
Research
San Francisco, California
Hybrid Associative Memory (HAM) leverages complementary strengths of RNNs and attention. In HAM, the KV cache maintains long-range details by storing only those tokens that are unpredictable by the RNN. HAM shows strong performance relative to the Transformer at a fraction of the cache size.
Leon Lufkin, Tomás Figliolia, Beren Millidge, Kamesh Krishnamurthy
Introduction
Sequence-mixing layers are the critical element in modern language models. They are the only component in the model that lets each token relate to the rest of the sequence. The two dominant paradigms for sequence-mixing layers in modern LLMs are self-attention and modern recurrent neural networks (RNNs) such as Mamba2/3 and GatedDeltaNet (GDN). These two layer types integrate the information contained in a sequence in their internal state using orthogonal philosophies: self-attention stores details about every time-point in the sequence faithfully (the KV cache), like a scribe who notes every word in a conversation, and this results in a KV cache that grows with the sequence length. The RNN on the other hand, compresses the entire sequence into a fixed-size state, and thus, summarizes the contents of the sequence.
The Transformer architecture, which uses self-attention, shows strong performance, but this performance comes at the expense of a large memory and computational cost. During training, the computational cost of attention grows quadratically, and during inference the KV cache size grows linearly with sequence length, rapidly becoming memory-bandwidth bound.
This cost becomes ever more salient in long-context tasks which require deep and complex reasoning. The computational and memory bottleneck of the KV cache is one of the most critical issues in training and deploying modern LLMs.
On the other hand, RNNs are efficient with respect to both memory and computation—the memory required doesn’t depend on the sequence length and the computational cost is linear instead of quadratic. However, because they must compress the full context into a fixed-size state, performance inevitably degrades, especially on long-context tasks which require recalling precise details. The two methods have complementary strengths: one prioritizes precise recall, while the other prioritizes efficient summarization, which can be beneficial for generalization.
The large computational and memory cost of the KV cache has led to a significant body of work on hybrid architectures which combine these methods. The predominant class of hybrids interleaves layers of self-attention with RNNs, with a focus on reducing the computational burden of the self-attention layers, which Zyphra helped pioneer with its Zamba and Zamba2 suite of models.
Another class of hybrids combines an RNN and Transformer in the same layer. However, both these approaches do not exploit the complementary strengths of these two sequence-mixing methods, rather they naively do both in parallel.
In this work, we propose a novel framework, which we call Hybrid Associative Memories (HAM), which explicitly uses the RNN state and the KV cache in a complementary way. Specifically, we combine RNNs and self-attention so that the RNN summarizes the contents of a sequence, while the KV cache only stores the parts of the sequence that the RNN cannot predict. Effectively, we can think of the KV cache as a notebook or cheat-sheet in which the model selects and stores specific, precise details whereas the RNN can capture the general meaning of the sequence.
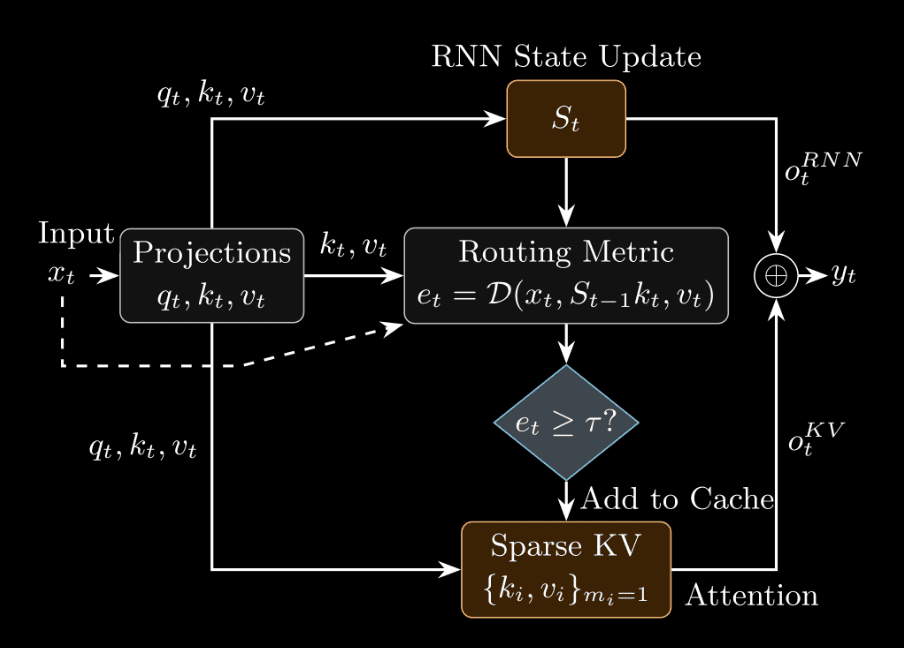
Figure 1 from the paper. HAM keeps both a recurrent state and a sparse KV scratchpad that keeps tokens the RNN finds hard to predict.
The Hybrid Associative Memory (HAM)
To motivate the design of HAM, it helps to view sequence-mixing layers through the lens of associative memories. The sequence-mixing layer processes every new input by comparing the query \(q_{t}\), to the keys \(k_{i}\) and values \(v_{i}\), in its internal state to retrieve an output \(o_{t}\). In the case of self-attention, this process is the familiar softmax retrieval:
\[o^{KV}_t = \frac{\sum_{i\le t} \exp(q_t^\top k_i)\, v_i}{\sum_{i\le t} \exp(q_t^\top k_i)}\]
This expression makes the growing cost of self-attention explicit: to compute the current output, the model must retain keys and values for all past positions.
Many modern RNNs compress the keys and values from the past into a single fixed-size state \(S_{t}\), and in the case of the DeltaNet, this state is updated as:
\[S_t = S_{t-1}\bigl(I-\beta_t k_t k_t^\top\bigr) + \beta_t v_t k_t^\top\]
and the output is given by
\[o^{RNN}_t = S_t q_t\]
This update rule is derived from an optimization problem where the state update is optimized to reduce an online prediction error.
This optimization objective naturally suggests a metric for tokens that are “hard” or “surprising” for the RNN: whenever the prediction error is above a threshold \(\tau\), then the token is considered hard to predict and is routed to the KV cache. By varying the threshold \(\tau\), we can vary the fraction of tokens being routed to the KV cache in a controlled, continuous manner. Moreover, given more recent RNNs with state updates that are derived from other objectives, we also experiment with a fully end-to-end learnable router for sending tokens to the KV cache. Based on Zyphra’s prior research for ZAYA1, we also test a router with exponential depth averaging (EDA). The overall framework for the HAM layer is illustrated in Fig. 1.
A toy example to illustrate the routing metric:
We illustrate the routing of the surprising tokens to the KV cache using an example from the “Needle in a Haystack” (NIAH) task where a needle is hidden in between a longer sequence. As we can see the routing metric correctly spikes at the needle and these tokens are routed to the KV cache. Natural language is messier and more complex and we study the behavior of the routing for these sequences in the technical paper.
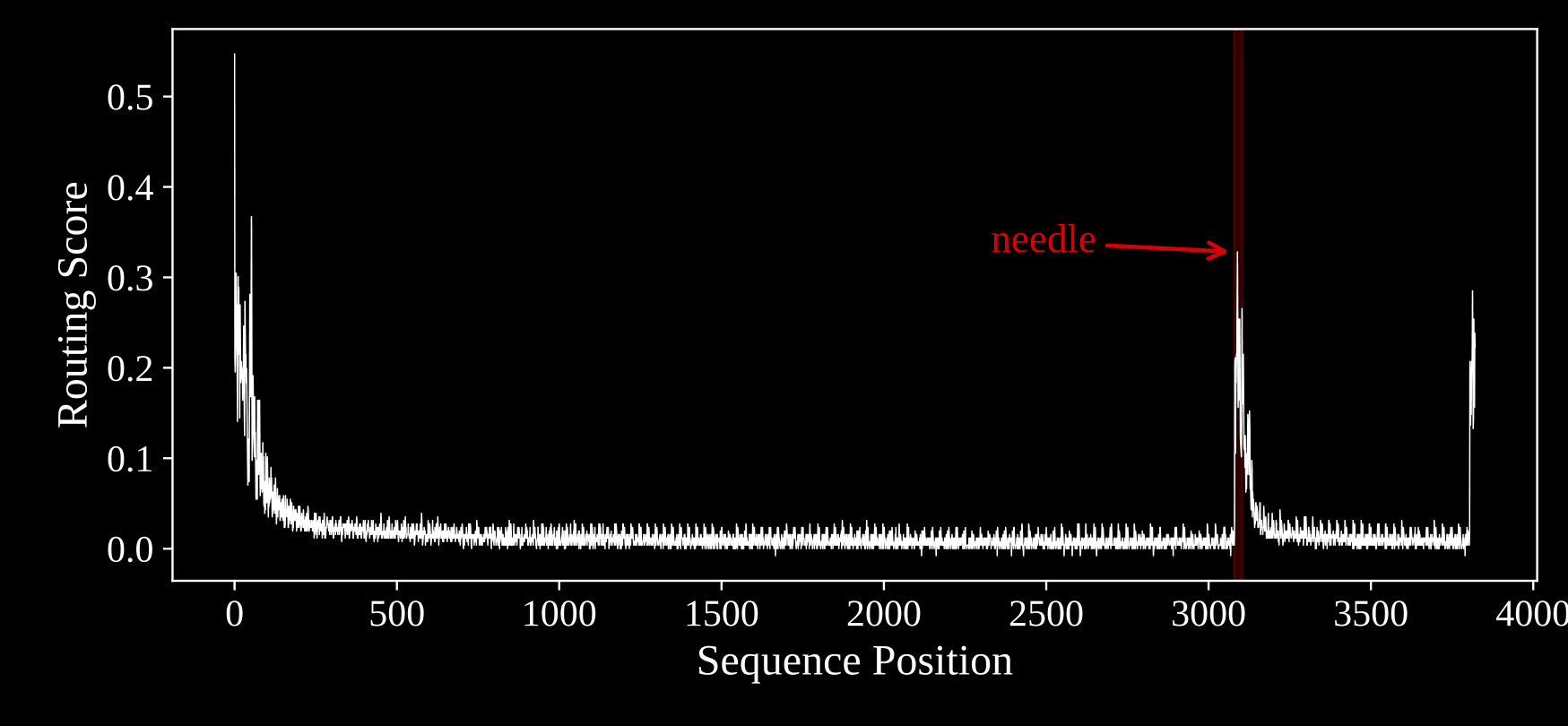
Figure 4 from the paper. On a synthetic needle-in-a-haystack example, the routing score spikes exactly where the sequence becomes surprising.
Experimental Results at the 800M Scale
We compare HAM against parameter-matched baselines at the 800M scale: a standard Transformer, a pure Gated DeltaNet (GDN), and a stacked hybrid that interleaves GDN with global self-attention layers (GDN-GSA). All HAM variants use only 50% of the KV cache relative to the Transformer and are memory- and compute-matched to the GDN-GSA (but not the GDN or Transformer). Models are trained on 50B tokens from the Long Data Collections dataset with a context length of 16,384. We note that the Transformer baseline in our test has a larger dimension for the KV cache compared to GDN-GSA and HAM.
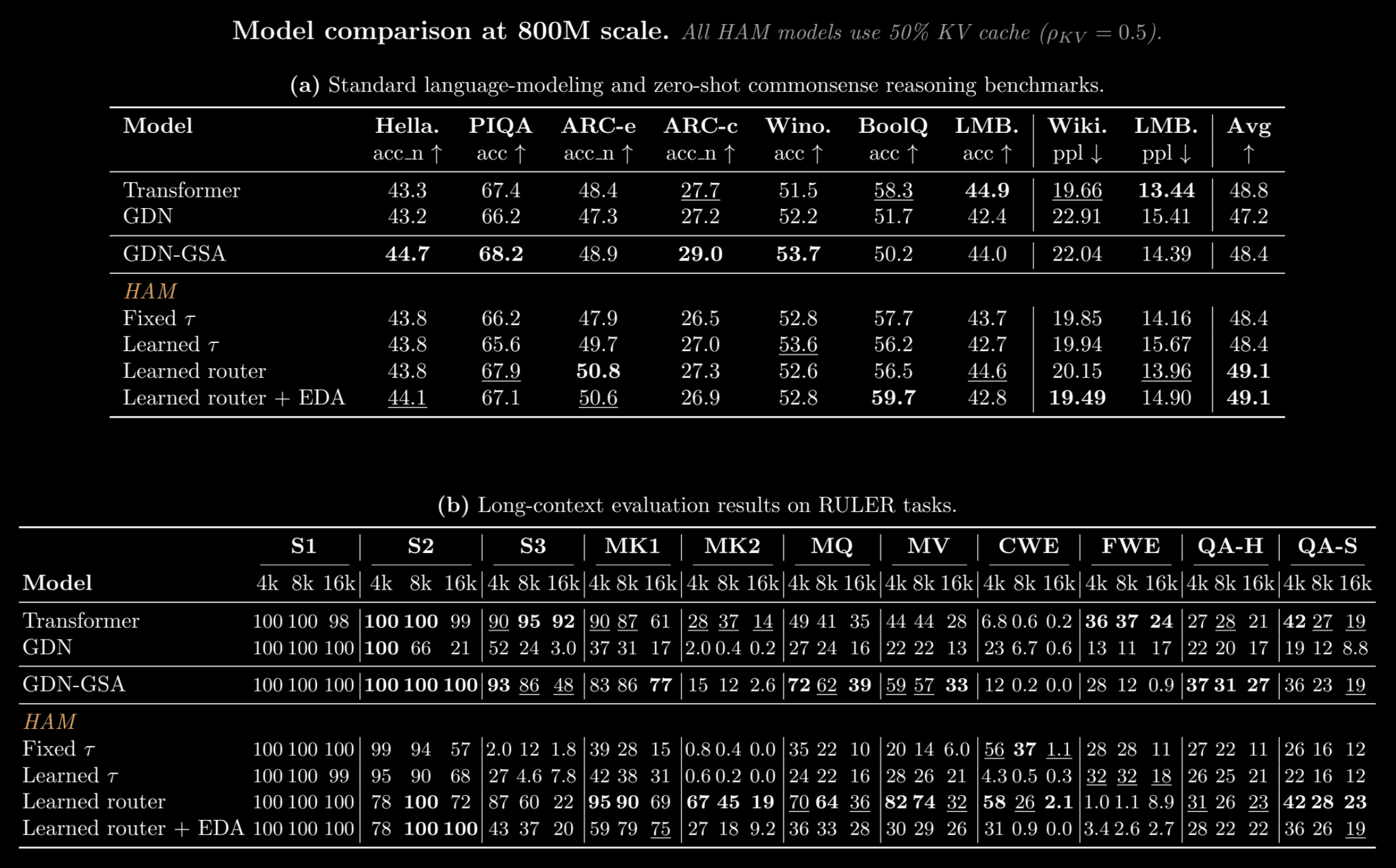
Table 1 from the paper. All HAM variants in this comparison use only 50% KV cache. Only the GDN-GSA is compute- and memory-matched to HAM.
On the standard language-modeling and commonsense suite, the learned-router HAM variants achieve the best overall average score reported in the table: 49.1, versus 48.8 for the Transformer baseline and 48.4 for the GDN-GSA hybrid. The learned router posts the strongest ARC-e score in the table at 50.8, while the EDA variant reaches the best BoolQ score at 59.7 and the best WikiText perplexity at 19.49. This shows that HAM is competitive on ordinary next-token modeling and zero-shot reasoning tasks.
The long-context results are more nuanced: HAM is not uniformly best at all RULER tasks; however, at a matched 50% cache budget, HAM is especially strong on the retrieval settings where interference might matter most: the multikey (MK), multiquery (MQ) and multivalue (MV) tasks. The learned-router model reaches 67/45/19 on MK2 at 4k/8k/16k, substantially above the Transformer’s 28/37/14 and far above the GDN-GSA hybrid’s 15/12/2.6. The EDA variant also recovers very strong single-2 performance. In the paper, we also show how these results vary as we tune the fraction of tokens routed to the KV cache.
Flexible Performance and Memory Trade-offs
A distinctive feature of HAM is that it provides a continuous, fine-grained knob for controlling the KV cache budget—both per-layer and globally—while gracefully trading off memory usage against performance. Each layer has a threshold \(\tau_l\), that can be learned during training to achieve a desired KV cache usage; moreover, the global KV cache usage can be set to a desired target \(\rho_{kv}\) by sharing the thresholds across the layers:
\[\rho_{kv} = \frac{1}{LT}\sum_{\ell=1}^L T^{(\ell)}_{kv}\]
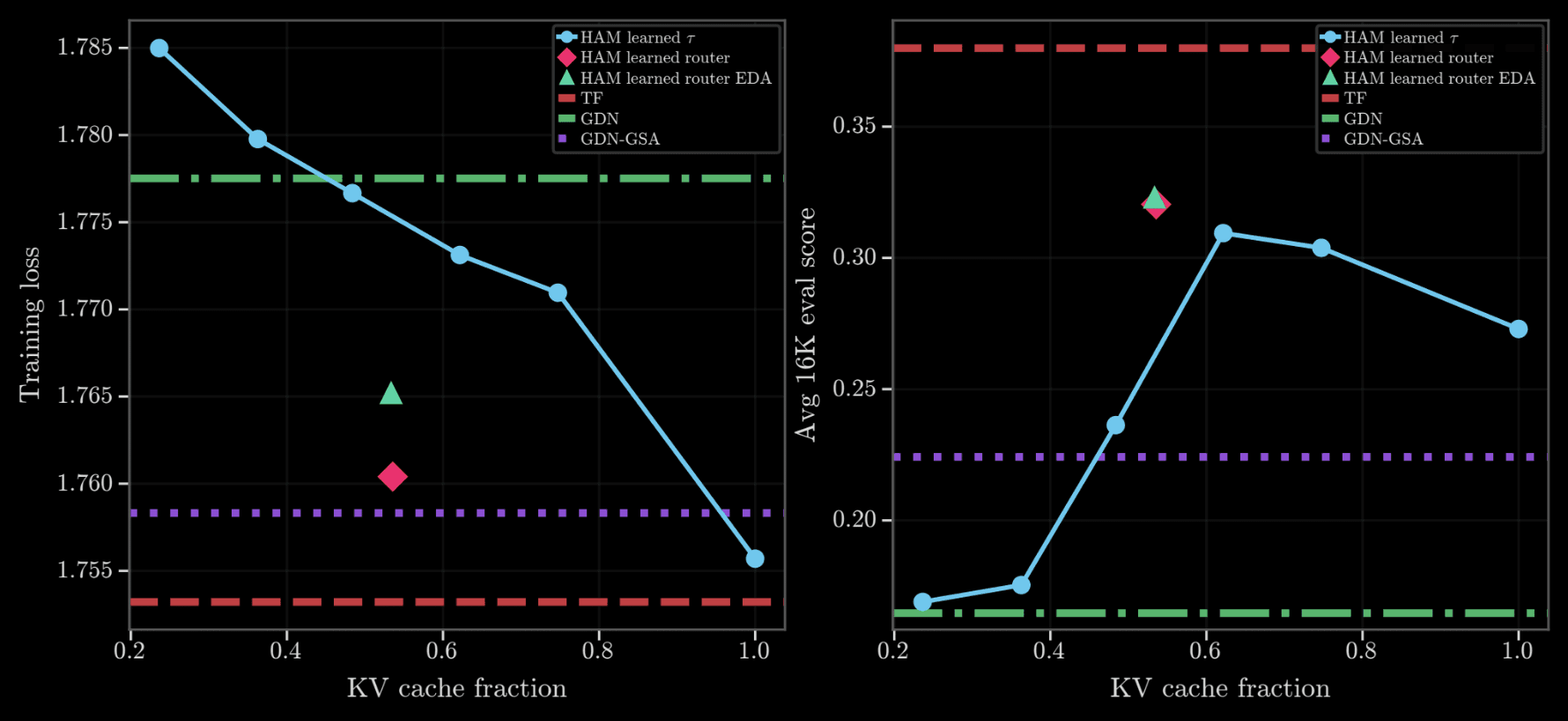
Figure 3 from the paper. As the KV fraction grows, language-modeling loss falls smoothly rather than collapsing abruptly; eval scores behave similarly, up to a point but degrade slightly where recall from larger KV cache sizes may be harder.
In Figure 3, we see that as the KV fraction increases, loss decreases in a smooth, predictable way, instead of a sharp cliff; long-context eval scores show similar trends up to a point, but we observe a slight decrease for larger KV cache sizes, where interference may be greater.
Figure 7 shows that the global KV cache target is reached rapidly, and that different layers have very different KV cache usage under the global target. HAM offers the possibility of probing or setting the KV cache capacity of different layers in a continuous and precise manner.
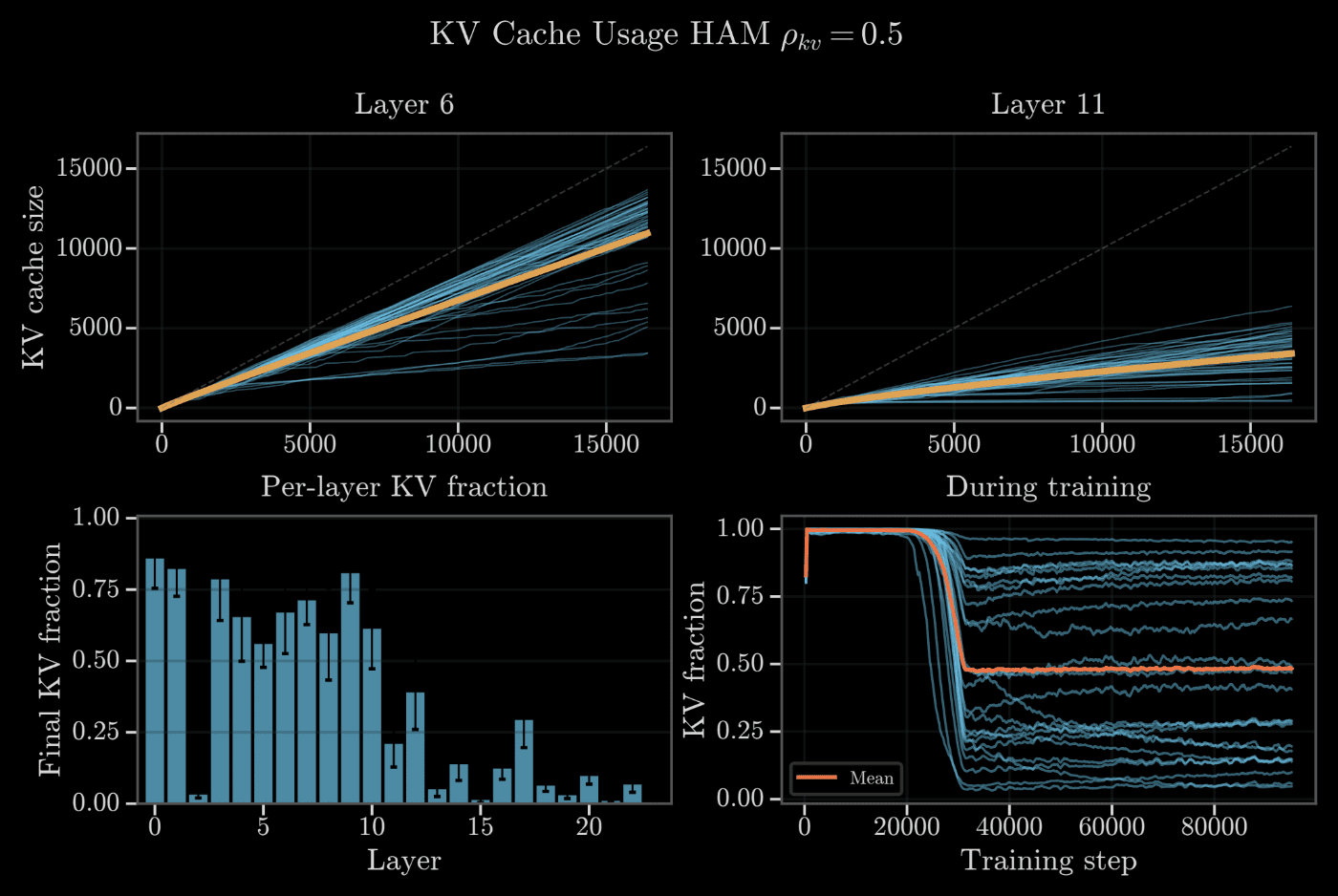
Figure 7 from the paper. Different layers converge to very different KV fractions even under a single global target, suggesting that layers have different explicit-memory needs. The global KV cache target is reached rapidly after a brief period of freezing the thresholds (orange line).
How This Differs from Prior Work on Controlling the KV cache:
This level of fine-grained, continuous control over KV cache size has been difficult to achieve in prior architectures. Stacked hybrids can only reduce KV usage by removing attention layers—a discrete, coarse-grained choice made before training. Hybrid-head models can use sliding-window attention, but these are static decisions. Post-hoc KV cache compression methods (SnapKV, PyramidKV, Ada-KV, etc.) provide budget control at inference time, but the model was trained with a full cache and has no complementary memory to absorb evicted tokens. In HAM, the RNN explicitly captures compressible context, ensuring that eviction and compression are coordinated and learned end-to-end from the start of training.
Conclusions and Future Directions
HAM introduces a principled way to combine recurrence and attention by exploiting their complementary strengths. Rather than treating the KV cache and RNN as independent sequence-mixers, HAM enables them to work in a complementary fashion: the RNN summarizes the predictable part of the sequence, and the KV cache stores the parts that are surprising.
This approach has many appealing properties:
Competitive performance. At 800M parameters with only 50% KV cache, HAM matches or exceeds full-cache Transformers and layerwise hybrids on standard benchmarks and many long-context tasks.
Fine-grained control of the KV cache budget. The KV cache budget is a continuous, user-specified parameter with a smooth and predictable trade-off with performance—enabling practitioners to select the right operating point for their latency and memory constraints.
Leveraging complementary memory systems theory: HAM’s design aligns with Complementary Learning Systems theory in neuroscience, where distinct subsystems (hippocampus and cortex) handle fast episodic recall and slower abstract integration of experience.
Looking ahead, several directions are promising. The relatively smooth trade-off between KV cache usage and performance suggests that the threshold could be varied during test time, adapting the KV cache budget within a sequence or across tasks. The KV cache growth rate could also be scheduled to achieve sublinear growth for highly structured sequences. Finally, scaling HAM to larger model sizes and longer contexts will be important to understand whether these advantages will be more pronounced on truly long-context scenarios.