
Research
San Francisco, California
Zyphra Research studies the loss of the ability to learn after continued training—loss of plasticity—in GPT-style decoder-only Transformers. We discover that models with 5M to 314M non-embedding parameters lose plasticity when trained on a multilingual continual learning problem, as measured by deterioration on a held-out probing task.We derive a scaling law predicting that the onset of plasticity loss scales sublinearly with the number of non-embedding parameters. This prediction implies that scaling the number of parameters to prevent plasticity loss has diminishing returns and may be an inefficient approach to addressing the problem. In addition, we demonstrate that plasticity loss also occurs during stationary learning, suggesting that current approaches to training large language models are similarly susceptible to plasticity loss. Our work indicates that loss of plasticity might be a key bottleneck for full continual learning of LLMs.
Introduction
Continual learning is a fundamental frontier for language models, whose usefulness depends on their ability to adapt to new data, facts, domains, languages, codebases, and user needs. For example, continual learning could help mitigate knowledge cutoffs and allow coding agents to adapt to new repositories without relying entirely on in-context learning via long prompts. Moreover, continual learning is ultimately necessary for models to grow and improve indefinitely beyond a fixed and finite context window. However, training models with continual learning capabilities remains out of reach. One of the main obstacles to continual learning is the phenomenon of plasticity loss, in which a network loses its ability to learn as training progresses. This means that simply naively continuing to train a model on new data is doomed to grind to a halt.
Recent studies on plasticity loss¹ have demonstrated the phenomenon across an increasingly wide range of learning problems and network architectures. However, these works have primarily studied extremely small networks by modern standards and focused on older architectures. The study of plasticity loss in the natural language domain with Transformer-based architectures has been surprisingly limited. While there is initial evidence that Transformer-based models may be susceptible to plasticity loss, a systematic study of the phenomenon is still missing in the literature, as well as whether it is phenomenologically similar or different to plasticity loss in prior model types.
We make three important contributions to the study of plasticity loss in LLMs. First, we show that, indeed, plasticity loss occurs in GPT-style Transformer architectures trained on a multilingual continual learning problem. We observe measurable and consistent effects of plasticity loss in models ranging from 5M to 314M non-embedding parameters. Second, we formulate a scaling law that predicts the onset of plasticity loss scales based on the number of parameters. Our scaling law implies that scaling up the model may be an inefficient approach to preventing plasticity loss, although for large models we predict that plasticity loss may take a long time to manifest. Lastly, we show evidence that plasticity loss also occurs in stationary learning problems which are more realistic for modern pretraining. This result demonstrates that the prevalence of plasticity loss extends beyond the nonstationary task-switching approaches usually used to induce plasticity loss, implying that the core phenomenon is highly general and thus is important to ameliorate.
A Continual Learning Problem for Studying Plasticity Loss in Natural Language
First, we design a task paradigm to probe the extent of plasticity loss in modern LLMs using naturalistic data. For this, we need a continual learning problem using natural language suitable for LLM training. We design with three criteria in mind:
The data should be natural-language, overcoming the shortcomings of previous studies using synthetic datasets.
The sequence of tasks should be extendable indefinitely to enable the training length required to observe measurable effects of plasticity loss.
The tasks should be naturalistic and challenging enough for scale to result in meaningful improvements in performance.
With these considerations in mind, we created the Multilingual Continual Learning Problem. In this problem, a network is trained on a sequence of next-token prediction tasks. Each task corresponds to a different language. The problem cycles through the following languages in order: English, written Chinese, French, Japanese, Spanish, German, Portuguese, and Russian. Each task consists of 5 billion training tokens.
To evaluate the network’s ability to learn from completely new data, we perform a probing task at the end of each cycle. The probing task consists of a next-token prediction problem on Vietnamese using 5 billion training tokens. In effect, we perform a new training run on Vietnamese and measure the validation loss at fixed points during training. Probing is performed on a copy of the model checkpoint, and the resulting parameter updates are discarded afterwards. In this way, Vietnamese data is observed only during probing and, from the network's perspective, is always new.

Models are trained on repeated cycles of eight language-modeling tasks. At the end of each cycle, plasticity is assessed using a held-out Vietnamese probing task.
Results: Plasticity Loss in Transformer Models
We train GPT-style Transformer models ranging from 5M to 314M non-embedding parameters on the Multilingual Continual Learning Problem for several cycles. The performance metric is the area under the validation loss curve (AUC) for the probing task after each cycle. To compare across models, we normalize by the AUC of the first probing task and report results as percentage changes relative to the first cycle. Positive values indicate higher AUC than in the first cycle, corresponding to worse probing performance, whereas negative values indicate lower AUC and improved probing performance.

Percentage change in validation-loss AUC on the probing task relative to the first cycle for models ranging from 5M to 314M non-embedding parameters. All the models eventually exhibit an increasing trend in AUC, indicating a reduced ability to learn the probing task and providing evidence of plasticity loss. However for larger models we observe plasticity loss to occur after considerably more cycles.
In most models, the AUC initially decreases with the number of cycles, indicating greater ability to adapt to new data due to transfer learning from the previously learned languages. However, as the cycles continue, all models show an increase in AUC, indicating that the network has a reduced ability to learn from new data; it is experiencing plasticity loss. Over many cycles, this loss of plasticity tends to overwhelm the transfer learning benefit eventually resulting in worsened overall performance.
The model's scale produces two distinct effects. First, large models have greater ability to transfer from continual pretraining data to new data. For example, the 53M model has a 0.5% improvement in AUC, while the 314M model has an improvement larger than 1.5%. Second, the model's size delays the onset of plasticity loss. For instance, the 5M model shows an increase in AUC immediately after the first cycle, whereas the 106M model experiences the increase after the eighth cycle.
Results: Scaling Law for the Onset of Plasticity Loss
Based on results across different model sizes, we developed a scaling law to predict the onset of plasticity loss as a function of the number of non-embedding parameters in the model. To determine the onset of plasticity loss, we first estimated the task after which the AUC started to increase. Then, we fitted a log-log model predicting the onset of plasticity loss, \(T\), based on the number of non-embedding parameters, \(P\), resulting in the scaling law:
\(T = 1.3 \times 10^{-5} \cdot P^{0.8269}\)
The scaling law predicts that the onset of plasticity loss scales sublinearly with the number of non-embedding parameters. The implication of this prediction is that while increasing the number of parameters delays the onset of plasticity loss, there are diminishing returns to this approach for preventing its effects.
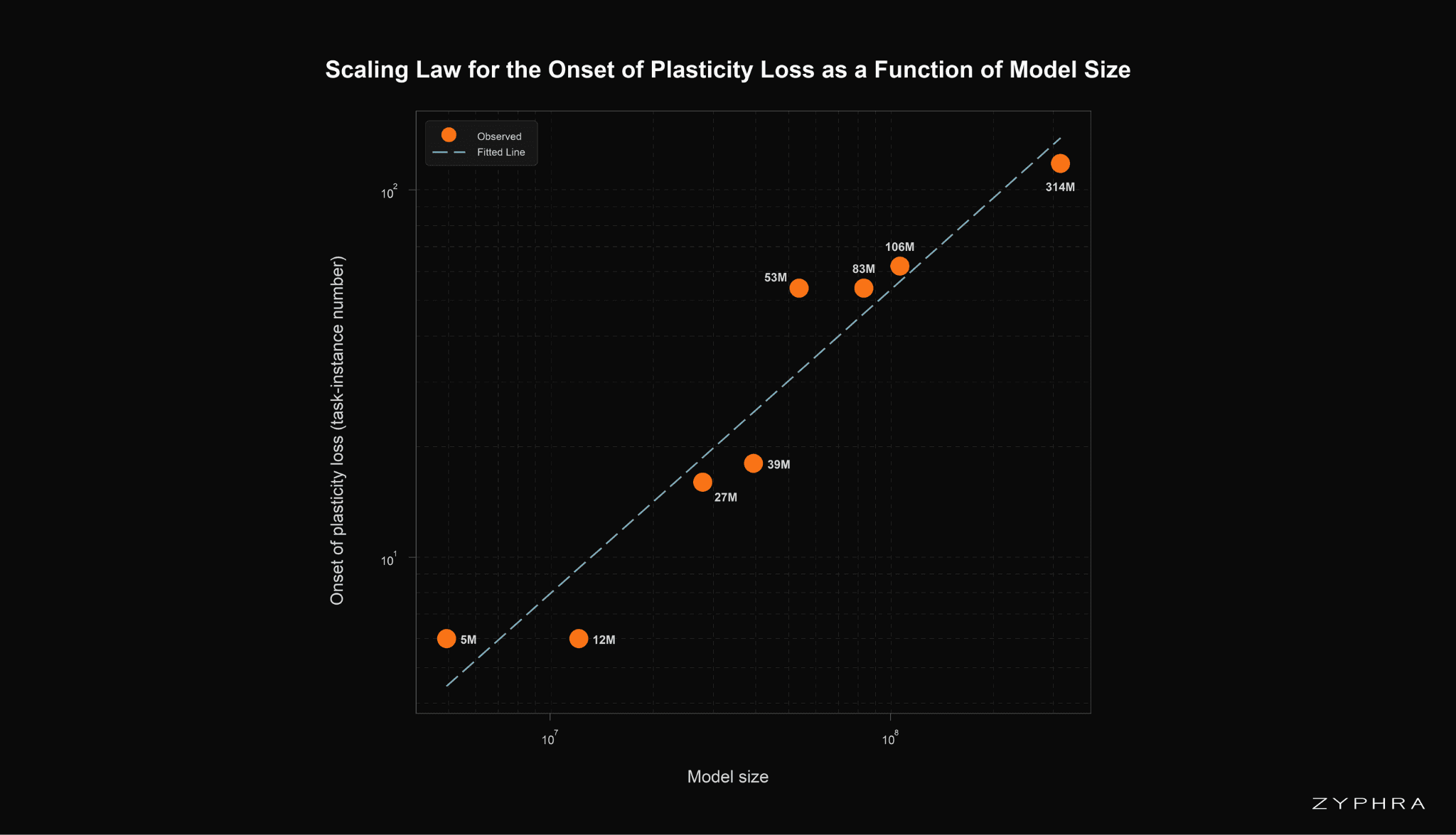
Log-log scaling law predicting the onset of plasticity loss, measured in number of task instances, as a function of model size. The onset of plasticity loss scales as \(T = 1.3 \times 10^{-5} \cdot P^{0.8269}\), where \(P\) is the number of non-embedding parameters.
Results: Plasticity Loss in Stationary Learning
Our log-log model generates predictions consistent with previously published results in the stationary learning setting. Previous work has shown that one-billion-parameter models have reduced fine-tuning performance when pretrained for longer than two trillion tokens. Consistent with this observation, our scaling law predicts that a one-billion-parameter model would show plasticity loss after 1.8 trillion tokens. This led us to investigate whether plasticity loss could be observed during learning from stationary data. While less in-line with prior loss of plasticity works which usually use non-stationary tasks, it is more realistic for the LLM training regimes common today at the frontier.
For this experiment, we combined the data from all eight languages in a cycle to create a single stationary dataset, which we refer to as the Multilingual Stationary Learning Problem. We then trained the 5M, 12M, and 27M models until observing measurable effects of plasticity loss. At regular intervals during pretraining, we created a copy of the checkpoint of the model and trained on the Vietnamese probing task, discarding the updates afterwards. This way, we created a metric for how well the network adapted to new data, analogous to the one used in the continual learning problem.

Percentage change in validation-loss AUC on the probing task relative to the first probing task during training on the Multilingual Stationary Learning Problem. As the number of training tokens increases, the AUC of all three models eventually increases, indicating a reduced ability to learn from new information.
The results in the stationary setting were strikingly similar to the ones in the continual learning setting. Initially, all the models show greater ability to adapt to new data for a fixed number of training tokens, showing transfer learning. However, as the training tokens increase, the models show an increasing trend in AUC, implying plasticity loss even in the stationary ‘pretraining-like’ case. These results imply that plasticity loss is not exclusive to continual learning and can occur as a consequence of extended training on stationary data. This indicates that it is not sudden data distribution shifts that cause loss of plasticity but something fundamental to the training process itself.
Why This Matters
Our demonstrations of plasticity loss in continual and stationary learning, together with our scaling law, have broad implications for the development of large language models.
First, our results show that LLMs are not immune to plasticity loss. At every scale that we studied, we found evidence that GPT-style Transformers eventually lose their ability to learn when trained continually. This implies that plasticity loss is a fundamental obstacle for the development of LLMs that can continually learn and will remain so until it is directly addressed. Moreover, it implies that plasticity loss is not constrained to the small networks and somewhat artificial settings used in earlier literature, but is a broad general, and possibly fundamental property of neural networks and their training dynamics.
Second, our scaling law suggests that increasing the number of parameters is an inefficient way to prevent plasticity loss. For a fixed number of tokens, increasing the Transformer model's parameter count removes the measurable effects of plasticity loss at the expense of higher computational costs and diminishing returns. In the case of a continuous and unending stream of new data, addressing plasticity loss through model scaling alone appears to be insufficient, although for extremely large models plasticity loss may take a surprisingly long time to set in.
Lastly, our results in the stationary learning setting demonstrate that plasticity loss is a more general phenomenon than previously thought. The implication is that even modern large language models may be experiencing plasticity loss, losing their ability to learn from new data as they are trained on an increasingly large number of tokens. Moreover, this occurs not in an academic far-off limit, but at practical numbers of pretraining tokens for small models, although generally above the number of tokens recommended for compute-optimal pretraining.
Our findings warrant attention from the broader community studying and developing large language models. Our scaling law predicts that scale alone cannot save us from plasticity loss. The stationary learning results suggest that loss of plasticity is not an artifact of small networks, outdated architectures, or unusual training setups, but rather a fundamental and general property of neural network training. Together, these results point to plasticity loss as an overlooked bottleneck in large language model training.