
Model
San Francisco, California
Zyphra has released ZONOS2, an Apache 2.0-licensed real-time text-to-speech model high in expressiveness, with strong voice cloning, and a first-of-its-kind MoE architecture among open-source TTS systems.
Introduction
We are excited to announce ZONOS2, our next-generation real-time text-to-speech (TTS) model with high-fidelity voice cloning. ZONOS2 is a sparse Mixture of Experts (MoE) model with 900 million active parameters and 8 billion total parameters licensed under Apache 2.0. You can access ZONOS2 on Zyphra Cloud powered by AMD through our playground or via API.
Real-time high-fidelity voice cloning typically forces a tradeoff between quality and inference performance. ZONOS2 is our attempt to mitigate that tradeoff. We achieve extraordinary voice cloning fidelity while maintaining real-time TTS capabilities due to our MoE architecture plus substantial data scaling since ZONOS-v0.1.
ZONOS2 achieves state-of-the-art performance and is competitive with leading open-source TTS models on widely used open benchmarks such as seed-tts eval, as well as, on our own newly proposed ZTTS1-Eval benchmark. We encourage you to listen to the comparisons below. ZONOS2 performs especially well on speaker similarity and prosody metrics, a testament to the versatility and naturalness of its voice cloning capabilities.
Continuing Zyphra’s tradition of architectural innovations, ZONOS2 is also the first open-source MoE text-to-speech model, and uses a variant of our MoE++ architecture used in our ZAYA family of language models.
The ZONOS2 model weights are available on Hugging Face, and our mini SGLang based inference code is available on our GitHub.
ZONOS2 is also hosted on Zyphra Cloud powered by AMD. For a promotional period after release we are serving the model free of charge.
Model Comparisons
We present a qualitative comparison of a number of state-of-the-art proprietary and open-source models with ZONOS2 and using our new ZTTS1-Eval benchmark (described in detail below). These results capture the intelligibility, quality, voice-cloning performance and prosodic variation of model generations.
We believe the best way to evaluate a TTS model is qualitatively: by listening to the generated samples. With that in mind, we present a series of ZONOS2 samples alongside outputs from comparable open-source and proprietary TTS models:
Qualitative Comparison
Dwarkesh
"I guess what’s interesting is that it no longer has that synthetic, slop-y cadence you expect from these models. It actually feels like you're talking to a person, right? And maybe the M.O.E thing is actually doing a lot of work here. You get the feel of a much bigger model but with great realtime performance at the same time."





Trump
"Folks, nobody talks about Shinji Ikari the right way, okay? Nobody. They are all saying, oh, he's conflicted, he's emotional, he's hesitant, and I say, maybe. But let me tell you something: the kid got in the robot. A lot of people forget that very important detail. They said, Shinji, get in the robot, and eventually, he did. That's courage, folks. That's results. And his father, Gendo? Terrible guy. Really cold, not a people person. Bad father, bad vibes, bad glasses, everything about him is a problem. Shinji never got support, no encouragement. Nobody said, 'You're doing a fantastic job, Shinji.' They should have said it. Who knows things might have gone a lot better if they had."
British Female
"I must not overfit. Overfitting is the model-killer. Overfitting is the little loss that brings total generalization failure. I will face my loss. I will permit the gradient to pass backward over me and through me. And when it has propagated, I will turn the validation eye to see its path. Where the loss has gone there will be convergence. Only the learned representation will remain."
Parks and Recreation Guy
"You leak your test set? Straight to jail. No validation, no nothing. Data scientists, we have a special jail for data scientists. You overfit? Jail! You underfit? Also jail! Overfit, underfit. You normalize the training data but not the test data? Jail, right away. You tune hyperparameters on the leaderboard? Believe it or not, jail! You call it AI when it’s just logistic regression? Jail! You use a neural net for a problem solved by a decision tree? Jail! You forget to set a random seed? Jail! You set the seed but don’t log the experiment? Also jail! You say 'the model is 99% accurate' on an imbalanced dataset? Right to jail! You deploy without monitoring drift? Jail, immediately."
David Attenborough
"Here, in the dense and unforgiving wilds of synthetic speech, a rare new species begins to stir. This is Zonos 2: alert, expressive, and built for survival in places where lesser models falter. It has learned not from a single habitat, but from many — the steady rhythm of audiobooks, the chatter of podcasts, the pulse of conversation, and the many tongues of a multilingual world. Before any sound becomes part of its instincts, it must pass a trial: voices are detected, transcripts are challenged, and weak utterances are quietly left behind. What remains is clean, varied, and remarkably alive. Across languages and symbols that might confuse a simpler creature, Zonos 2 moves with confidence."
Arlechino
"So it turns out it’s not chlorover. It’s not chlorover at all. Zero distillation required: the talent was organic the whole time."
Obama
"That’s the thing about ambitious projects. They’re never just about the machine itself. The moon landing wasn’t just about a rocket. It was about what happened to our science, our industry, our confidence, and our sense of possibility when we chose to do something extraordinary. So yes, build the Gundam. Build it in Detroit, or Pittsburgh, or Houston, or wherever American workers are ready to show the world what they can do. Build it with union labor. Build it with American steel and American ingenuity. Build it in partnership with our universities and our private sector. And while you’re at it, make sure the technology that comes out of that effort helps us improve prosthetics, disaster response, construction, and national defense. Because that’s what America does at our best. We dream bigger than what seems practical. We turn imagination into industry. We transform science fiction into economic opportunity."
Quantitative Comparison
Regarding quantitative metrics, first, we demonstrate that ZONOS2 excels on measures of naturalness and high-fidelity voice cloning, focusing especially on prosodic naturalness and speaker similarity.
In terms of model stability measured by word-error-rate (WER), ZONOS2 is comparable with other leading open-source and proprietary TTS systems. However, there is an interesting nuance to these comparisons. When we actually plot the reported scores of other models against the ground truth values, we observe that most TTS models score substantially lower than the ‘natural’ error rate of the evaluating ASR model vs the actual ground truth text. This is not necessarily overfitting but instead reflects the fact that many TTS systems are trained to produce speech that is substantially ‘cleaner’ and more intelligible to ASR systems than actual human speech.
This ultimately means that there is a trade-off between achieving strong WER metrics and the voice cloning faithfully matching the vocal characteristics of the source clip. With ZONOS2 we chose to emphasize vocal fidelity, even when the source clip contains background noise, unusual voices, or other distortions, vs always producing extremely clean ‘studio quality’ speech.
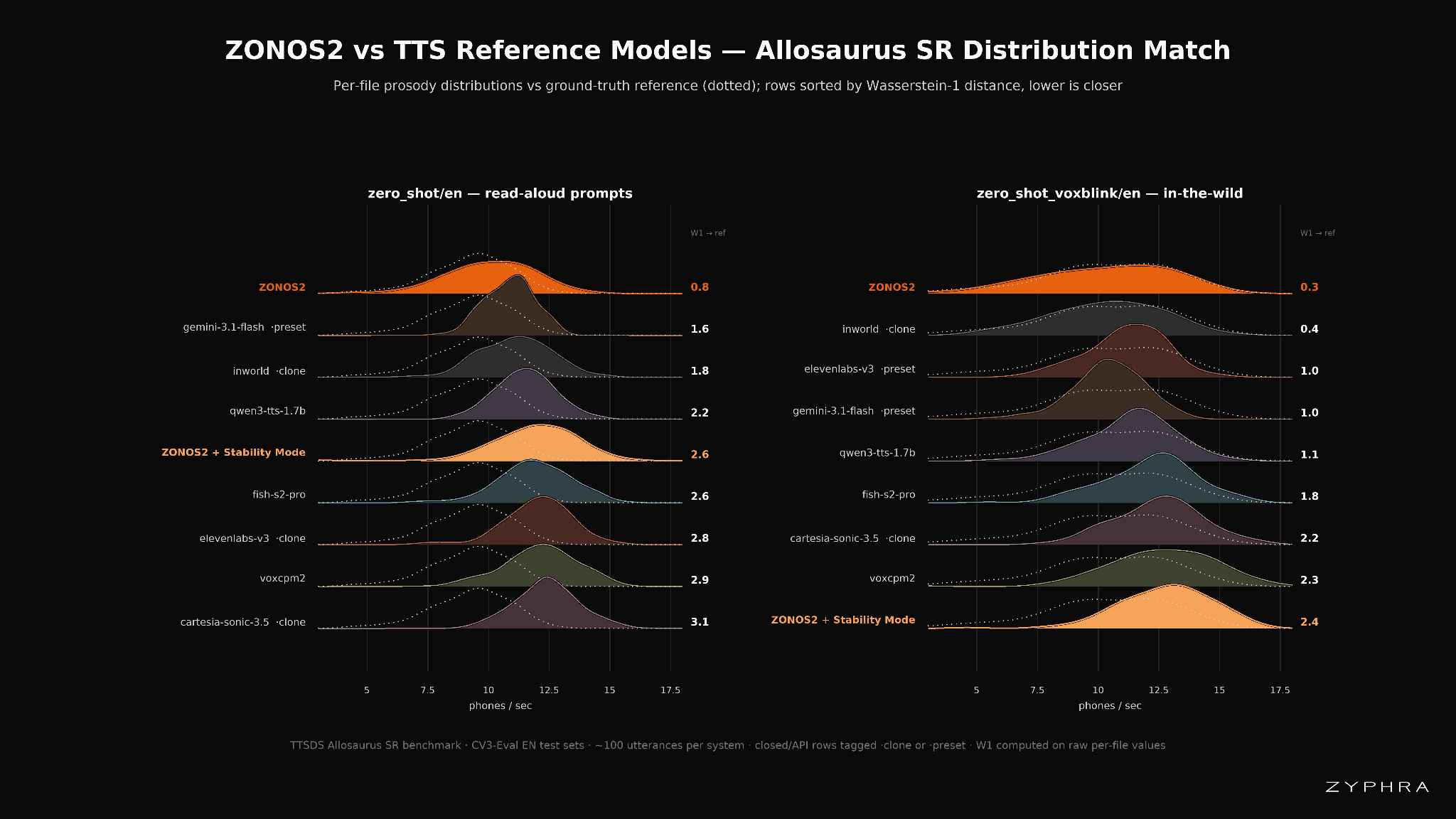
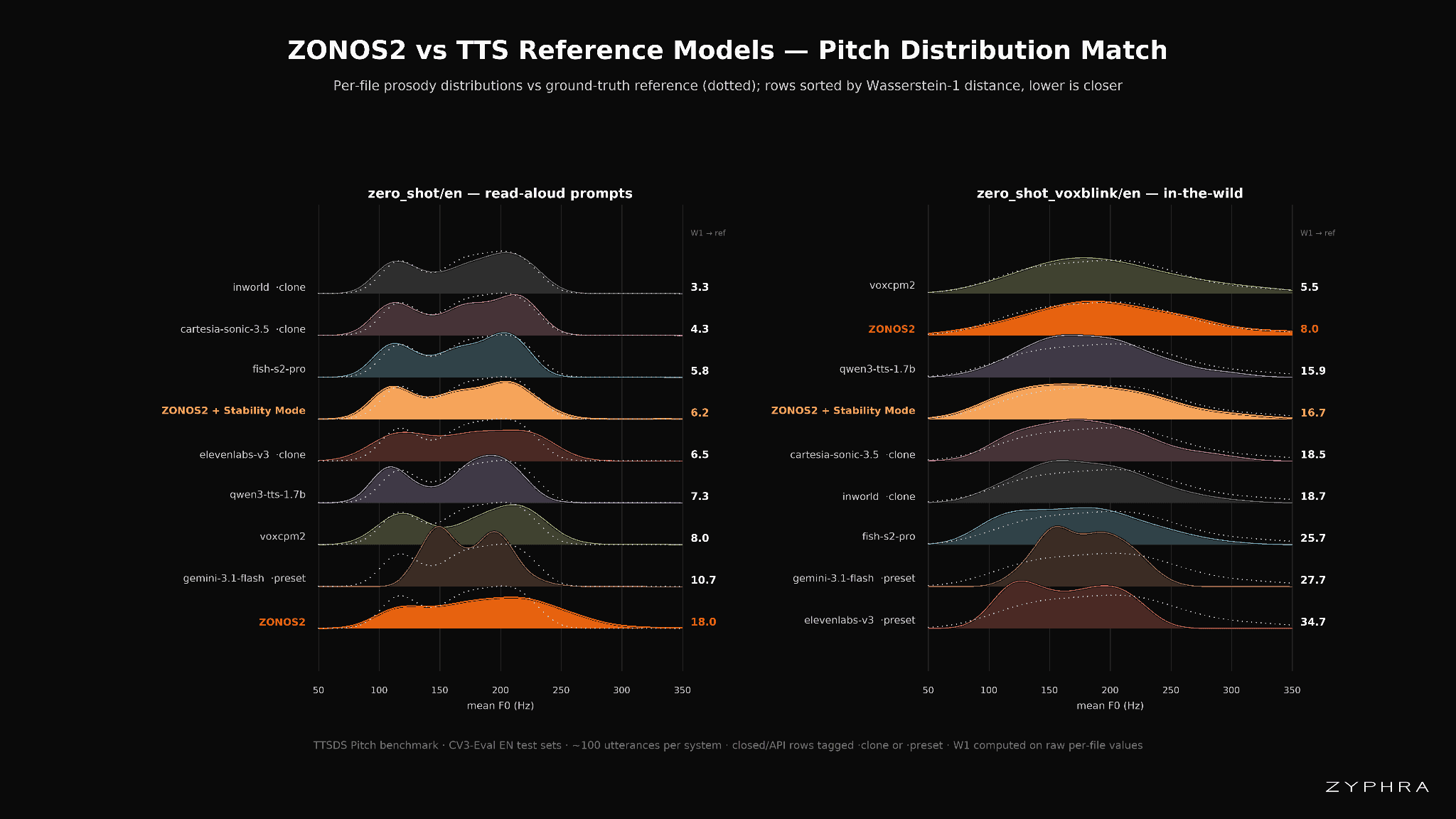
This effect can be visualized in more detail by plotting the multiple speaker metrics of the ground-truth audio vs other models. Here we can see many models often have a distinctly different ‘shape’ in the distribution of their outputs than the actual ground truth samples, implying that they subtly shift the distribution of their outputs during voice-cloning. By contrast, ZONOS2 sticks closely to the actual distribution within the ground-truth data resulting in more natural sounding audio.
However, despite our emphasis on voice-cloning fidelity, we appreciate there is also a strong case to be made for highly-stable and ‘studio quality’ speech, even if it requires departing somewhat from a truly faithful voice clone. For instance, a user may upload a poor quality voice-cloning sample with background noise, an unusual recording environment, or other audio distortions. In this case, they may want the TTS system to airbrush out these imperfections rather than faithfully replicate them in its generated audio. To serve both cases, we release ZONOS2 with two modes – a ‘stable’ mode which emphasizes clean output and an ‘expressive’ mode which focuses purely on voice-cloning naturalness and fidelity.
What's New in ZONOS2
ZONOS2 is a major step forward from Zonos-v0.1 Beta. It supports multilingual and code-switched audio generation up to one minute in length, uses simpler and more robust conditioning signals for improved stability and naturalness, and enables lifelike zero-shot voice cloning with a new ECAPA-TDNN speaker embedding model. With 20× the bandwidth of our previous speaker embedding model and new voice cloning training recipe, ZONOS2 captures significantly more vocal nuance and produces more convincing voice clones for a wide range of voices.
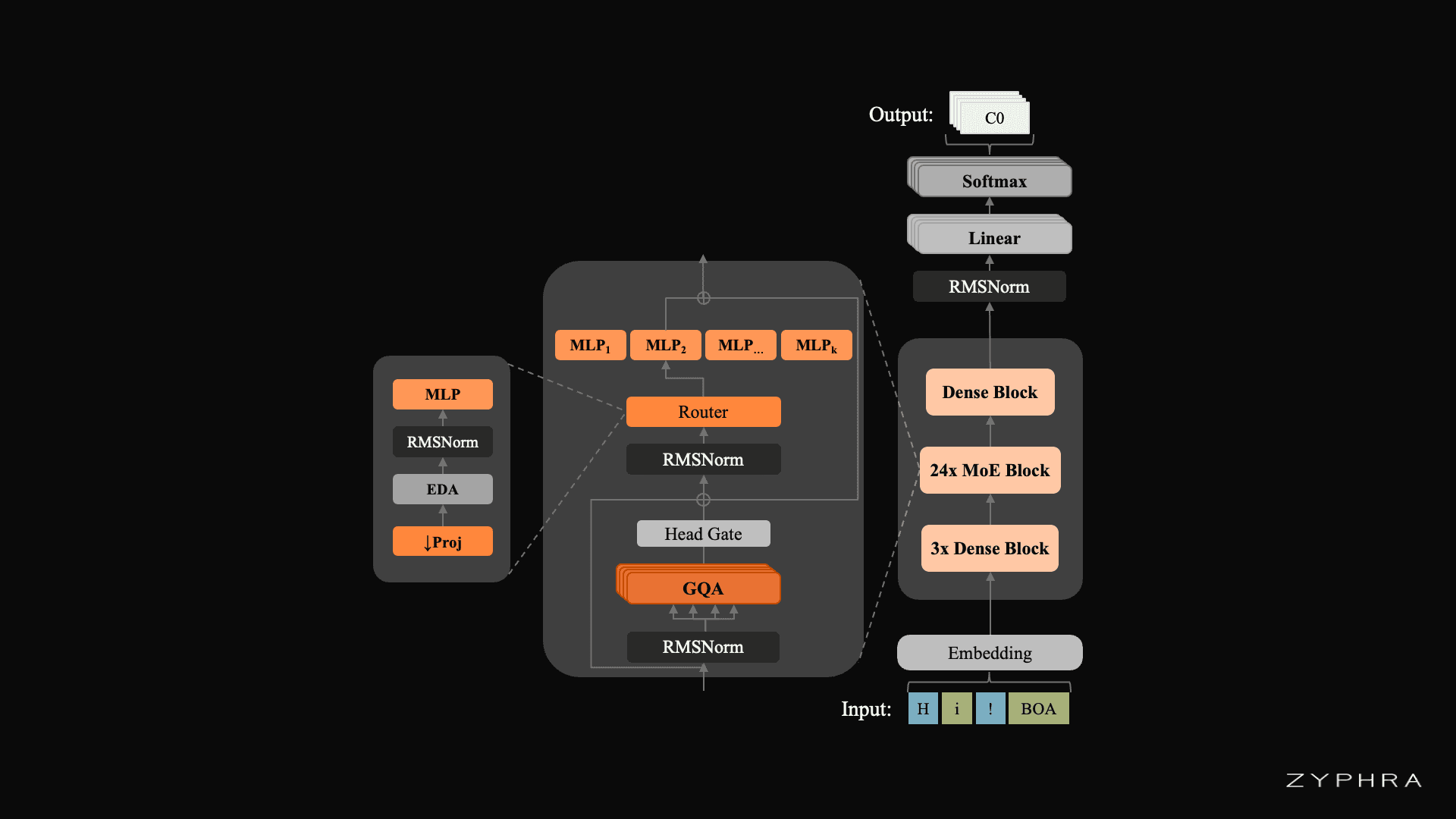
Schematic of the MoE block used in the ZONOS2 architecture. We follow our ZAYA MoE recipe including the novel MLP router we introduced for that model.
ZONOS2’s primary architectural novelty comes from adapting the powerful Mixture-of-Experts (MoE) transformer architecture to real-time TTS. Introducing MoE and removing dependence on Classifier Free Guidance (CFG) allows us to grow model size from 1.6B to 8B while improving real-time throughput by 4x compared to our previous model.
ZONOS2 predicts Descript Audio Codec (DAC) tokens, enabling it to generate studio-quality 44.1 kHz audio. DAC gives us access to exceptionally high-fidelity outputs, but modeling its tokens is significantly more challenging than working with simpler, lower-quality autoencoders. We overcome this complexity through increased model and data scale, allowing ZONOS2 to preserve audio quality while maintaining strong generation performance.
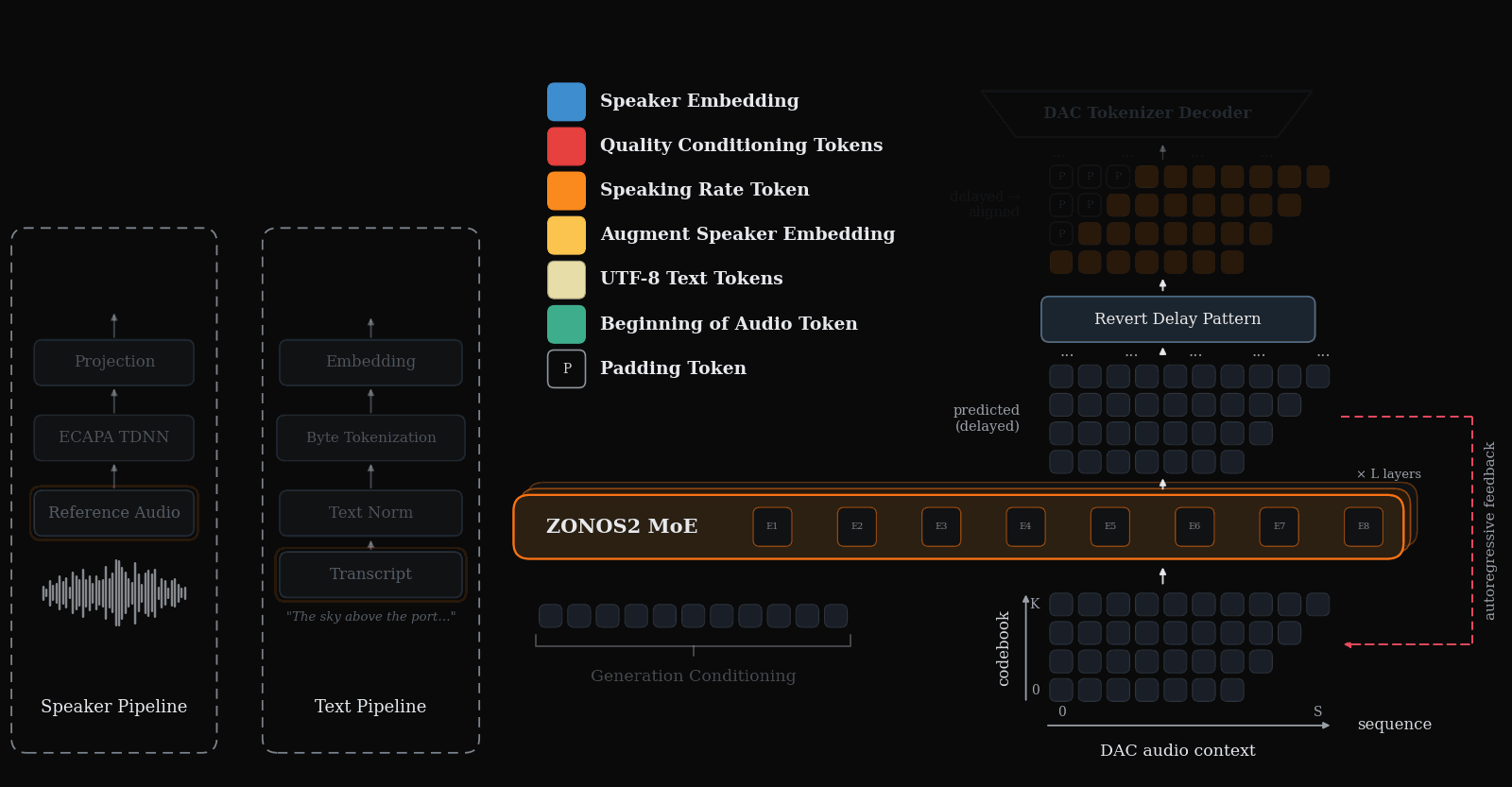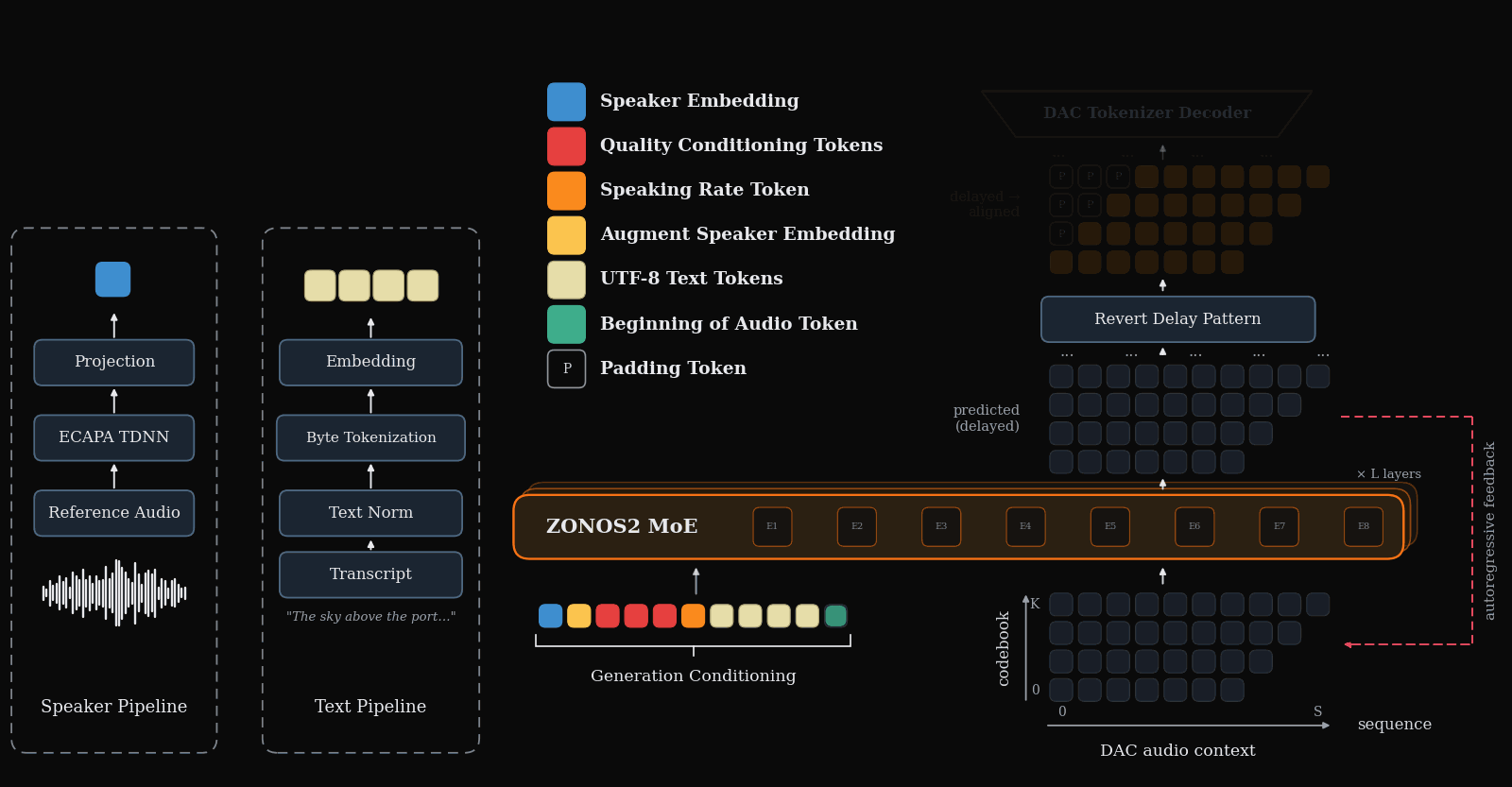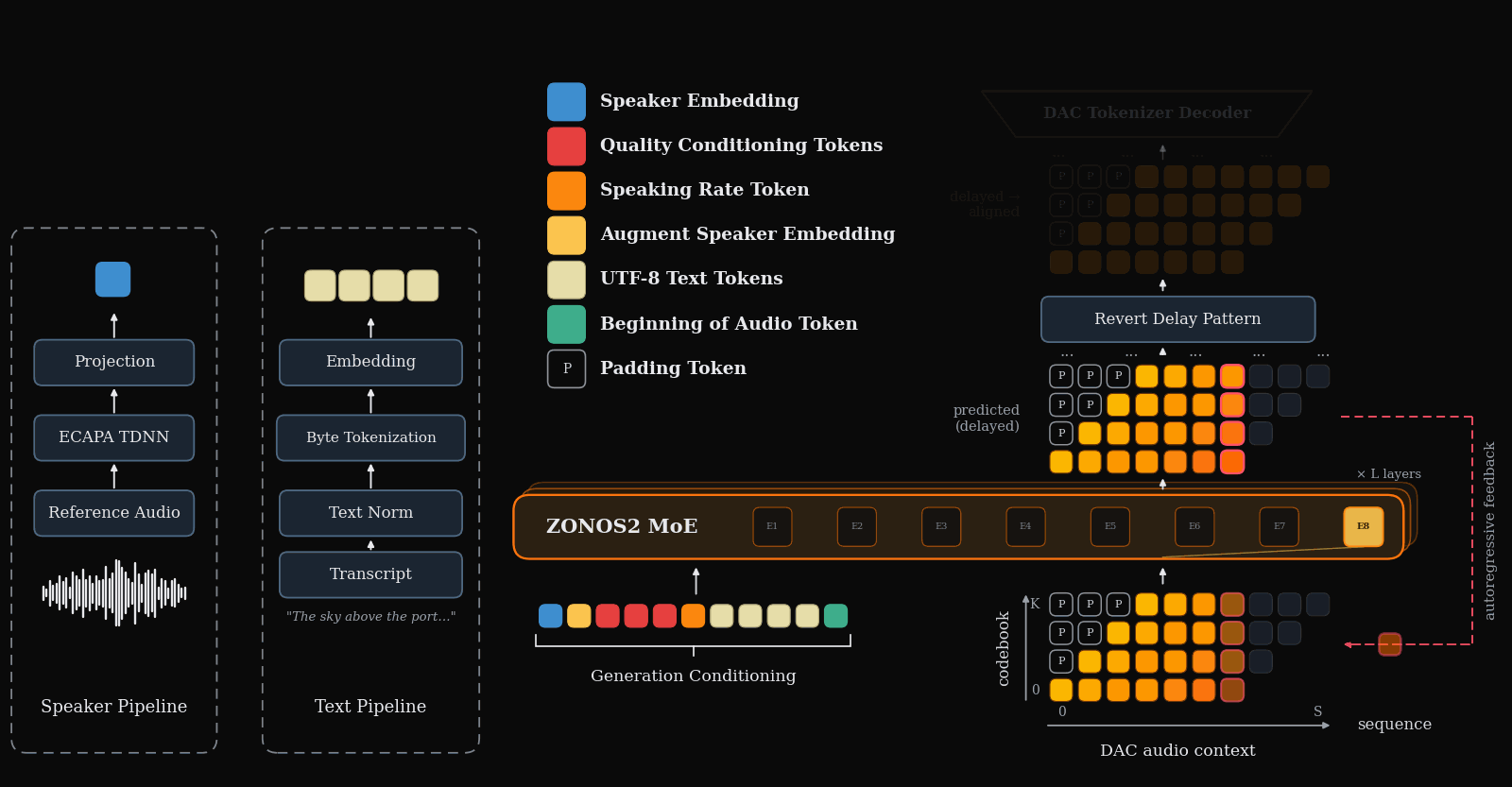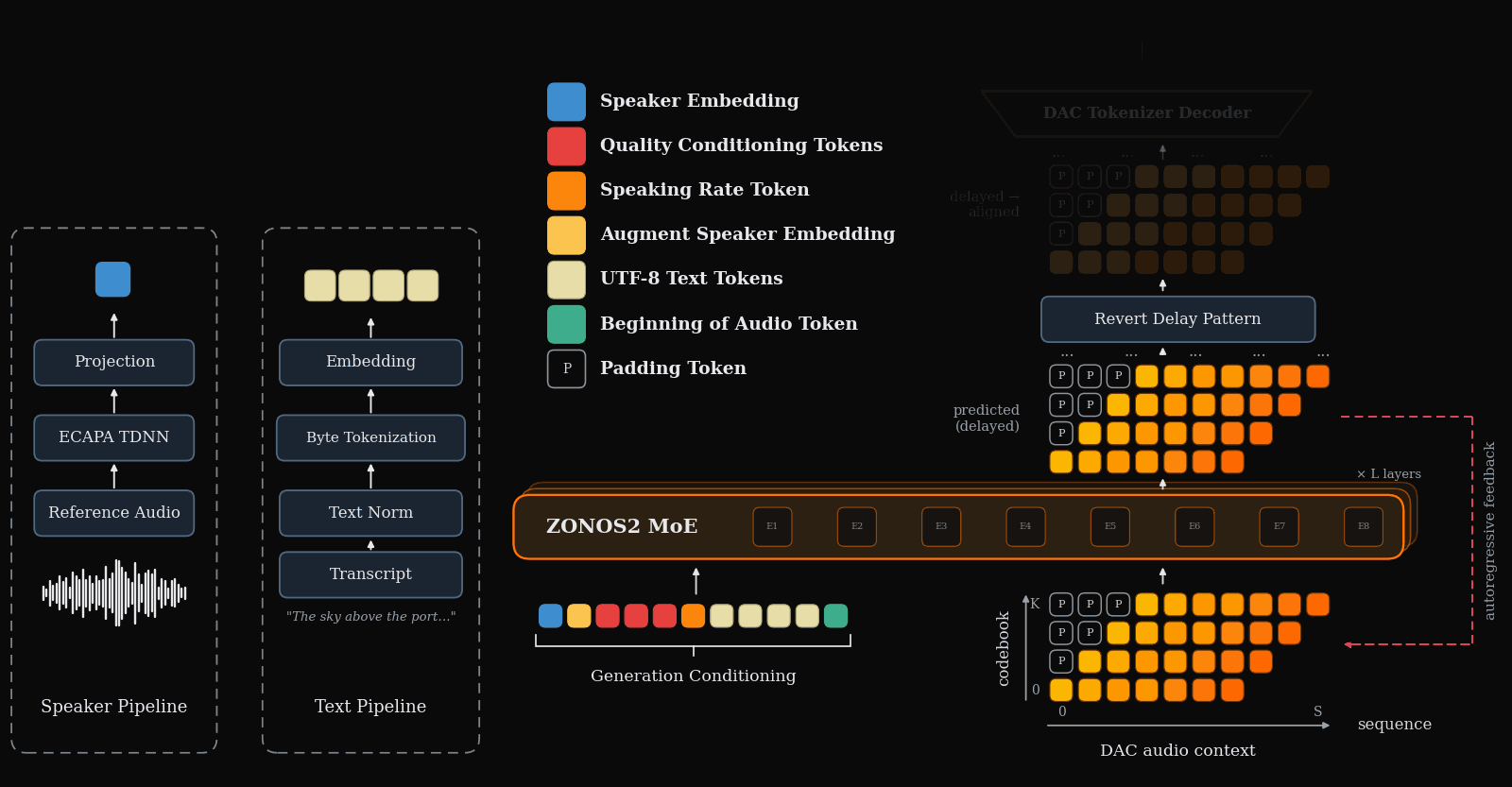
Animation of the forward pass of the ZONOS2 model. ZONOS2 autoregressively predicts DAC tokens that can then be decoded directly into 44 KHz audio. As in Zonos-v0.1, we used a delay pattern architecture to enable efficient parallel generation of DAC tokens while still properly maintaining serial dependencies across time.
Training and Architecture Details
Data Filtering
To improve on ZONOS-v0.1 Beta, we increased our training set from roughly 200,000 hours to over six million hours (or approximately 707 years) of audio. This expansion gives ZONOS2 substantially broader coverage of voices, languages, recording conditions, and text domains, while improving robustness to noise and atypical speaking patterns.
To navigate data at this scale, we introduce a new filtering method for web-scale audio data. In stage one we apply minimal inclusion criteria based on VAD and transcription validity. All audio that passes our VAD checks and receives a non-empty transcript is included in our training set. After this segmentation and labeling stage, we schedule increasingly strict inter-transcript agreement requirements over the course of training. This allows us to maximize data variety during pretraining, then progressively filter out unintelligible and low-quality audio during midtraining and annealing.
We find that scheduling transcript agreement across the three training stages lets us take advantage of the diversity of web-scale audio while avoiding many common TTS failure modes, including hallucinations, mispronunciations, repetitions, and other artifacts.
Training Recipe
ZONOS2 is trained on a simple autoregression task to predict a sequence of audio tokens given text and a speaker embedding extracted from source voice-clone audio. The output audio tokens are decoded back to raw speech waveforms for playback by the DAC decoder module. In order to model each of DAC’s ‘codebooks’ tokens, a step is conditioned on the prediction of lower order codebooks for that timestep re-ordered using a delay pattern such that the generation of each codebook for a given time step is generated sequentially.
Unlike ZONOS-v0.1 Beta, ZONOS2 represents text inputs as raw UTF-8 bytes, eliminating the need for an explicit phonemization step. This makes training more flexible, greatly expands the set of supported languages, and reduces errors caused by incorrect language labels and phonemization dictionaries. We find that byte tokenization is especially important for robust coverage of lower-resource languages, while also substantially improving performance on non-European languages such as Chinese, Korean, and Japanese, for which phonemization is substantially more challenging. Further, since it does not depend on explicit language tags, this approach natively enables code-switching in generated audio, as the model does not rely on hard coded per language tokenisation/phonemisation during inference, unlike the prior version.
ZONOS2 takes several conditioning signals that allow a user to control its generations. The model receives a speaker embedding as input which underpins its voice cloning capabilities. To enable flexible control of the generated speech, ZONOS2 also allows for the specification of target speaking-rate in eight available speeds. We support several quality dials for acoustic properties such as final estimated bandlimit for the generated audio as well as volume and estimated SNR.
ZONOS2 is trained in three phases. In the initial phase, the model is pre-trained over our entire dataset for 8 epochs without speaker cloning information and minimal transcript agreement filtering. This is followed by a shorter mid-training phase, where transcript agreement and sub-dataset selection are used to target clean high quality transcripts and audio in order to reduce hallucinations. Finally, both the speaker embedding, rate-of-speech conditioning, and quality conditioning are introduced in a short annealing training phase, using stricter filtering settings than the mid-training phase. The result of this three stage training scheme is reduced hallucinations with greater generalization to unseen voices and improved naturalness.
For more information, please see our ZONOS2 Hugging Face model card.
If you plan on self-hosting, ZONOS2 inference code is available on GitHub.
If you want to explore or use the model, it is available on Zyphra Cloud and as an API.
Introducing ZTTS1-Eval
Alongside our ZONOS2 model, we introduce a new TTS evaluation that we call ZTTS1-Eval. Throughout the evaluation process, it became clear that existing and widely-used TTS evals namely Seed-TTS-Eval and CV3-Eval have significant flaws.
Seed-TTS-Eval has three main problems. First, only Chinese and English are considered, which lacks linguistic diversity. Second, they rely on outdated models such as Whisper-Large for ASR. Thirdly, they only draw from Common Voice for English and DiDiSpeech for Chinese, both of which are read speech (with minimal prosodic variation) with a poor recording environment.
CV3-Eval partially improves upon Seed-TTS-Eval. Audio from seven additional languages are included from the FLEURS and Common Voice datasets, and tasks beyond accuracy and cloning (cross-lingual voice cloning, expressive voice continuation, emotion cloning, expressive voice cloning from web-crawled data) are added. However, the evaluation setup from seed-tts-eval is retained, using the same outdated models for ASR.
We set out to dramatically improve upon the existing state-of-the-art in TTS evaluations, and especially to produce a more robust, diverse, and less noisy evaluation than both Seed-TTS-Eval and CV3-Eval .
We release two evaluation sets. The first one consists of “Clean” audio from 9 languages using FLEURS-R, a restored version of the original FLEURS dataset, chosen for consistency and general acoustic quality. The second “In-The Wild” subsamples VoxBlink2 across 17 languages for acoustic and linguistic diversity. VoxBlink2 is composed of in-the-wild clips with highly variable quality, we choose samples across 10 uniform bins, spanning a 1-4 UTMOS quality score range to ensure fair representation across quality levels.
For evaluation we choose to swap older models for ones approaching the current state of the art. We use Qwen3-ASR for speech recognition (top of the Open ASR Leaderboard private set), ReDimNet for speaker similarity, MSR-UTMOS for acoustic quality.
To evaluate prosodic expressivity, we include the TTSDS Prosody metrics and Discretized Speech Weighted Edit Distance (DS-WED) in our eval. The TTSDS Prosody metrics measure distribution distances between generated and real speech, normalized by the real-to-noise distance. The set comprises Allosaurus SR (phoneme/s), HuBERT SR (semantic units/s), Pitch (mean F0), and MPM (masked prosody model embedding). DS-WED quantifies generation diversity by measuring the semantic unit distance between multiple generations of the same text.