
Research
San Francisco, California
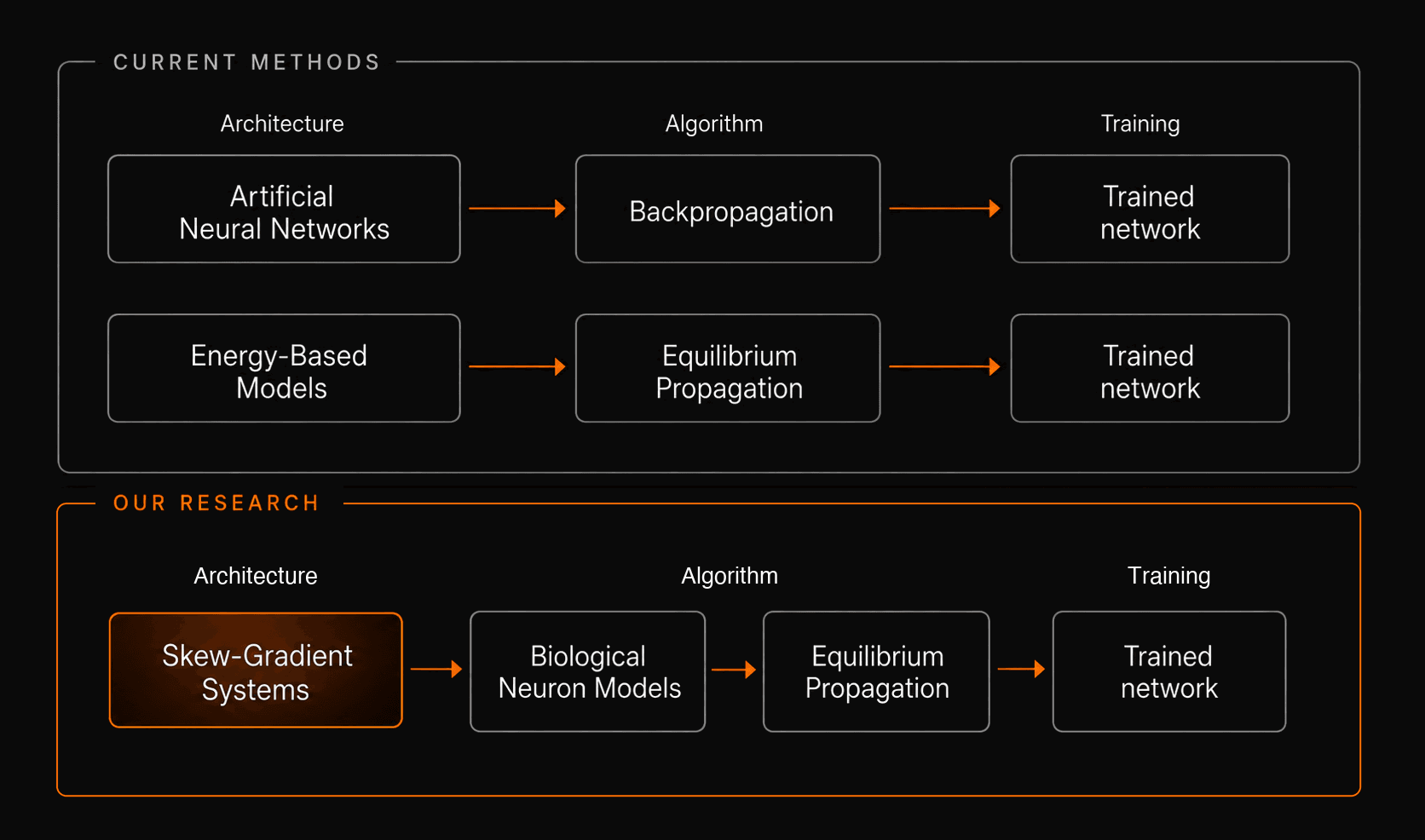
Zyphra Research demonstrates how Equilibrium Propagation (EqProp), a local learning algorithm traditionally limited to Energy-Based Models (EBMs), can be extended to a broader class of dynamical systems known as skew-gradient systems. These systems combine energy-storing and nonlinear dissipative dynamics, and include biologically realistic neuron models such as the FitzHugh-Nagumo model. Our results provide a path toward biologically plausible gradient-based learning and represent a step toward more efficient AI architectures and learning algorithms that move beyond conventional GPU-based computing.
Jack Kendall
Introduction
Today, almost all machine learning models are trained with variants of stochastic gradient descent, using backpropagation to compute gradients. SGD remains the only learning algorithm proven to scale to the largest and most complex neural networks, including large language models. Backpropagation, however, is widely considered biologically implausible. Yet biological brains outperform today’s AI systems by orders of magnitude in energy and sample efficiency.
This raises a central question for AI: can we uncover how the brain learns without backpropagation, and use those principles to build more efficient and adaptive artificial intelligence?
The fundamental reason why backpropagation is implausible in neural systems is that it requires a separate “backward” network to propagate gradient information that is accurately matched to the forward network at all times. Such a structure is not observed in biological brains. Despite this, however, the fundamental idea of stochastic gradient descent is sound.
Given how common gradient-following dynamics are in physics, e.g. energy-minimization dynamics, and the simplicity and effectiveness of stochastic gradient descent, it seems plausible that primitive neural networks could have evolved to take advantage of gradient-based learning.
Equilibrium Propagation (EqProp) provides a potential explanation for how stochastic gradient descent could be performed in biological brains. EqProp uses the mathematical fact that for Energy-Based models (EBMs) at their equilibrium states, the model’s forward and backward graphs become equivalent, allowing gradients to be computed locally using only local perturbations in the equilibrium state. However, EqProp has classically been limited to only a class of EBMs that satisfy certain stringent mathematical properties, limiting their broad applicability and making it challenging to apply to frontier AI architectures. In this work, we take a step towards extending EqProp’s domain of applicability to a much broader class of skew-gradient systems which include a widely-used model of biophysical neurons known as the Fitzhugh-Nagumo model. This moves us closer toward a biologically plausible account of gradient-based learning.
The Backward Graph
The problem of a neural network requiring a “matched” backward network in order to propagate gradients is known as an adjoint problem. The adjoint essentially answers the question of “for some desired change in the output of the network (e.g. correcting an error), what is the change in the weights or synapses required to accomplish this?”
In a typical feedforward network used in machine learning, the backward graph of the original feedforward network (the one being trained) is a reversed version of the original network, with the now backwards-facing weights equal to the transposed weights of the original, and the neuron activations replaced by the derivatives of the activations. The core machinery behind autodifferentiation libraries such as PyTorch is that they construct this “backward graph” automatically from a given “forward” computational graph. However, it is exactly this requirement of precisely computing or matching this backward graph to its associated forward graph at all times during training which makes this procedure not biologically plausible.
In physics and mathematics, however, it is common to deal with so-called “self-adjoint” systems. These are systems which, somewhat remarkably, are their own backward graphs. The simplest of these systems are the Energy-Based Models. They have the property that at their energy minima, where inference takes place, their forward graph is equal to their backward graph.
Energy-Based Models are not the only systems which possess this property. In fact, quantum systems are also self-adjoint! They are part of a large class of self-adjoint systems which, classically, are known as Hamiltonian systems. These are energy-conserving systems: that is, they do not dissipate energy over time.
The fact that perhaps the three most important classes of systems in physics: energy-minimizing (dissipative) systems, energy-conserving (Hamiltonian) systems, and quantum mechanical systems are all self-adjoint is an indication that this type of structure is important.
Equilibrium Propagation
Equilibrium Propagation is based on the observation that a backward graph is not required for self-adjoint systems. It is possible to use the original network to perform gradient propagation, since it is its own adjoint. Thus self-adjoint systems, such as Energy-Based Models, are the exact class of systems which resolve the core tension between neuroscience and backpropagation.
Unfortunately, while EqProp and related algorithms work in a wide variety of physical systems, they are not completely general. That is, they do not work for all physical systems: systems which are not self-adjoint. Most importantly, biological neurons, as well as existing neural network models, are not self-adjoint!
Biological Neuron Models
While this seems like a critical flaw, it can be shown that certain biological neuron models, such as the Fitzhugh-Nagumo model, which we analyze in detail in our paper, are essentially self-adjoint, in a mathematically precise sense. They possess what is known as “skew-gradient”, or activator-inhibitor structure: although they are not globally self-adjoint, they are built from self-adjoint pieces. The key result of our paper is that this skew-gradient structure is still compatible with Equilibrium Propagation.
This allows us to generalize Equilibrium Propagation beyond self-adjoint systems, to systems which have complex, nonlinear dissipation, active or gain-providing elements, as well as energy-storing elements. These are all properties which characterize real neurons and systems with these components describe a wide array of non-self-adjoint systems with complex behavior, such as generation of action potentials, spiral waves, Turing patterns, critical phase transitions, and other phenomena associated with classical complex systems.
Why This Matters for HW
Modern AI training depends on highly synchronized digital hardware optimized for backpropagation and dense matrix multiplication. Biological neural systems operate very differently: computation, memory, and learning are co-localized and emerge through local physical interactions.
Learning algorithms such as Equilibrium Propagation raise the possibility of AI systems that learn directly through physical dynamics rather than explicit backward passes. This could ultimately enable new forms of low-power analog, neuromorphic, or hybrid computational hardware beyond today’s GPU-centric architectures.
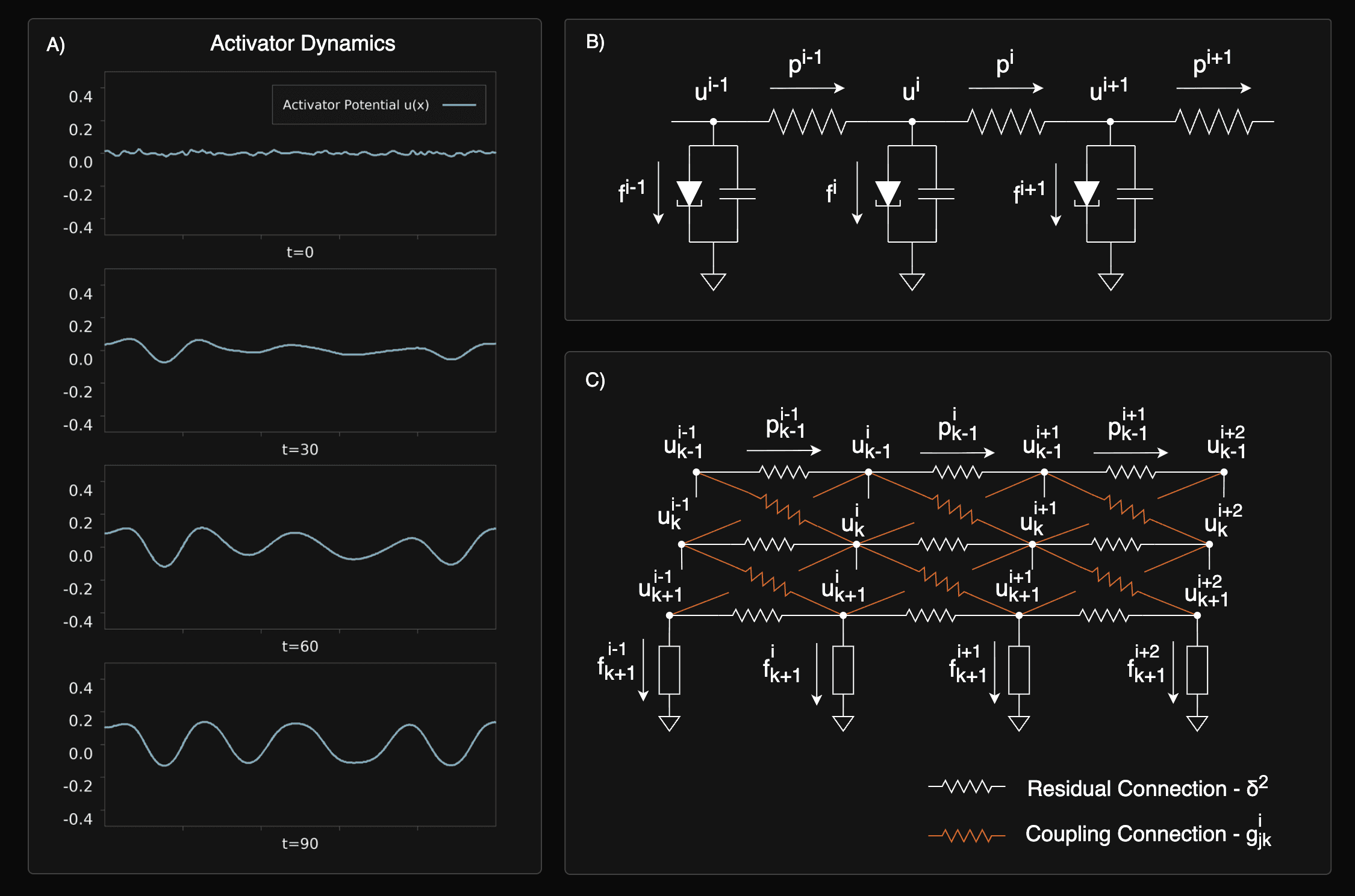
Figure 1: Description of the Fitzhugh-Nagumo model described in this work. A) Time dynamics (time increasing downwards) of a set of Fitzhugh-Nagumo neurons coupled along a 1-dimensional chain, showing convergence of the network to a “Turing Pattern” solution. B) Circuit-equivalent description of the network in A, showing nonlinear tunnel diode, membrane capacitance, and resistive coupling. Recovery variable (inhibitor) not shown. C) A deep neural network model of Fitzhugh-Nagumo neurons arranged in a multi-layer perceptron architecture, which was used for training.
Training FitzHugh-Nagumo Networks with EqProp
To validate this framework, we construct a deep network of FitzHugh-Nagumo neurons and successfully train it on MNIST using Equilibrium Propagation, achieving performance comparable to a standard Energy-Based Model.
While modest in scale, this result demonstrates that biologically realistic neuron models can be trained with local learning rules derived from physical dynamics rather than explicit backpropagation.
More broadly, this suggests a path toward neural architectures and hardware substrates that learn through local physical interactions, potentially enabling forms of AI fundamentally different from today’s GPU-centric deep learning systems.