
Research
San Francisco, California
In this blog, we describe a novel sequence mixing layer developed here at Zyphra that aims to find a better compromise between memory-compute costs and long-context capabilities than standard sequence mixing layers. We call this layer Online Vector-Quantized (OVQ) attention.
Nick Alonso, Tomás Figliolia, Beren Millidge
Introduction
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
Background: Vector Quantized Attention
Causal self-attention compares a query vector, \(q_{T}\), at position \(T\) to a tensor containing all previous key vectors, \(K\), via a dot-product. These dot-product similarity values are normalized with softmax then used to compute a weighted average over all previous values, \(V\):
\[o_{T} = softmax(q_{T}K^T)V \]
The greater the sequence position, \(T\), the more compute and memory self-attention requires, yielding, quadratic compute and linear memory complexity for pre-fill.
Our novel OVQ layer builds on a little-explored sequence mixing layer called vector quantized (VQ) attention. VQ-attention makes one alteration to causal self-attention: it applies vector-quantization to the keys. VQ-attention uses a pre-trained dictionary, \(D_{k}\), that contains a constant number of centroid vectors, which model the means of dense regions of key space. After keys, \(K\), are computed they are vector quantized, i.e., each key is replaced with its nearest neighbor centroid yielding, \(\hat{K}\). Also, the number of keys assigned to each centroid are stored in a count vector, \(c\). It can be shown that when keys are vector quantized in this way, there is an alternative but equivalent form of self-attention with linear compute and constant memory costs:
\[ \begin{array}{l} o_{T} = softmax(q_{T}{\hat{K}}^T)V \\ = softmax(q_{T}{D_k}^T + \log(c))D_{v'} \end{array} \]
where \(D_{v}\) is a dictionary of centroids fitted to the values, computed on-the-fly during the forward pass. We can see that since the dictionaries are constant size, the compute and memory cost of this operation does not grow with sequence, yielding linear compute and constant memory cost for pre-fill.
Online Vector Quantized Attention
We found that quantizing the keys using a pretrained dictionary \(D_{k}\), as the original VQ attention does, leads to significant performance deficits at long context lengths compared to self-attention. For example, in a basic in-context retrieval (ICR) task, a model that interleaves sliding window attention with VQ-attention (sw-vq) begins to fail prior to 4k context length, even when using a SOTA method for pretraining the key dictionary. A baseline that interleaves sliding window (with RoPE) and standard self attention with NoPE position encodings (sw-nope) solves the task easily and maintains perfect performance beyond training length to 64k.

The only difference between sw-vq and the baseline sw-nope is the quantized keys (see equation above). Therefore, the cause of the performance deficit must be the quantization error, i.e., the deviation between the original key and its nearest centroid. This error adds a bias to the self-attention operation, since quantization error is added to the keys prior to self-attention. Further, the quantization error adds a bias to the gradients, since a straight-through estimator must be used to propagate gradients through the non-differentiable quantization process.
Increasing the number of centroids provides diminishing improvements, so this issue cannot be solved by using ever larger pre-trained dictionaries. We therefore propose an alternative approach. We design a layer that learns \(D_{k}\) on-the-fly during the forward pass instead of during pre-training. We call this online vector quantized attention (OVQ-attention) since now all components \((D_{k}, D_{v}, c)\) are computed on-the-fly during the forward pass. Our hypothesis is that directly fitting \(D_{k}\) to the inputted keys during the forward pass should reduce the quantization error, since \(D_{k}\) is fitted to the current sequence rather than to the average of sequences observed in pretraining. Further, by dynamically learning \(D_{k}\) on-the-fly, we can backpropagate directly through the dictionary state updates and the attention operation removing the need for straight through estimators.
However, there are several questions that need to be addressed in order to compute both \(D_{k}\) and \(D_{v}\) in the forward pass. First is the question of how to initialize the dictionaries, since clustering models are notoriously sensitive to initialization. Second, is the question of how to implement the dictionary updates efficiently. Our approach uses a chunk-wise parallel method that loops through chunks of key-values, performing mini-batch updates on the dictionaries. Our method initializes centroids by setting new centroids equal to a subset of the key-values in each chunk, according to their distance from the existing centroids. We use a method that quickly adds new centroids early in the sequence then slowly adds them later. As the state grows to very long lengths, the state reaches some maximum number of centroids, N, which is a hyper-parameter. Thus, although state size grows it has a hard upper-bound yielding constant memory complexity. Details can be found in the paper, but the intuition can be gained from the figure below.

The figure above provides some intuition for how OVQ-attention can have better long-context processing abilities than standard linear attention and SSM models. OVQ-attention uses a kind of online clustering algorithm to update its state. The state update is tiny since each key-value only updates a single column of the state, \(S = [D_{k},D_{v}]\). Further, unlike linear attention and SSM models, these state updates have fixed size relative to the number of centroids, allowing us to add more centroids without requiring more memory to store the state updates. This allows us to greatly expand the size of our memory state, and thus its memory capacity. Finally, since these updates are sparse, updating only a single column of the memory state matrix, there is very little interference between unrelated key-values, helping prevent in-context, catastrophic forgetting. This is opposed to the standard SSM and linear attention updates, which perform dense updates over the entire state.
Results
We set up our models and baselines so the only difference is the sequence mixing operations. We interleave sliding window layers (with RoPE) with either self-attention with NoPE (sw-nope) , VQ attention with NoPE (sw-vq), or OVQ-attention with NoPE (sw-ovq). We test sw-vq with a large dictionary size (N = 2k). As noted above, OVQ models have dictionaries that grow over time according to a plateauing growth function toward some maximum, N. We train sw-ovq models with small N (1k or 2k), but test at larger dictionary sizes, and find sw-ovq models can dynamically increase dictionary size at test time and receive consistent performance improvements by doing so, successfully generalizing to larger dictionary sizes.
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.
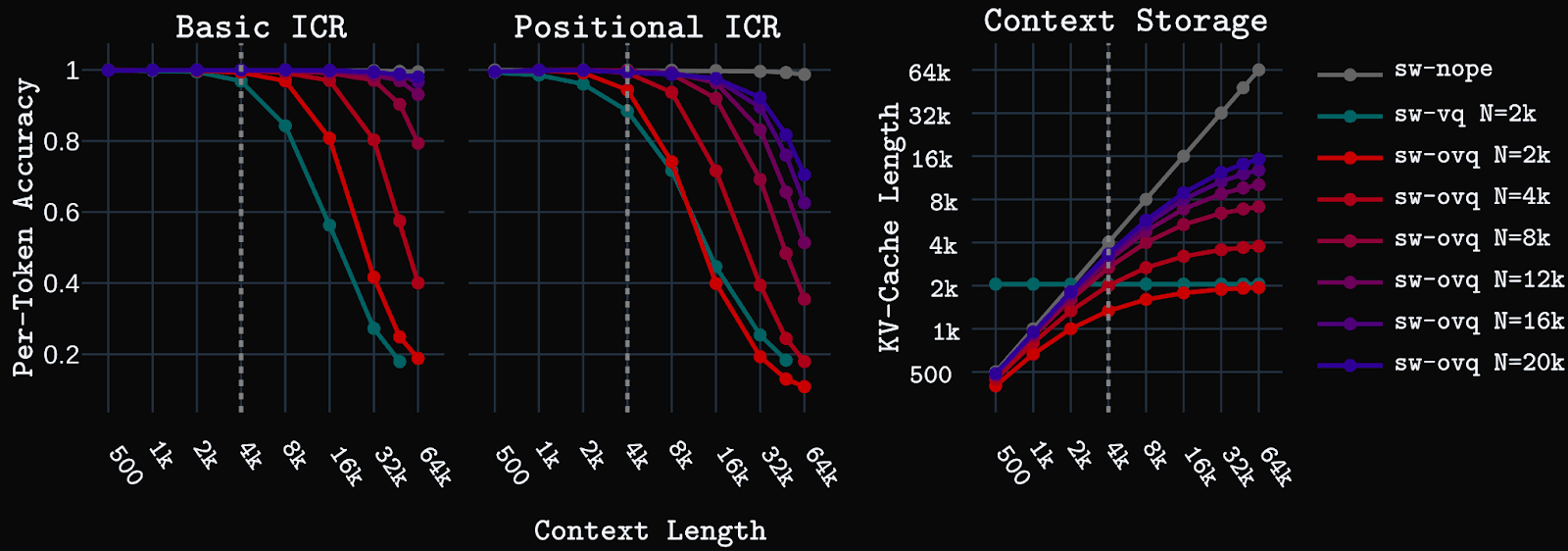
sw-ovq performs significantly better than sw-vq, nearly matching the self-attention baseline at 64k on basic ICR for N=16k-20k, while using less than a quarter of the state/cache size (see right side of figure above). Positional ICR is a harder task for sw-ovq, but we still see OVQ-attention performing well, showing the ability to generalize well to 16k using much smaller KV-cache/dictionary sizes.
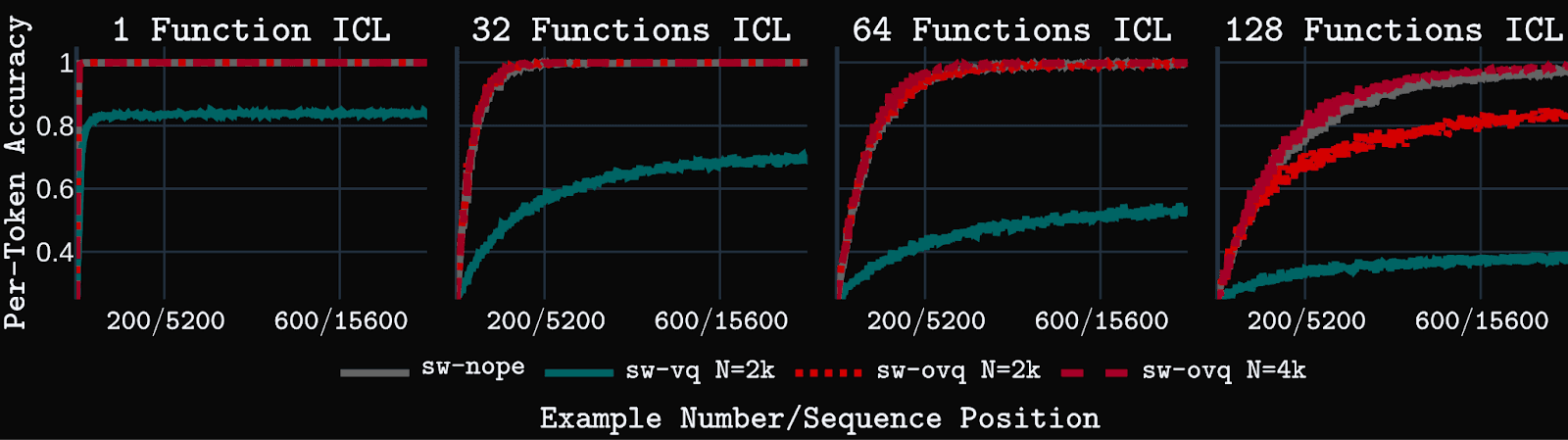
Models are also tested on an in-context learning (ICL) task that requires the model to learn linear regression functions from input-output examples listed in the context. Our version of the task requires long context ICL abilities since examples from multiple functions are listed, thus spreading relevant examples for a particular function over large distances throughout the context. sw-vq fails on this task, even in an easy scenario with a small number of functions to learn. Conversely, sw-ovq is able to solve and match standard attention baseline, sw-nope, even on the hardest ICL task with examples from 128 different functions shown in context. This task requires performing ICL over 16k+ tokens. sw-ovq solves it while using a small state size with <4k centroids.
Similar trends are observed in long-context language modeling on the PG19 dataset. sw-ovq models perform only slightly worse than sw-nope models at long context lengths, and significantly better than VQ-baseline. Further, adding OVQ-layers to Gated Delta Net (gdn) models dramatically improves performance, while maintaining linear compute and constant memory complexity.
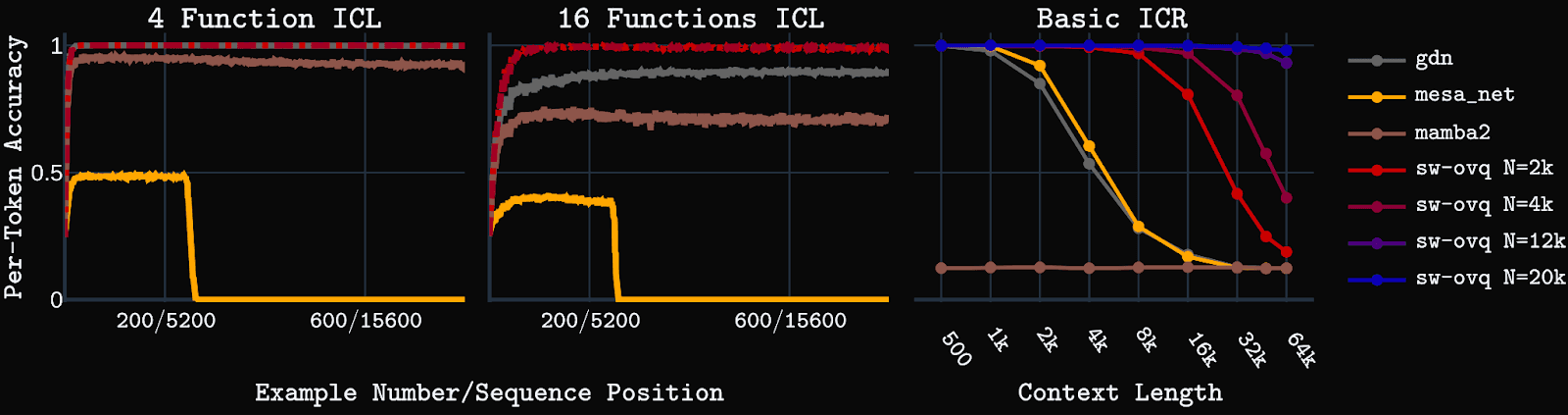
We also compare sw-ovq to several linear attention and SSM baselines on the synthetic tasks including Gated Delta Net, Mesa Net, and Mamba2. We find the OVQ-attention model has far superior long-context capabilities on these tasks. Further results can be found in our arXiv paper.
Conclusions and Future Directions
Creating LLMs and multi-modal agents that can learn continually over extended deployments is one of the final frontiers facing the field of AI. Storing and processing a linearly increasing KV-cache, as self-attention does, is infeasible at the extremely long context lengths faced during such deployments. Sequence compression, via principled learning mechanisms, is needed. However, the current layers that perform such compression, such as SSMs and linear attention, lack the long-term recall and long-context processing capabilities needed for truly long-term coherent agency. Thus, an alternative approach is needed.
OVQ-attention points toward an alternative path: store a dynamically growable, but strictly bounded, memory state that uses efficient sparse updates. Our empirical results suggest this is a promising alternative path forward. Future work will look to further improve the OVQ-attention layer’s performance on long context tasks and develop hardware-efficient implementations that allow for use at large scale.