
Model
Palo Alto, California
We introduce ZR1-1.5B, a small reasoning model trained extensively on both coding and mathematics problems with reinforcement learning. ZR1-1.5B outperforms many significantly larger general non-reasoning models on code generation, while maintaining performance close to state-of-the-art small reasoning models trained exclusively on math on competition-level evaluations.
On LCB_Generation ZR1-1.5B achieves parity with Claude3-Opus and Gemma2-27B, while on competition math ZR1-1.5B outperforms Qwen2.5-72B. Unlike comparable reasoning models, ZR1-1.5B requires significantly shorter reasoning traces, using 60% fewer tokens than R1-Distill-1.5B and 53.5% fewer tokens than DeepScaleR.
Overall ZR1-1.5B demonstrates strong generalization across disparate domains as well as coherent and efficient reasoning traces compared to models of a similar scale.
Zyphra Team
Introduction
We introduce ZR1-1.5B, a small reasoning model trained extensively on both verified coding and mathematics problems with reinforcement learning (RL). ZR1-1.5B outperforms many significantly larger general non-reasoning models on code generation, while maintaining performance close to state-of-the-art small reasoning models trained exclusively on math on competition-level evaluations.
ZR1-1.5B uses significantly shorter reasoning traces than comparable models, using 60% fewer tokens than R1-Distill-1.5B and 53.5% fewer tokens than DeepScaleR across the LiveBench subset, with strong generalization capabilities across math and code and less computational overhead.
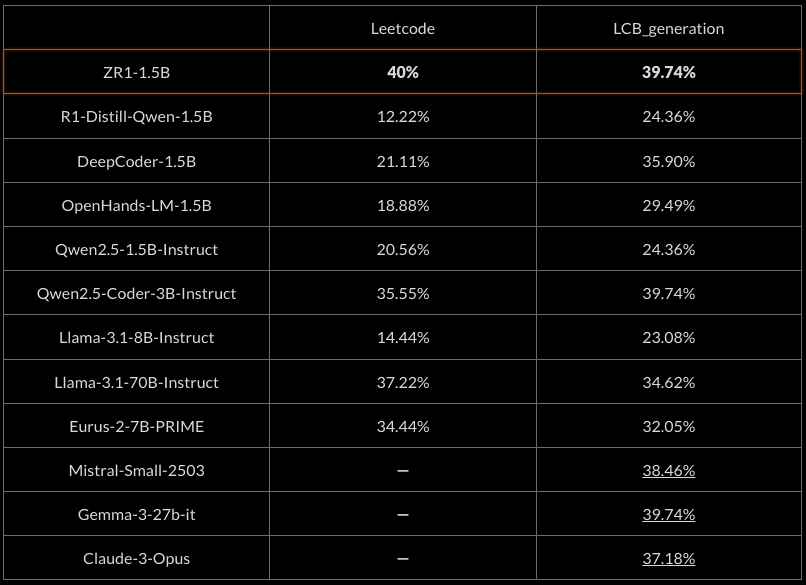
Reported scores underlined. Pass@1 scores with greedy sampling.
As we observe, ZR1-1.5B performs comparably to larger and stronger models on hard coding tasks, achieving rough parity with Gemma-3-27b-it and Claude-3-Opus and improving upon the base R1-Distill-1.5B model by over 50%.
At the same time, ZR1-1.5B maintains strong performance on competition math, performing comparably to the state-of-the-art model of its size (DeepScaleR), which is trained exclusively on competition math, and outperforms other reasoning models of its size including the R1-distill models.
ZR1-1.5B also performs strongly against larger math-optimized non-reasoning models such as the Qwen2.5-Math family of models, while needing fewer reasoning tokens than comparable reasoning models.
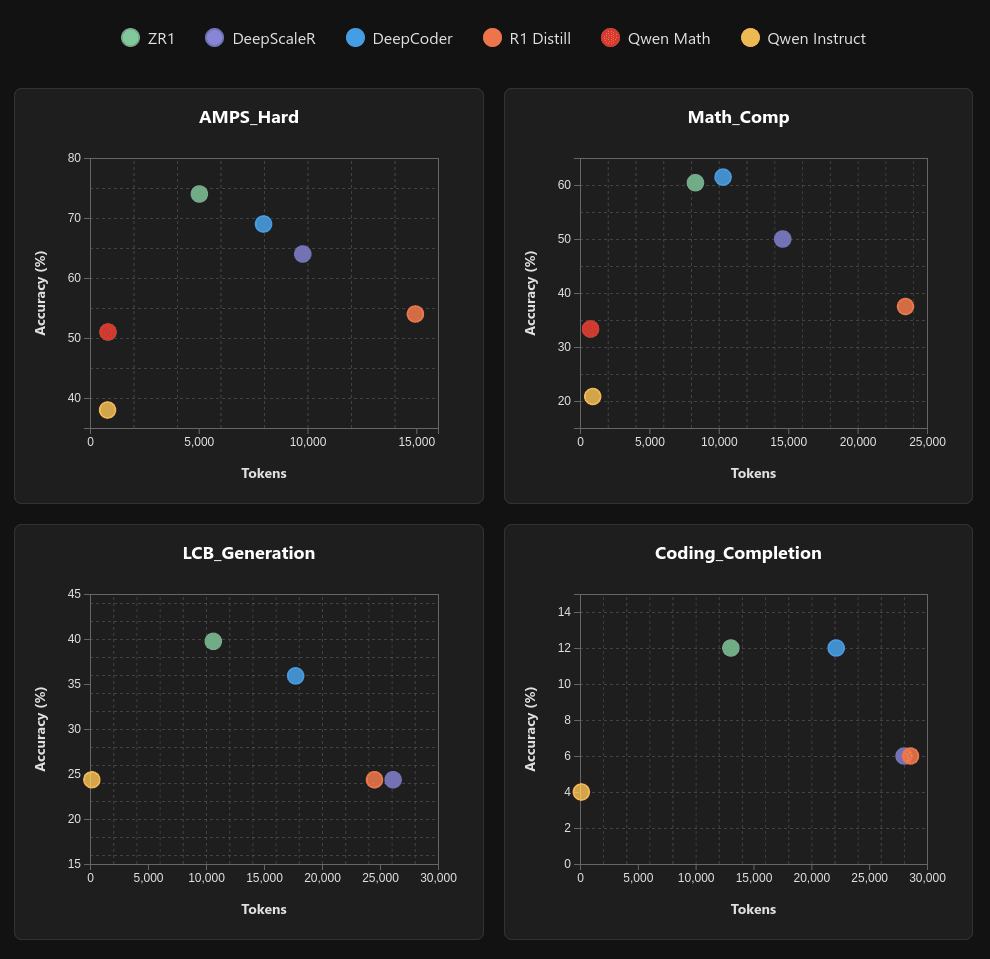
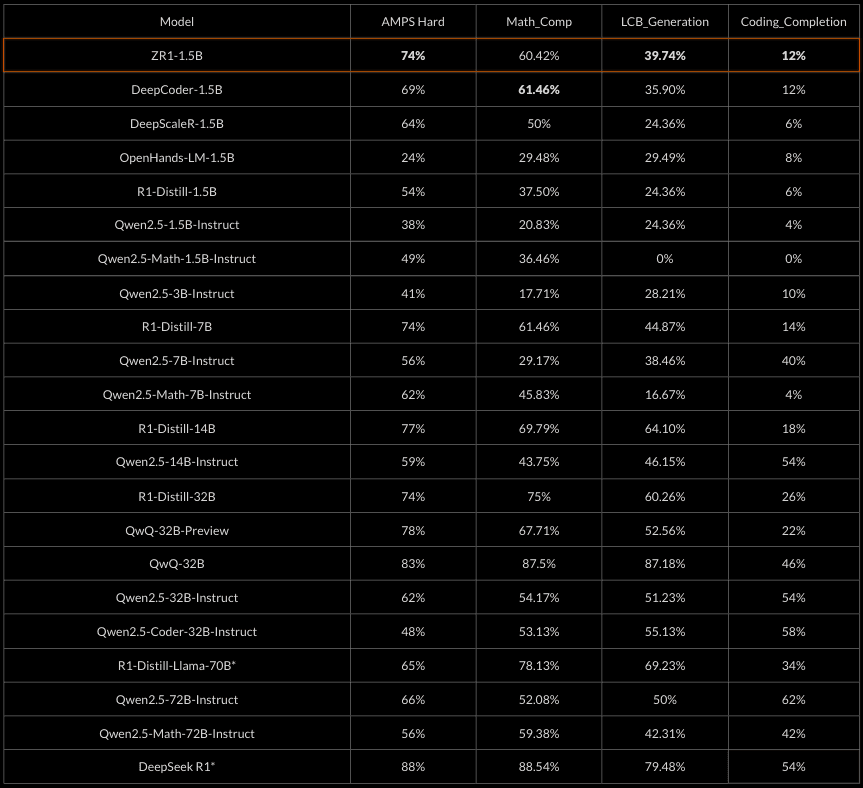
Pass@1 scores with greedy sampling. Livebench 2024-11-25. Bold: Best score at 1.5B scale w/ greedy sampling *reported scores
The ZR1-1.5B model demonstrates robust mathematical reasoning capabilities across diverse benchmarks. It performs exceptionally well when compared to similar reasoning-focused models and can rival much larger non-reasoning models.
We achieve near parity with DeepScaleR-1.5B on competition math evals despite our model having more general coding capabilities.
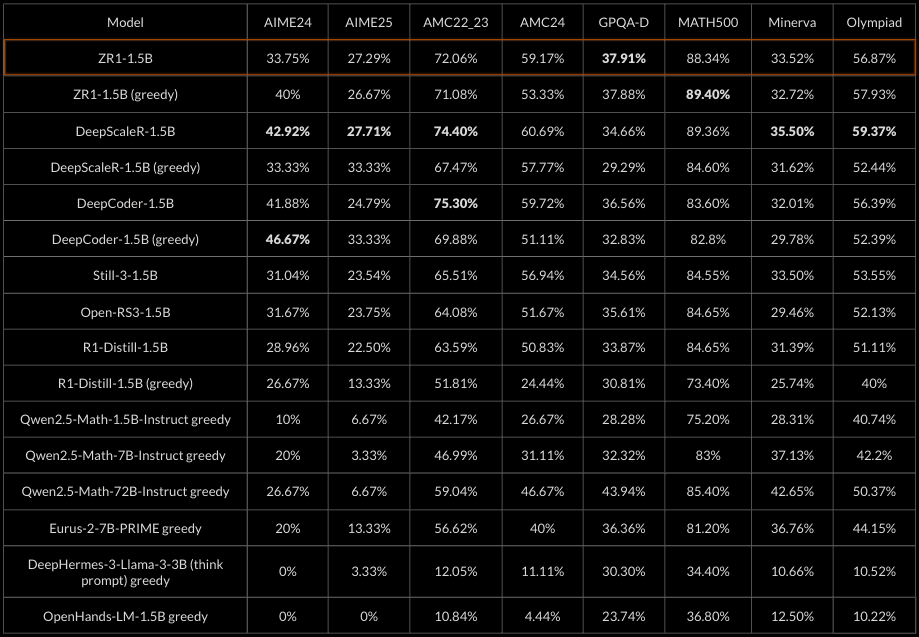
Evals (reported underlined). All numbers pass@1 estimated using n=16
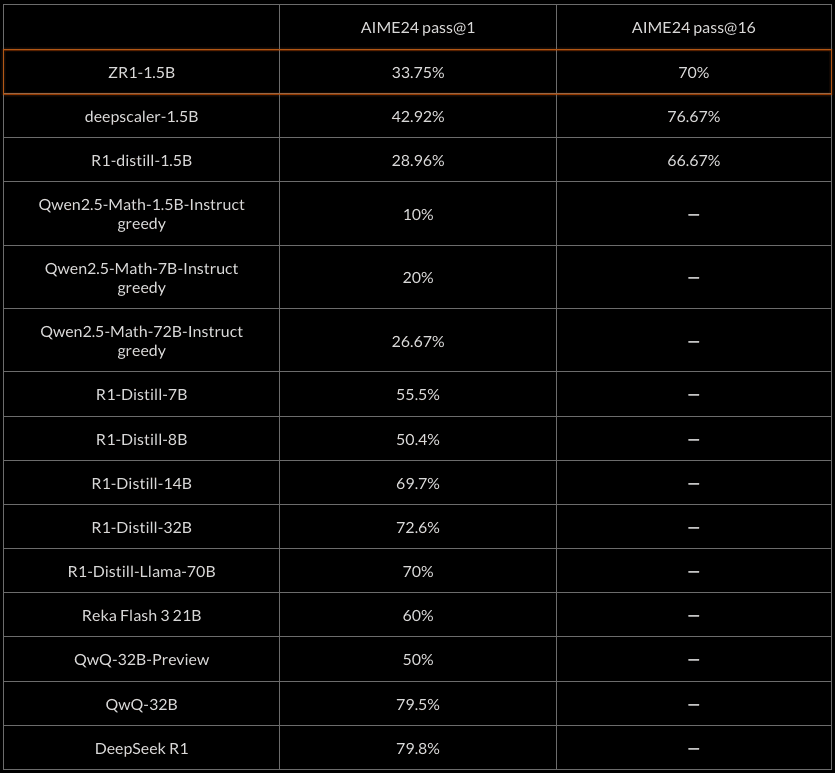
AIME24 Pass@k results
One interesting advantage of small reasoning models such as ZR1-1.5B is that inference is extremely fast and cheap. This leads to the question of whether performing many rollouts and selecting the best answer can outperform a single or a few rollouts from a much larger model in terms of inference efficiency.
To start investigating this question we measure the pass@16 AIME scores of small reasoning models vs pass@1 scores of much larger models. Empirically we find that our ZR1-1.5B model improves substantially in such a setting and outperforms much larger reasoning models such as R1-Distill-Llama-70B and QwQ-32B preview.
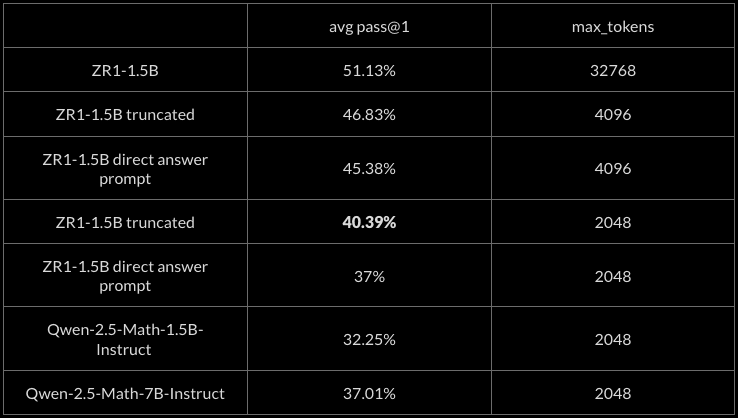
Short CoT
ZR1-1.5B maintains strong performance even with truncated reasoning chains. At just 2048 tokens, ZR1-1.5B achieves 40.39% pass@1 average on math evaluations, outperforming Qwen-2.5-Math-1.5B-Instruct (32.25%) and Qwen-2.5-Math-7B-Instruct (37.01%). This suggests ZR1-1.5B has developed efficient reasoning strategies that retain effectiveness even under token constraints.
The model's ability to perform well across different inference settings offers flexibility for deployment in various computational environments without substantial accuracy loss. We leave more advanced reasoning-effort controls and inference time scaling techniques such as budget forcing or weighted BoN sampling for future work.
Our direct answer system prompt was: “Give a direct answer without thinking first.”
The table reports the average greedy pass@1 score across the following math evals: AIME24, AIME25, AMC22_23, AMC24, GPQA-Diamond, MATH-500, MinervaMath, OlympiadBench
Method
We based ZR1-1.5B on DeepSeek-R1-Distill-Qwen-1.5B. For the RL training, we used PRIME, an online RL algorithm with process rewards, motivated by the improvement over GPRO demonstrated in the paper, as well as potentially more accurate token-level rewards due to the learned process reward model.
We used the training batch accuracy filtering method from PRIME for training stability, and the iterative context lengthening technique demonstrated in DeepScaleR for faster training, which has also been shown to improve token efficiency.
After a warmup period with maximum generation length set to 12k tokens, we sequentially increased the maximum generation length during training, starting at 8k tokens before increasing to 16k and 24k.
We trained on a single 8xH100 node with the following specific algorithmic details:
PRIME + RLOO with token-level granularity
No `<think>` token prefill. 0.1 format reward/penalty
Main train batch size 256 with n=4 samples per prompt. veRL dynamic batch size with max batch size set per GPU to support training with large generation length
Max prompt length 1536, generation length increase over training. Started with 12k intended to ease model into shorter generation length training
12384 -> 8192 -> 16384 -> 24448
Start with 1 PPO epoch, increase to 4 during 24k stage
Accuracy filtering 0.2-0.8 and relax to 0.01-0.99 during 24k stage
Oversample batches 2x for accuracy filtering
And the following training hyperparameters:
KL coefficient 0 (no KL divergence term)
Entropy coefficient 0.001
Actor LR 5e-7
Reward beta train 0.05
Reward LR 1e-6
Reward grad clip 10
Reward RM coefficient 5
For training we utilized the PRIME Eurus-2-RL dataset which combines the following math and code datasets:
NuminaMath-CoT
APPS, CodeContests, TACO, and Codeforces train set
We filtered math data by validating that questions are correctly graded when calling the evaluator with reference ground truth, and we removed all code examples with an empty list of test cases. Our final dataset comprised 400k math + 25k code samples.
Deployment
The lightweight size of the model makes it feasible for on-device deployment, or for very high throughput server deployment. The large improvement from pass@16 indicates that inference time scaling approaches may be able to compete with larger models without adding much latency.
Token Efficiency
Interestingly, we can see that the base distilled R1-1.5B model is very token-inefficient out of the box, only achieving slightly better performance than the specialized Qwen2.5-Math-1.5B-Instruct on LiveBench Math and matching Qwen2.5-1.5B-Instruct on LiveBench Code. After training with reinforcement learning, our model significantly outperforms the base R1-1.5B distill while being much more token efficient.
Our model is also more token-efficient than DeepScaleR, suggesting PRIME or the more diverse dataset and difficulty may have helped with further CoT compression.
Footnote: Training on the Eurus-2-RL dataset did not match the DeepScaleR math evaluation numbers, possibly due to lower quality synthetic math questions in NuminaMath-CoT providing a mixed training signal, or the solvability filtering process with QwQ-preview reducing the difficulty of the dataset. Additionally, the relatively small percentage of code (5%) likely led to math dominating training at the expense of code performance. Training on domain specific datasets and merging resulting models seems to be a potential way to counteract this problem, as demonstrated with SFT in Light-R1.
Discussion
ZR1-1.5B represents our first foray into reasoning models and demonstrates that a single small model can achieve high performance across two fairly distinct domains (competition math and coding). The training of ZR1-1.5B has also revealed the importance of diverse and challenging datasets for improving performance as well as how iterative context lengthening and accuracy filtering can improve performance.
In future works, we plan to improve our training recipe, and develop more general reasoning models at scale trained on larger datasets on more domains where reasoning is beneficial.