NAG-MoD points toward the analogous idea for depth: many layers exist, but each token only uses the amount of serial computation it needs.
Why this matters
NAG is not just a normalization change. It is a novel way of thinking about and controlling the fundamental geometry of a model’s representations in the residual stream. This perspective opens several broader directions.
First, NAG gives the final residual norm a functional interpretation. Since decoding compares the final residual direction to normalized embeddings, the accumulated norm acts as an inverse temperature. A high norm produces sharper predictions; a lower norm produces higher-entropy predictions. This suggests that confidence can be represented directly in the residual dynamics rather than being an uncontrolled byproduct of activation scale.
Second, NAG reduces attention-sink behavior and reduces pathologies associated with large residual norms, including activation outliers. In standard softmax attention, probability mass must always be allocated somewhere, even when an attention layer’s useful contribution to the residual stream should be small. This can encourage the model to route excess attention mass to early sink tokens. In NAG, the model has another option: the norm modulator can suppress the layer’s contribution to the residual stream. This gives the model a learned “do little” mode that does not require routing attention mass to a fixed sink.
Third, NAG makes compute allocation within the model more explicit. Each layer has a measurable expected contribution to the residual state. This could be used not only for layer skipping, but also for adaptive precision, KV-cache sparsification, expert routing, or recurrent computation.
Fourth, NAG suggests a route toward models that are sparse in both width and depth. MoE chooses which experts to use. NAG-MoD chooses which layers to use. Combining these two axes could allow future models to allocate compute far more precisely across tokens, tasks, and reasoning steps.
Our broader goal is to build models that maximize intelligence per FLOP and are not constrained by the architectural limitations of standard transformers.
Today’s language models often externalize difficult computation into chains of tokens. They reason by writing intermediate text and then reading it back. This is powerful, but it forces computation through a discrete token bottleneck.
A more efficient model would be able to perform long, dynamic computations directly inside its continuous residual state. It would allocate more internal computation to hard tokens, less computation to easy tokens, and reuse a fixed set of learned operations for as many steps as needed.
NAG is one of the core stepping-stones toward this idea. By making layer contributions norm-agnostic and enabling sparsity in depth, it points toward architectures that can use much deeper, more dynamic computation while remaining efficient enough to train and deploy.
In the long run, we aim to move toward architectures that behave less like fixed-depth feedforward stacks and more like efficient differentiable computers operating in residual space: systems that can execute variable-length vector programs, allocate compute dynamically, and scale inference computation without requiring every intermediate step to pass through natural language.