
Research
Palo Alto, California
Zyphra is pleased to announce Zyda, a 1.3T trillion-token open dataset for language modeling. Zyda combines the existing suite of high-quality open datasets together and merges them through a uniform and thorough filtering and deduplication process. The goal of Zyda is to provide a simple, accessible, and highly performant dataset for language modeling experiments and training up to the 1 trillion scale. In our ablation studies, Zyda outperforms all existing open datasets including the Dolma, Fineweb, Pile, RefinedWeb, and SlimPajama.
Yury Tokpanov, Beren Millidge, Paolo Glorioso, Jonathan Pilault, James Whittington, Quentin Anthony
Zyda Highlights
Zyda consists of 1.3T tokens meticulously filtered and deduplicated for quality collated from existing high quality datasets
Zyda outperforms all major open language modeling datasets such as Dolma, Fineweb, and RefinedWeb, as well as each of its subsets individually
Zyda is unique in implementing cross-dataset deduplication ensuring that there are no duplicates between its component datasets
Zyda is released with an open and permissive license
Zyda Composition
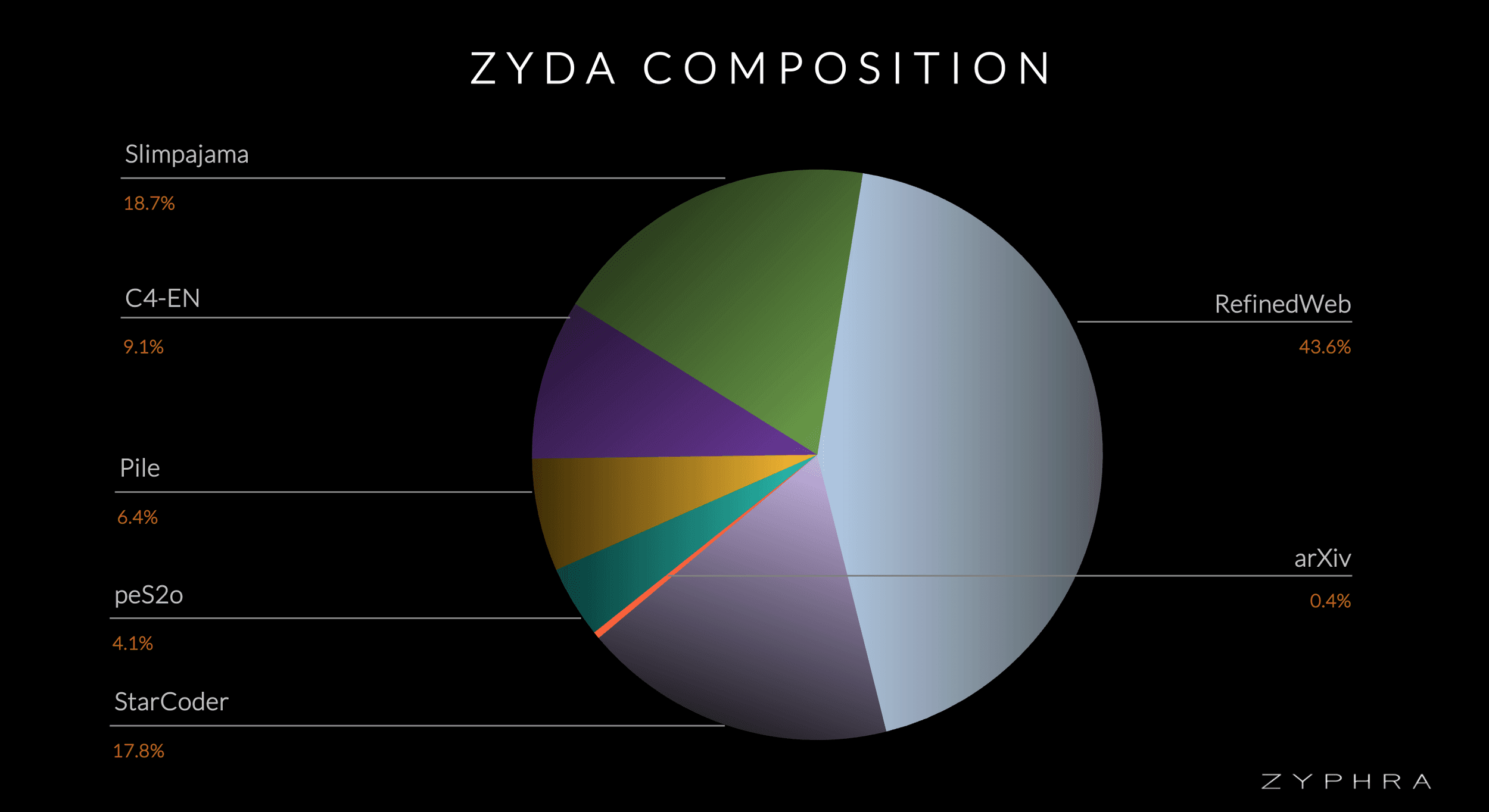
Zyda was created by merging and then applying a uniform and meticulous post-processing pipeline to seven well-respected open language modelling datasets: RefinedWeb, Starcoder, C4, Pile, Slimpajama, pe2so, and arxiv. We performed thorough syntactic filtering of the datasets to remove many clearly low-quality documents, before we performed an aggressive deduplication pass, both within and between the datasets. Cross-deduplication is very important as we found many datasets had a large number of documents that also existed in other datasets – likely because the datasets are mostly drawn from common sources such as Common Crawl. In total, we discarded approximately 40% of our initial dataset, reducing its token count from approximately 2T tokens to 1.3T.
Zyda Evaluations
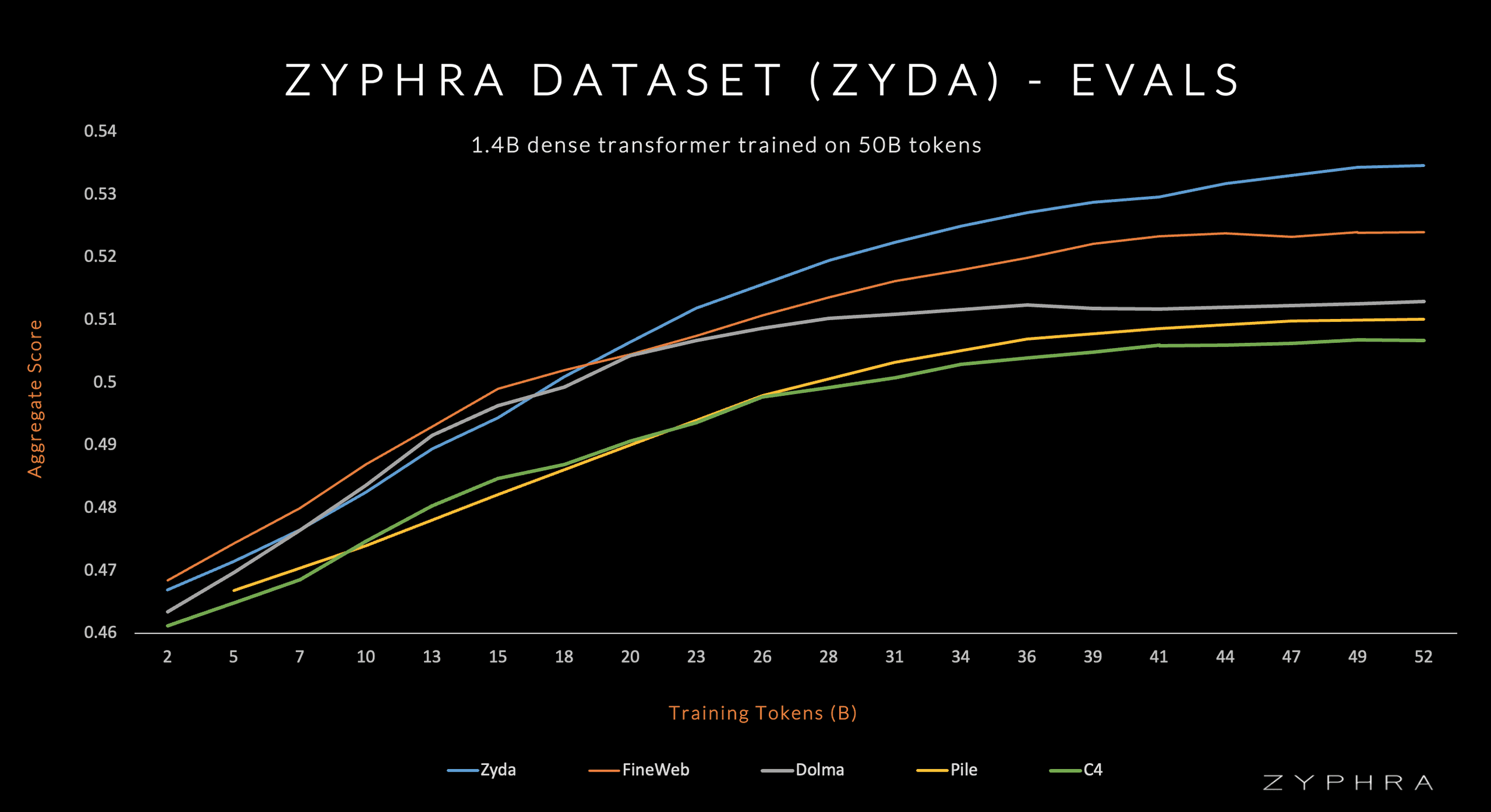
Scores of Zamba (trained on Zyda) vs competing datasets. We observe that on a per-token basis Zamba is significantly stronger than competing models, testifying to the strength of Zyda as a pretraining dataset.
Zamba & Zyda
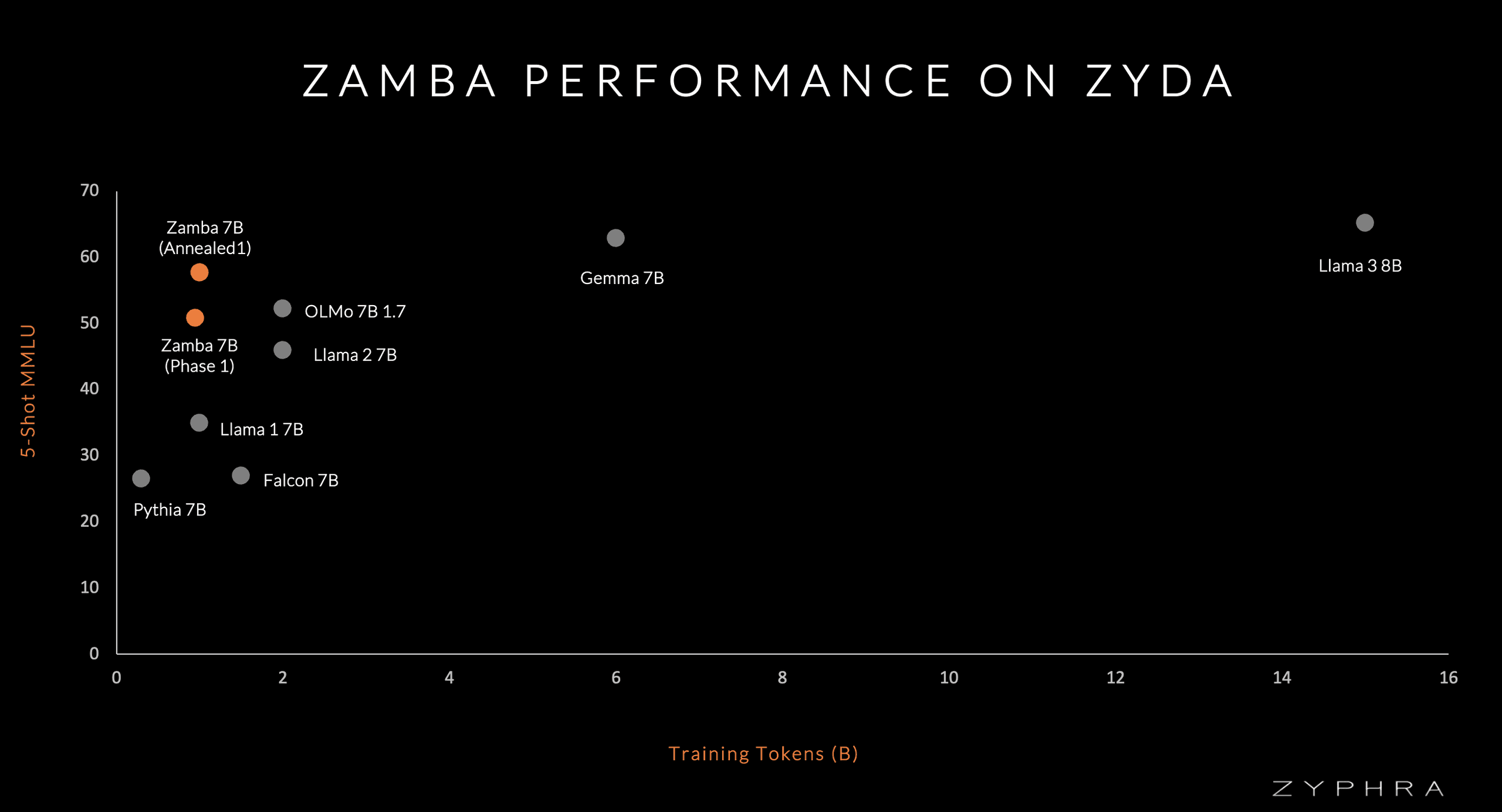
We created Zyda as part of our own internal dataset efforts and an early version of Zyda was used to train Zamba, which performs strongly on a per-training-token basis.