
Model
San Francisco, California
Zyphra is releasing Zamba2-VL, a family of open vision-language models built on the Zamba2 hybrid SSM–Transformer backbone available at 1.2B, 2.7B, and 7B parameters. The models are competitive in accuracy with leading open Transformer-based vision-language models at comparable scales while running substantially faster.
Hassan Shapourian, Kasra Hejazi, Olabode M Sule, Beren Millidge
Introduction
Zyphra is excited to release Zamba2-VL, a family of vision-language models built on the Zamba2 hybrid SSM–Transformer backbone. Zamba2-VL is available at three scales — 1.2B, 2.7B, and 7B parameters — and is competitive with the strongest open-weight Transformer-based VLMs of comparable size, while delivering roughly an order of magnitude lower time-to-first-token. Zamba2-VL demonstrates the potential of hybrid architectures in the visual domain. The full family is released under Apache 2.0 and the weights are available here.
Zamba2-VL Highlights
Three open releases: Zamba2-VL-1.2B, Zamba2-VL-2.7B, and Zamba2-VL-7B, covering the parameter ranges for easily deployed vision models.
Competitive accuracy: Across 14 benchmarks spanning chart, diagram, and document understanding, general perception and reasoning, and visual counting, Zamba2-VL is broadly competitive with the best Transformer-based open-weight VLMs in each band — and is notably strong at counting and on document and chart-style benchmarks.
Roughly an order of magnitude faster inference: Zamba2-VL inherits the predominantly linear-time prefill and fixed-size recurrent state of the Zamba2 backbone. At every scale, Zamba2-VL achieves competitive scores at roughly an order of magnitude lower time-to-first-token than the closest Transformer baseline.
First open VLM family on a hybrid SSM–Transformer LLM: To our knowledge, Zamba2-VL is the first VLM family built on a strong, fully open hybrid SSM–Transformer LLM, demonstrating that the efficiency profile of hybrid state-space LLMs translates productively into the multimodal regime.
Model Quality
Zamba2-VL is broadly competitive with the best Transformer-based open-weight models in each parameter band on standard vision-language benchmarks. Across image understanding, visual reasoning, OCR, grounding, and counting evaluations, Zamba2-VL holds its own against models built on dense Transformer backbones — frequently at smaller parameter counts and always at substantially lower inference latency.
The Zamba2-VL series performs exceptionally strongly on visual counting. On PixMoCount, Zamba2-VL-1.2B reaches 62.5, nearly double the score of the Transformer-based InternVL3.5-1B (32.8) and more than three times that of PerceptionLM-1B (17.7). The 2.7B and 7B variants continue this trend, with CountBenchQA scores of 87.5 and 90.6 that match or exceed all directly comparable Transformer baselines. Document and chart understanding also hold up consistently across scales, reflecting a deliberate decision to upsample document and OCR data during pretraining.
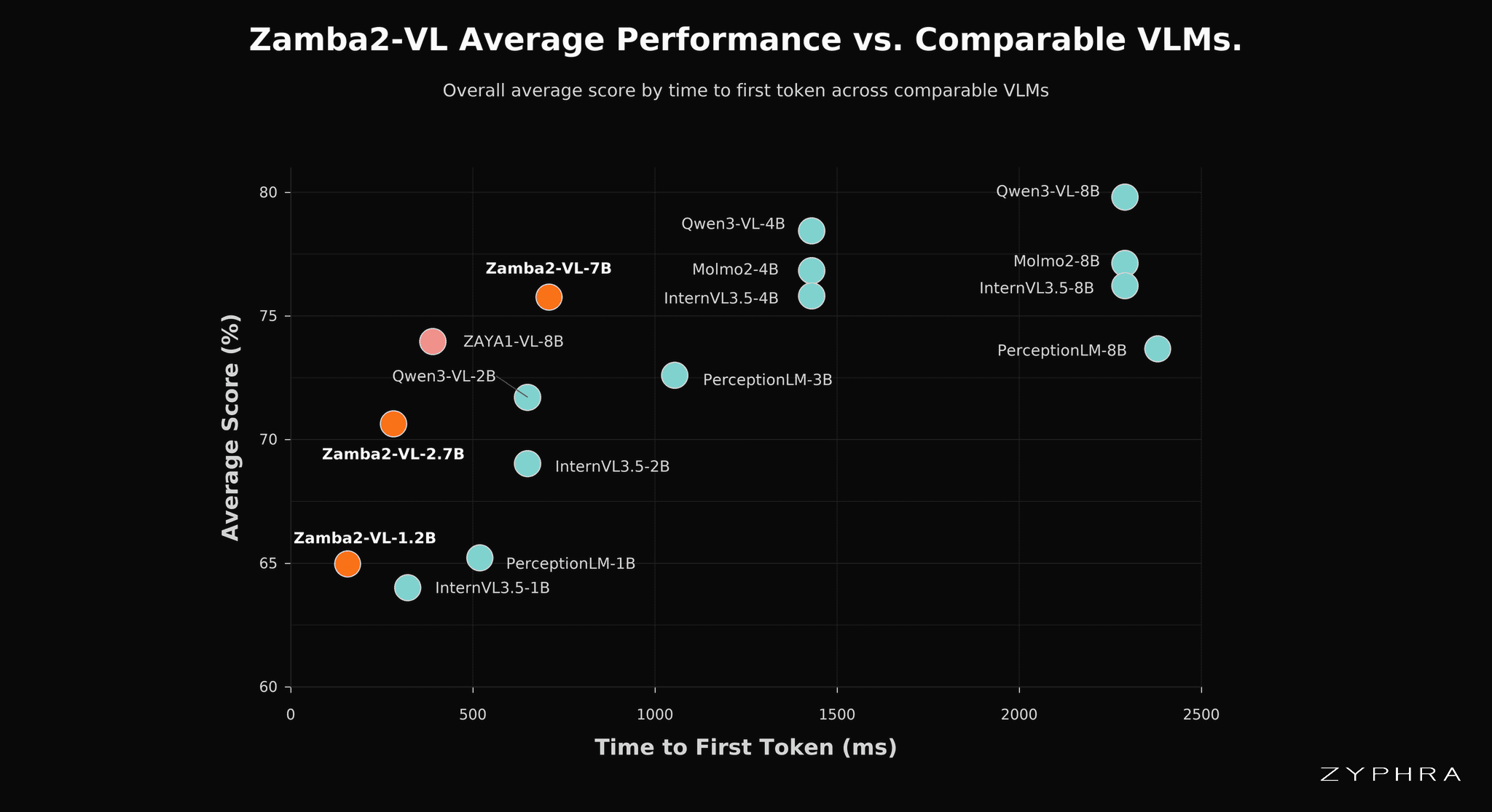
Performance of Zamba2-VL vs comparable models based on time-to-first-token (inference-efficiency). Aggregate score is reported here. For a full breakdown by evals please see the technical report.
A pattern that emerges across our evaluations is that Zamba2-VL's relative position improves with scale: the 1.2B model is competitive with leading 1B Transformer VLMs, the 2.7B is broadly mid-pack within a band that includes models 40–50% larger, and the 7B model is consistently competitive with the strongest 7–8B open-weight VLMs across nearly every category. We view this as an encouraging sign for scaling hybrid models further.
Inference Efficiency
Zamba2-VL’s principal advantage is in inference.The Transformer's quadratic attention scales poorly to the long token streams that arise in the multimodal regime. A single high-resolution image can contribute several thousand vision tokens, and a short video clip routinely produces tens of thousands of tokens. Zamba2-VL ameliorates this constraint by inheriting the near-linear-time prefill and constant-size recurrent state of its Zamba2 backbone, in place of the growing KV cache of attention.
On an 32k-token prefill — the latency-critical phase of inference, where attention's quadratic cost is felt most acutely — Zamba2-VL occupies the upper-left region of the score-vs-TTFT plot at every scale. No Transformer-based VLM in our comparison set matches the score of any Zamba2-VL model at comparable latency, and the latency gap is at least an order of magnitude in the regimes that matter most for serving. Moreover, our efficiency advantage is most pronounced at the 1.2B and 2.7B scales which is precisely the regime targeted for on-device and edge deployments
Architecture
Zamba2-VL follows the now-standard LLaVA-style VLM template where a pre-trained vision encoder produces patch-level features, a lightweight MLP adapter projects these features into the LLM embedding space, and the LLM consumes the resulting interleaved sequence of vision and text tokens. The Zamba2 LLM is a hybrid architecture in which a Mamba2 state-space backbone is interleaved with a small number of shared transformer blocks, each lightly specialized with a unique LoRA adapter at each layer. The hybrid architecture trades-off between the expressivity of full attention and the inference-efficiency of SSM blocks. The Mamba2 layers carry the bulk of the computation in linear time and constant state, while the shared attention layers preserve the in-context retrieval capability that pure-SSM models give up. The resulting 1.2B, 2.7B, and 7B Zamba2 LLMs are competitive with leading open-weight Transformer LLMs at their respective scales while being substantially faster at generation. We pair each Zamba2 backbone with the Vision Transformer from Qwen2.5-VL — chosen for its 2D rotary position embeddings and native dynamic-resolution processing — connected through a two-layer MLP adapter.
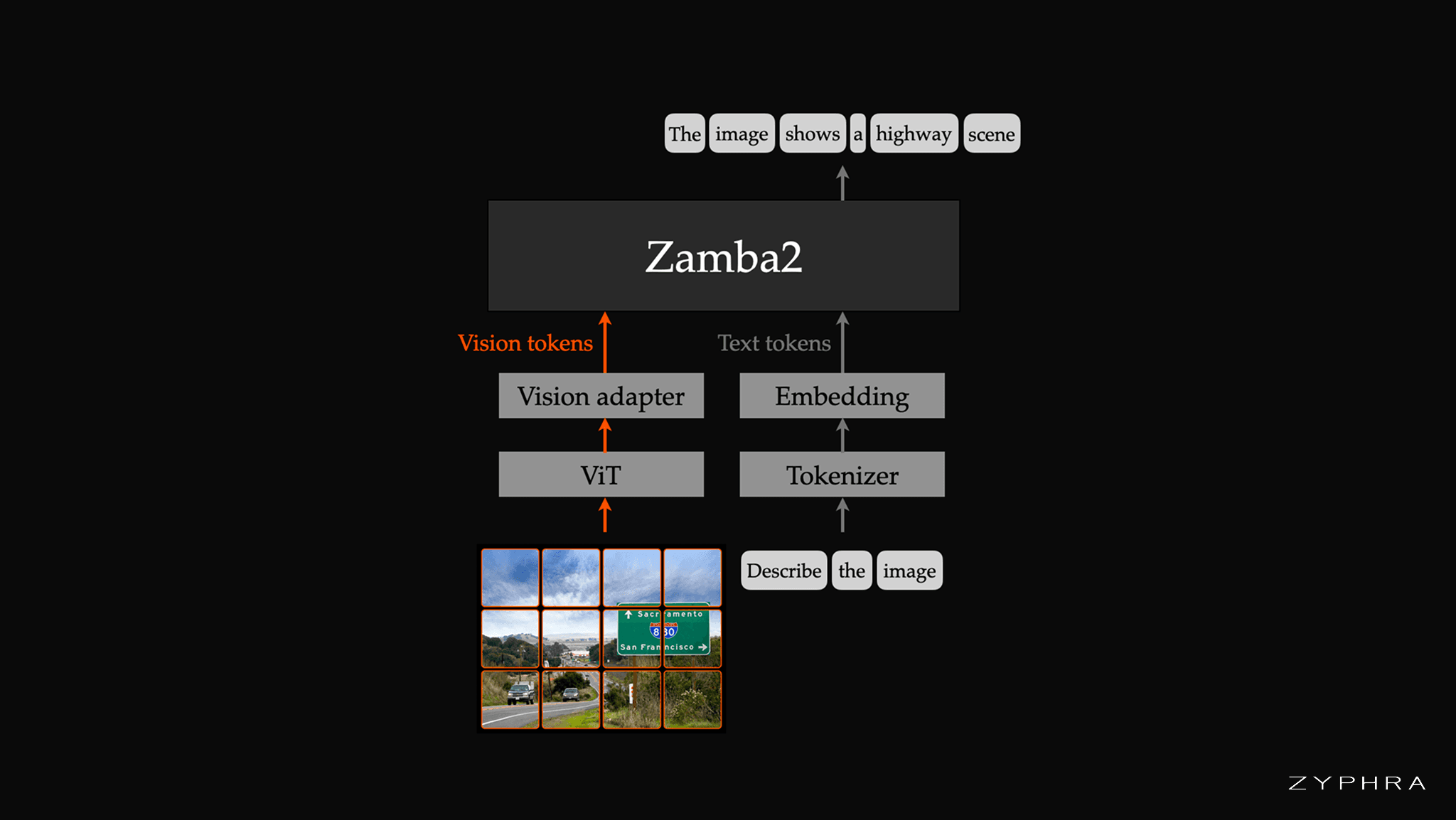
Schematic of the architecture of Zamba2-VL.
Adapting a hybrid SSM–Transformer backbone to a vision-language setting raises two design questions that do not have well-established answers. Firstly, which vision encoder to pair with the backbone, and secondly how to compose the multimodal training mixture. We ablated both, and one finding had a particularly large effect on the final pipeline: against a Llama-3.x Transformer reference at matched scale, Zamba2 backbones match or exceed the Transformer baseline on most general image-understanding benchmarks but lag on text-dense document and OCR tasks. Deliberately upsampling document and OCR data in pretraining closes this gap, and is reflected in Zamba2-VL's strong scores on DocVQA, ChartQA, and OCRBench at every scale.
Conclusion
Zamba2-VL is an important demonstration that the efficiency profile of hybrid sub-quadratic LLMs translates productively into the multimodal regime, and that the in-context retrieval limitations of pure-recurrence models can be largely sidestepped through a small amount of well-placed attention. We see hybrid SSM–Transformer LLMs as a practical alternative to dense Transformers as VLM backbones,particularly when memory or latency is a binding constraint at deployment.
We are releasing Zamba2-VL as a research artifact for the open community. The full family is available now under Apache 2.0:
Zamba2-VL Collection: https://huggingface.co/collections/Zyphra/zamba2-vl
Inference code: https://github.com/Zyphra/transformers/tree/zamba2-vl
For full architectural and training details, see our technical report.
We invite the broader research community to build on Zamba2-VL and explore where hybrid backbones can take open multimodal modeling.