
Research
Palo Alto, California
There has recently been growing interest in conversational agents with long-term memory which has led to the rapid development of language models that use retrieval-augmented generation (RAG). Until recently, most work on RAG has focused on information retrieval from large databases of texts, like Wikipedia, rather than information from long-form conversations. In this paper, we argue that effective retrieval from long-form conversational data faces two unique problems compared to static database retrieval: 1) time/event-based queries, which requires the model to retrieve information about previous conversations based on time or the order of a conversational event (e.g., the third conversation on Tuesday), and 2) ambiguous queries that require surrounding conversational context to understand. To better develop RAG-based agents that can deal with these challenges, we generate a new dataset of ambiguous and time-based questions that build upon a recent dataset of long-form, simulated conversations, and demonstrate that standard RAG based approaches handle such questions poorly. We then develop a novel retrieval model which combines chained-of-table search methods, standard vector-database retrieval, and a prompting method to disambiguate queries, and demonstrate that this approach substantially improves over current methods at solving these tasks. We believe that this new dataset and more advanced RAG agent can act as a key benchmark and stepping stone towards effective memory augmented conversational agents that can be used in a wide variety of AI applications.¹
Nick Alonso, Tomás Figliolia, Anthony Ndirango, Beren Millidge
Introduction
Conversational agents, such as chatbots, personal assistants, and language interfacing operating systems, are currently seeing rapid development. One specific area of interest is conversational agents that utilize retrieval-augmented generation (RAG), which imbues LLMs with long-term memory. However, popular Question-Answering (QA) benchmarks that typically test RAG systems, focus primarily on information retrieval (IR) from a static database of texts, such as Wikipedia. The increasing importance of conversational agents raises the question of how to address the unique challenges RAG models face in conversational contexts that they do not in offline, database retrieval contexts.
There seem to be two crucial challenges conversational agents face that are not tested in most standard database retrieval benchmarks:
Conversational Meta-Data Based Queries: In conversational contexts, a common sort of query refers to meta-data (e.g. time, date, or speaker) associated with previous conversations. For example, one could plausibly ask "what were we discussing yesterday morning, again?", "what was that idea we were working on last time?", or "summarize what Jason talked about in our meeting from January 6th.". These questions are not specifying what was talked about, but are instead asking the model to specify what was talked about given some meta-data, such as the time of the conversational event.
Ambiguous Questions: In conversation, it is normal to speak with pronouns (he, she, it, they, etc.) and demonstratives ('this', 'that', etc.), which are ambiguous without an understanding of preceding conversational context. Although understanding this context is often trivial when this information is stored inside an LLM's context, such statements will fool the naive RAG systems as we discuss below.
We found that there is currently a lack of benchmarks that directly test models on both of these challenges simultaneously in conversational contexts. Further, current conversational LLMs that use standard vector database retrieval methods do not directly address these challenges.
To address these challenges, we at Zyphra
created a dataset that directly tests a retriever’s ability to retrieve relevant items from a chat log based on their meta-data, such as the time or data of the particular response.
developed an approach that combines both vector database search, SoTA table database search, and query rewriting to deal with the sort of questions presented in this dataset, as well as more standard datasets.
The Dataset
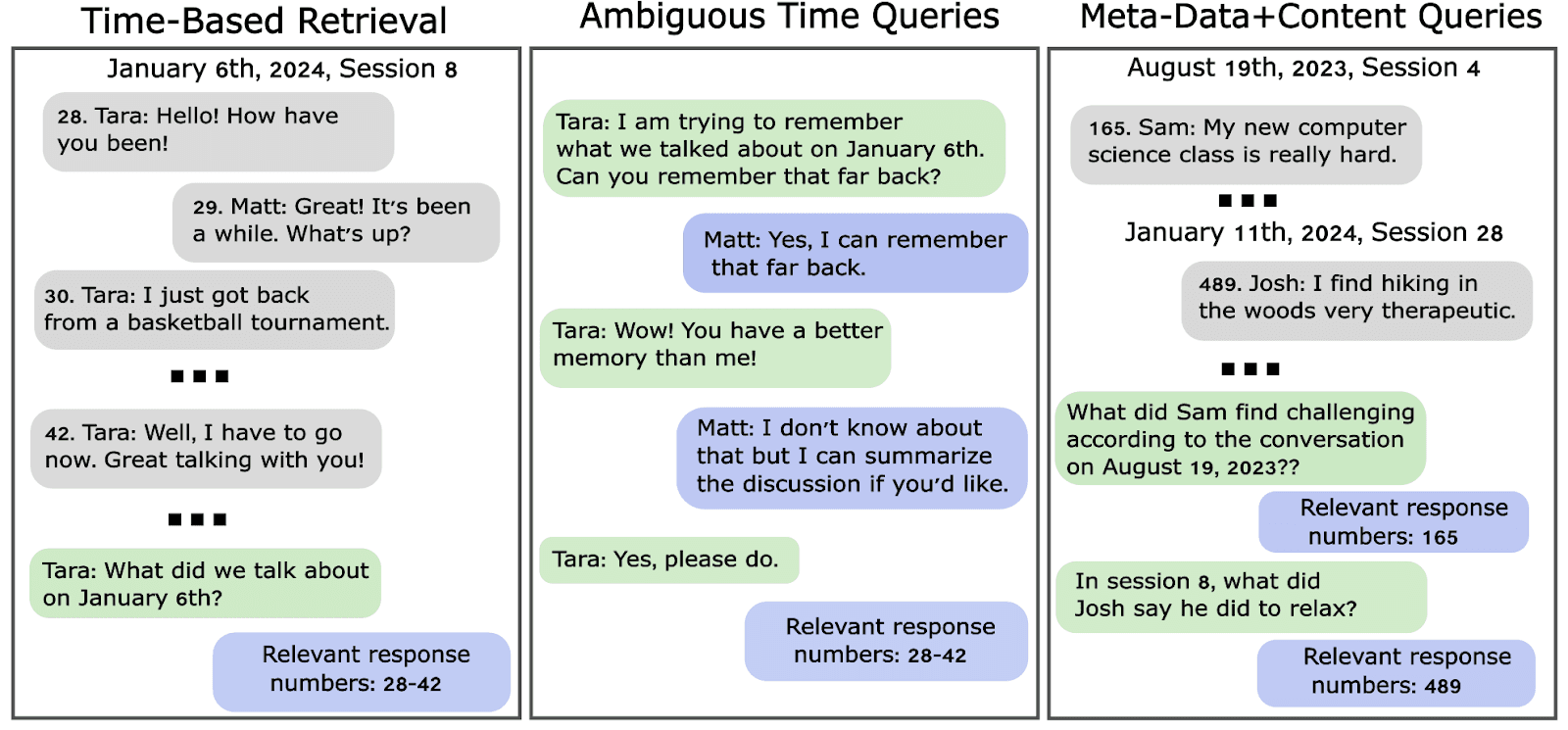
We created an open source dataset by augmenting an existing long-form chat dataset known as LoCoMo [1]. We used the open-source chat logs from the LoCoMo dataset and created three types of questions based on the chat-log.
Time-Based Queries: These sorts of questions refer directly, and only, to the timing of a conversational event. Examples include, “What did we talk about last Tuesday?”, “Summarize what we discussed on January 6th.”
Ambiguous Time Queries: These are ambiguous forms of the time-based queries. These begin by referencing the relevant time in conversation, then later asking a question like “Could you summarize what we discussed on that date?”
Meta-Data and Content Based Queries: These questions refer both to meta-data (.e.g, the time, or speaker) of chat text and the content of the text. These questions are set up so both sources of information must be used to accurately retrieve the correct text. For example, a question might be “In session 8, what did Josh say he did to relax?”
Our Approach
Vector database retrieval retrieves text chunks based on their semantic similarity to the query text. Vector search is the standard for RAG chatbots, but will not alone work for the sorts of questions in our dataset, which require retrieval based on the meta-data of the text. To deal with this issue we combine vector database search with a tabular search method known as chain-of-table.
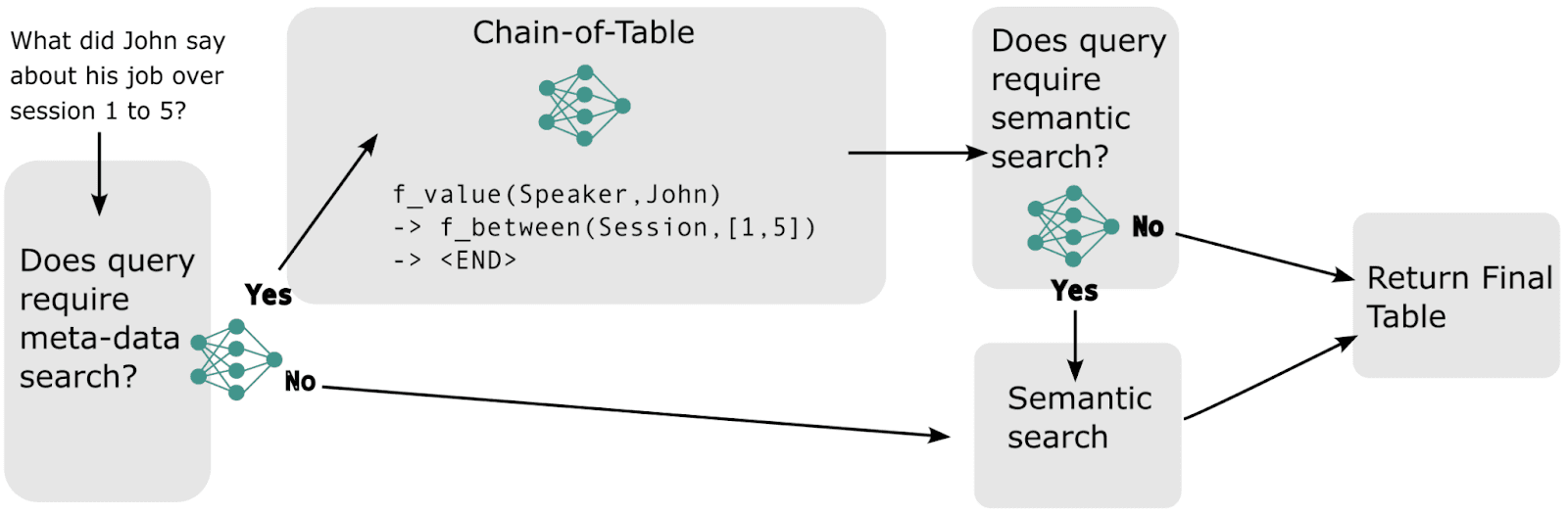
First, we store chat text in a table, where each row represents one response. Columns represent meta-data and store an index to the response’s associated semantic vector. Our retrieval algorithm performs the following steps to retrieve text
Use the LLM to decide whether the query is referring to meta-data.
If it is, then the model performs a SoTA LLM tabular search method known as Chain-of-Table (CoTable) to retrieve rows from the table with relevant meta-data. Then the LLM decides if a semantic search is also needed. If so it performs a semantic search of the text, otherwise it returns the retrieved text.
If the query is not referring to meta-data, the model does normal semantic search.
To deal with ambiguous queries, we also adapt SoTA query writing methods to our algorithm with promising results.
Results
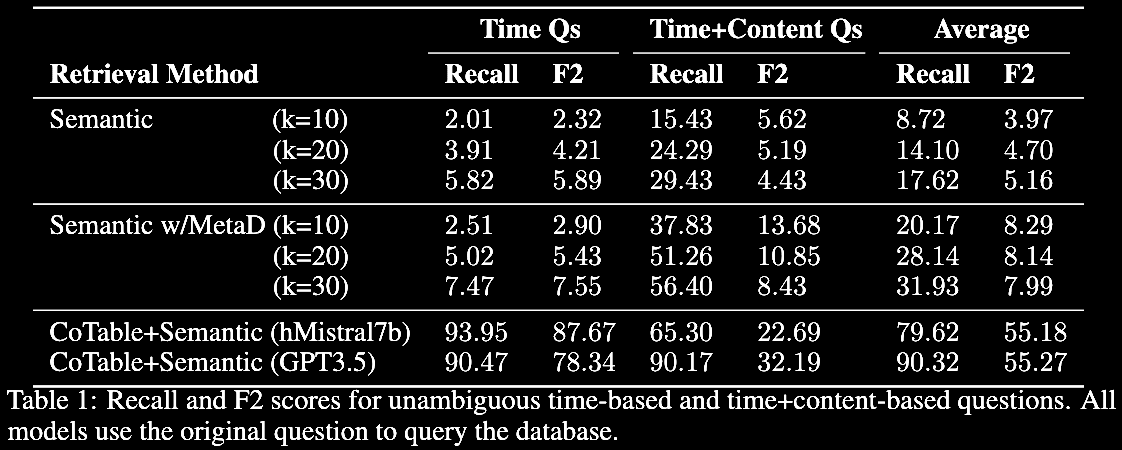
We find our CoTable+Semantic retrieval method significantly outperforms standard semantic retrieval methods.
We see that for both GPT3.5 and a Mistral-7b model, our method achieves almost perfect recall and very high F2 precision in the items it retrieves from memory, showing both that our method is retrieving the correct text from memory (recall) without retrieving extra irrelevant items (F2). This is unlike existing semantic-based retrieval methods which perform poorly since they are unable to handle time related metadata correctly.
For ambiguous queries, we find that augmenting this method with state of the art query rewriting methods, allows the model to perform almost as well as it did in the unambiguous questions case (see table 2).

Conclusion
An important capability for conversational agents is an understanding of when conversational events occurred in the past and an ability to handle ambiguous queries, which are commonplace in conversational contexts. We believe our dataset can be used as a basis to test how well various IR methods understand temporal and conversational context, and our empirical results suggest that our approach that combines chain-of-table and semantic retrieval methods makes a useful starting point.
References
[1] Maharana, A., Lee, D. H., Tulyakov, S., Bansal, M., Barbieri, F., & Fang, Y. (2024). Evaluating very long-term conversational memory of llm agents. arXiv preprint arXiv:2402.17753.