
Research
Palo Alto, California
We demonstrate a retrieval system extending any off-the-shelf LLM to 1B (billion) context on a standard CPU during inference time. In this post, we share results demonstrating that our approach (novel retrieval method based on sparse graphs) achieves SoTA performance on the Hash-Hop benchmark, which requires reasoning over elements in an ultra-long context.
Our model excels up to 1 billion context (and beyond), is more compute & memory efficient compared to common RAG systems that use dense embeddings, and is more efficient than long-context transformer-based LLMs.
These preliminary results suggest our algorithm is a promising approach for performing long-context tasks especially in compute constrained scenarios (on device, cost-effective on-prem & cloud etc).
Nick Alonso, Beren Millidge
Introduction
An important and open problem in AI is building LLMs that can effectively use long contexts. Long-contexts allow LLMs to learn from large datasets at inference time via the LLM’s in-context learning abilities, rather than during an expensive pre-training phase that tunes parameters.
Building effective long-context LLMs could, for example, allow for LLMs that can summarize, reason over, and answer questions about vast inputs such as code bases or books without the need to alter the model’s parameters.
Current state-of-the-art transformer-based LLMs with long-context (e.g., Google’s Gemini-1.5 at 1M tokens) often perform well on long-context benchmarks, but have the significant drawback of requiring enormous compute, since they use attention layers whose compute cost increases quadratically with context length. This cost limits scalability & deployment flexibility where compute is limited (on-device, cost constrained on-prem etc).
State space models (SSMs) offer a more computationally efficient alternative to transformers, but are known to struggle on certain important categories of task (e.g., recall and in-context learning) relative to transformers. At Zyphra, we have also been addressing this challenge with hybrid SSM-transformer models which can achieve the majority of the speedup of pure SSMs while counteracting their weaknesses with a few carefully selected attention layers. However, SSM-hybrids do still maintain some attention and hence its quadratic cost. In addition, for extremely long context, even the linear forward pass per token of a large model can be computationally prohibitive.
A new alternative model, called the Long-Term-Memory (LTM) model, recently presented by the start-up Magic, is purportedly 1000x cheaper than transformers with naive attention and can process very long contexts on a single H100 GPU. The LTM model was shown to perform well on a new long-context benchmark, “Hash-Hop”, on up to 100 million tokens. Though promising, the LTM model is not open-sourced or accessible and is said to require a full rewrite of the inference and training stack.
At Zyphra, we are exploring using RAG as an effective, efficient, and simple alternative for long-context tasks. In this post, we extend our prior work and present a RAG system that can solve the Hash-Hop task for inputs of at least 1 billion tokens. Our RAG system inputs only a small subset of the long context into the LLM generator making language generation highly compute and memory efficient. Further, we go beyond prior applications of RAG to long-context tasks (e.g., here) by focusing on generating vector databases for retrieval quickly at test time, while simultaneously dealing with complex reasoning tasks, like Hash Hop, through the use of a novel, sparse graph-based retrieval method.
Sparse text embeddings allow us to generate embeddings quickly and run a variant of our previous personalized page-rank graph retriever entirely on the CPU. The result is a RAG system that uses very little memory, is highly compute efficient, and outperforms Magic’s LTM on the Hash-Hop benchmark.
These preliminary results suggest our algorithm is a promising approach for performing long-context tasks, especially in compute constrained scenarios. Because our algorithm is so computationally efficient, it can process effectively unlimited contexts, and we demonstrate strong performance up to 1B context – a 1000x increase over the current leading long-context systems such as Google’s Gemini.
Challenges for the RAG Approach to Long-Context Tasks
When attempting to apply RAG to long-context tasks, there are two central challenges:
The challenge of fast test-time text embedding: RAG models first chunk text, then embed the chunks in a vector database, usually using a transformer-based embedding model. In a typical setting, the embedding step happens before deployment, then during deployment, the same database is repeatedly and efficiently searched as queries are presented. Long context tasks, on the other hand, require processing a query and a long input document (e.g., an entire book along with questions) at test time, which means the embedding must also be done at test time and the cost cannot be amortized across many queries. Since the user expects an immediate response, the embedding process must be fast to be practically useful. However, the process of embedding text chunks using standard transformer-based embedders can be slow.
The challenge of retrieval for complex tasks: Classic RAG methods, which utilize a flat search over a vector database, work well on standard QA and retrieval tasks: the model is queried about some content X, then text chunks most related to X are retrieved. However, many long-context tasks are more complex than this (e.g., summarization and reasoning) and require linking together elements of the input document that may not be directly related to the content of the query, making accurate retrieval difficult.
Fast Effective RAG Using Sparse Graphs
To address these challenges, we propose combining the use of sparse embedding methods with graph-based retrieval; in particular:
We generate sparse embeddings of text chunks and use these to create sparse graph representations of the text data, which represent relations between text chunks. The advantage of these sparse embeddings is a small memory footprint, very fast embedding generation, and sparse linear algebra operations that can be performed efficiently entirely on CPUs.
Building on our prior work, during retrieval, we use graph representation to execute an algorithm similar to personalized pagerank (PPR) – a graph-based search and ranking method used originally by Google search. As we explain below, using graph-based retrieval allows for the retrieval of text chunks that have more indirect, complex relationships to the query, and are more likely to be important for reasoning tasks.
Testing on the Hash-Hop Dataset
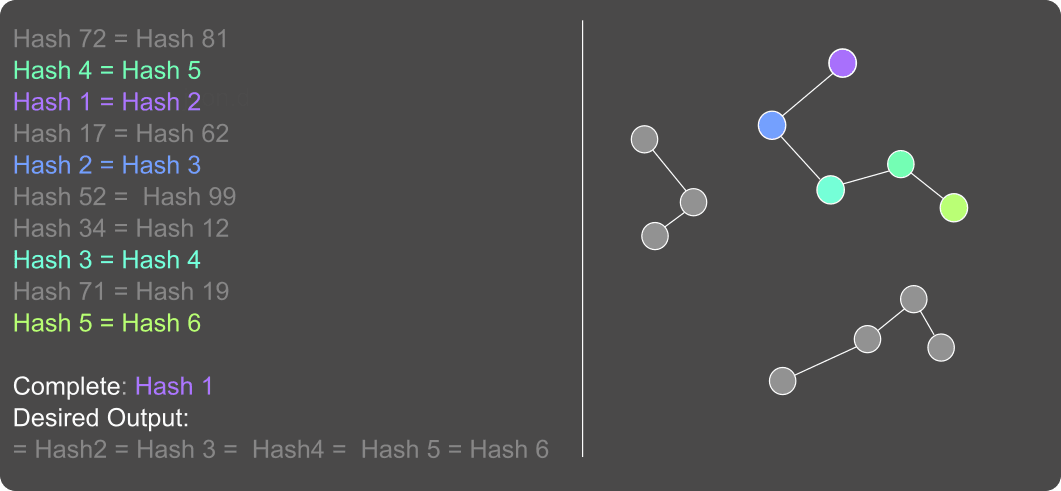
Figure 1: Left: visualization of hash-hop task. A list of hash assignments are presented, then the model is queried with one hash, in this case Hash 1. The model must then output all hashes that are equal to this hash. This task thus requires a kind of transitive reasoning over the long-context.
Right: The relation between hashes can be represented through a graph, where linked nodes are those hash-assignments that share at least one hash. During retrieval, text chunks linked to and nearby the query in the graph will be retrieved, while those lacking a path to the query and those not near the query in the graph will not be retrieved.
We provide evidence for the effectiveness of our approach on the Hash-Hop task, recently introduced by Magic. The Hash-Hop task requires performing transitive reasoning over synthetic hash assignments of the form ‘Hash1 = Hash2,..., Hash2 = Hash3, ...’, where the actual hashes are random combinations of characters. The model is presented with a document of hundreds of thousands or millions of tokens worth of hashes and a query which gives a starting hash. The model must then respond by listing all hashes that were directly or indirectly assigned to the starting hash. For example, given Hash1 the model must output ‘Hash1=Hash2=Hash3=...’ (see figure 1).
Standard RAG systems will fail at this task (see below), since when presented with the query, e.g., ‘Hash1’ standard retrievers will only retrieve text directly related to Hash1 and miss those hash assignments transitively/indirectly related to Hash1.
However, graph-based retrieval methods that retrieve both directly and indirectly related items should be able to solve this. As shown in the figure above, the relations between hash assignments are naturally represented as a graph, which can be utilized by a graph-based retrieval process, like the one we implement, to retrieve all the relevant hashes, while ignoring those without relation to the starting hash.
We implement and test a standard vector search model that uses sparse embeddings (std-RAG-Sparse) and our sparse personalized-page rank based retriever (PPR-RAG-Sparse). Both RAG systems only retrieve 65 items from memory, which amounts to only several thousand tokens. RAG models use gpt-4o-mini as the language generator to take in the retrieved text chunks and output the desired hash chain. A small few-shot prompt is provided, so the LLM knows what to do. We compare the results to Magic’s long-term memory language model (Magic-LTM), as reported in their blog post.

Figure 2: The accuracy of basic RAG with sparse embeddings (std-RAG-Sparse), our sparse graph-based RAG (PPR-RAG-Sparse), and the accuracies reported by Magic for their LTM. Our method all but matches Magic’s LTM up to 16M tokens, and outperforms it at 50M-100M tokens. Further, unlike the LTM, our model’s performance does not degrade beyond 16M, even solving the task at 1B context length. Note, due to time limitations, we only test 15-40 questions for the 100M-1B range, whereas we test on 100 questions for smaller lengths to reduce time. This may also explain why we see almost perfect scores at 1B, whereas we get slightly less at smaller lengths: there is more opportunity for the LLM to introduce noise in larger test sets.
We see that, as predicted, the base RAG model fails at Hash-Hop tasks that require more than one ‘hop’ of indirect hash assignments to be retrieved. However, our sparse PPR-RAG model performs close to perfect on the task up to and including 1 billion input tokens, all but matching Magic’s LTM at context lengths up to 16M and outperforming the LTM at lengths greater than 16M. Magic did not test their model on lengths past 100 million tokens, but their results show LTM model performance was trending downward after 16M tokens. It is reasonable to suspect this downward trend would continue to 1 billion, whereas performance of our model remains constant.
These results are significant since Magic’s LTM model was likely trained directly to perform this task and was reported to require re-engineering of the ‘full-stack’ utilized in training just to implement and train the model. Our method, on the other hand, requires no such re-engineering, is compute efficient and requires very little memory, and does not touch the LLM component at all, entirely preserving its language capabilities.
The Computational Cost of RAG
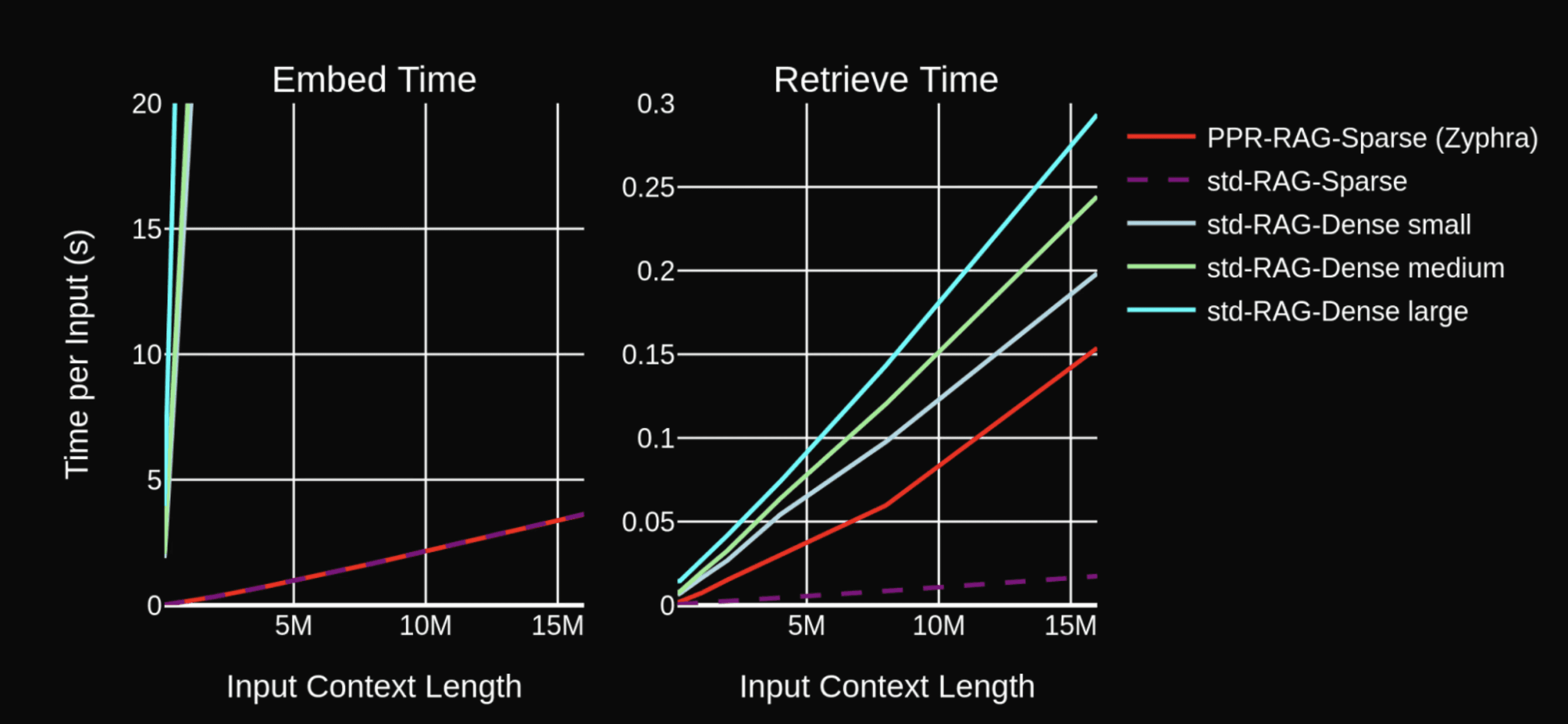
Figure 3: The embedding and retrieval time for our sparse embedding approach vs standard RAG dense-embeddings. Dense embeddings take substantially longer time to embed the full context even at relatively short sequence length. Our sparse embeddings by contrast run on the CPU and can utilize the vastly greater CPU RAM efficiently while also running significantly faster. The baseline dense RAG models use FAISS flat search to perform retrieval.
In the figure above, we compare the computational cost of our RAG system to more standard methods that use dense embeddings generated by BERT-style semantic embedders. We show both the wall clock time it takes for these systems to embed text of various lengths and to retrieve from it.
We test three RAG systems using the following three state-of-the-art dense embedders:
‘thenlper/gte-small’ – 33M parameters (std-RAG-Dense small)
‘Alibaba-NLP/gte-base-en-v1.5’ – 130M parameters (std-RAG-Dense medium)
‘Alibaba-NLP/gte-large-en-v1.5’ – 500M parameters (std-RAG-Dense large)
The embedding models are run on a RTX 4090 GPU, and text chunks are batched with sizes optimized for wall clock time, and fed through the models to get the embeddings. We use the standard FAISS library flat indexes for retrieval from the dense vector databases. We compare these models to the sparse PPR retriever and sparse Base retriever used in the last section.
All methods perform retrieval in a small fraction of a second. Importantly, the PPR retriever is fast despite requiring more computations (e.g., numerous matrix multiplies) in its graph retrieval mechanism than the flat vector search of the other methods. Due to the fact that our method can leverage sparse matrix multiplies on the CPU, we can even demonstrate slightly faster speeds than FAISS flat vector search over a dense vector database.
However, BERT embedders embed text chunks much more slowly than the sparse embedding algorithm we used, and the time it takes to embed increases at a faster rate than it does for the sparse methods. The sparse embedder, which uses a symbolic program to extract keyword statistics, is very fast even at longer context lengths, requiring only several seconds to generate embeddings at 16+ million input tokens.
Conclusion
We believe utilizing sparse, graph based RAG models is a promising direction for dealing with long context tasks, especially in compute constrained scenarios such as on-device applications. We supported this claim by achieving state-of-the-art performance on Magic’s Hash-Hop long-context benchmark using a simple and novel sparse graph-based RAG algorithm, which can run fast and efficiently on a single CPU.
This model solved two core problems facing RAG systems for long-context tasks:
Rapid embedding of the input document without massive memory usage – our method uses sparse embeddings which can be generated very fast, require little memory, and work entirely on the CPU, avoiding interference with any LLM on GPU.
Retrieving sufficient information across multiple hops to solve challenging reasoning problems – we solve this using our graph-based retrieval method.
In future work, we plan to test the generality of our retriever on a wider variety of long-context tasks and provide a more detailed description of our algorithm.