
Research
San Francisco, California
Zyphra Cloud is a full stack AI platform bringing advanced innovations from Zyphra Research into production for developers, enterprises, and frontier AI hyperscalers. Today, we launch the platform with Zyphra Inference, an AMD-first inference service purpose-built for large open models focused on long-context agentic workloads. Zyphra Inference marks the first step toward a unified platform for open, sovereign AI at scale.
Introduction
Zyphra introduces Zyphra Cloud, a full stack AI platform delivering advanced AI innovations from Zyphra Research to developers, enterprises, and frontier AI hyperscalers. Built on heterogeneous compute and optimized for AMD infrastructure, Zyphra Cloud brings together model serving, agent infrastructure, and scalable compute into a unified platform for building and deploying advanced AI systems.
Today, we are launching Zyphra Inference, the first component of the platform. Zyphra Inference delivers production-grade model serving purpose-built for large MoE models and long-running agentic workloads with long context and large KV & prefix caches.
Powered by AMD MI355X GPUs in partnership with TensorWave, Zyphra Cloud Inference serves leading open models including Kimi K2.6, DeepSeek V3.2, and GLM 5.1.
Zyphra Cloud represents the productization of Zyphra Research — translating advances in model architecture, parallelism, and systems design into real-world performance gains across latency, throughput, and cost.
Over time, the platform will expand to support post-training, reinforcement learning environments, and agent-native infrastructure, forming the foundation for open, sovereign AI at scale.
Zyphra Inference - An AMD-first Inference Cloud
As frontier open models climb into the trillions of parameters and context windows stretch into the millions of tokens, large intra-node memory capacity and highly performant parallelism becomes increasingly vital for efficient serving.
To avoid substantial inter-node overheads the full model replica, as well as every user’s KV and prefix caches must fit in VRAM. Agentic workloads exacerbate these bottlenecks with long contexts, many-turn workflows, and high concurrency. A single user running many agents may hold dozens of long-running sessions, each with its own long context and requirements for low latency.
Three hardware properties of the MI355X make it particularly attractive for modern long-context and agentic serving:
Memory Capacity: Each MI355X provides 288 GB of HBM3E, yielding 2.3 TB per 8-GPU node. More memory translates into less parallelism per model instance, more users supported per node, and larger KV/prefix caches. Ultimately resulting in less parallelism overhead and fewer users regulated to queues.
Bandwidth: Each MI355X has HBM bandwidth of 8 TB/s per GPU. While most operations during inference are compute-bound, several regimes remain bandwidth-bound, including low-batch decode during off-peak hours, decode steps following a speculator miss, and long-context attention, where each generated token streams the full KV cache into SRAM from HBM. Higher bandwidth directly improves throughput and latency in these regimes. Access to increased bandwidth also accelerates the development of kernels because there is less tuning complexity in prefetching and async memory movement. This enables quicker adoption and performance optimization of new models and inference regimes.
Flexible Quantization: the MI355X exposes MXFP8, MXFP6, and MXFP4 matrix cores, which enables substantial flexibility in quantization. This flexibility combined with Zyphra’s quantization-aware model training means we can deploy aggressive low-precision schemes without sacrificing model quality.
Zyphra Inference demonstrates that these properties make MI355X highly competitive at serving in all inference regimes and especially excels at serving long-horizon agentic workloads on very large models.
Example: Serving Kimi K2.6
Kimi K2.6 is a 1T parameter model and ships with native INT4 weights, resulting in a model replica of approximately 545 GB. Comparing one 8x-B200 node to one 8x-MI355 node:
For one 8x-B200 node its 1,536GB total HBM is allocated to:
Weights - 545 GB
Activations & Runtime overhead (configurable and approximate) - 80GB
Serving caches - 911 GB
For one 8x-MI355x node its 2,304GB total HBM is allocated to:
Weights - 545 GB
Activations & Runtime overhead (configurable and approximate) - 80GB
Serving caches - 1,679 GB
The MI355x node has nearly twice as much available serving cache compared to the B200 node which translates to more users per node, longer context lengths, and the need for less parallelism.
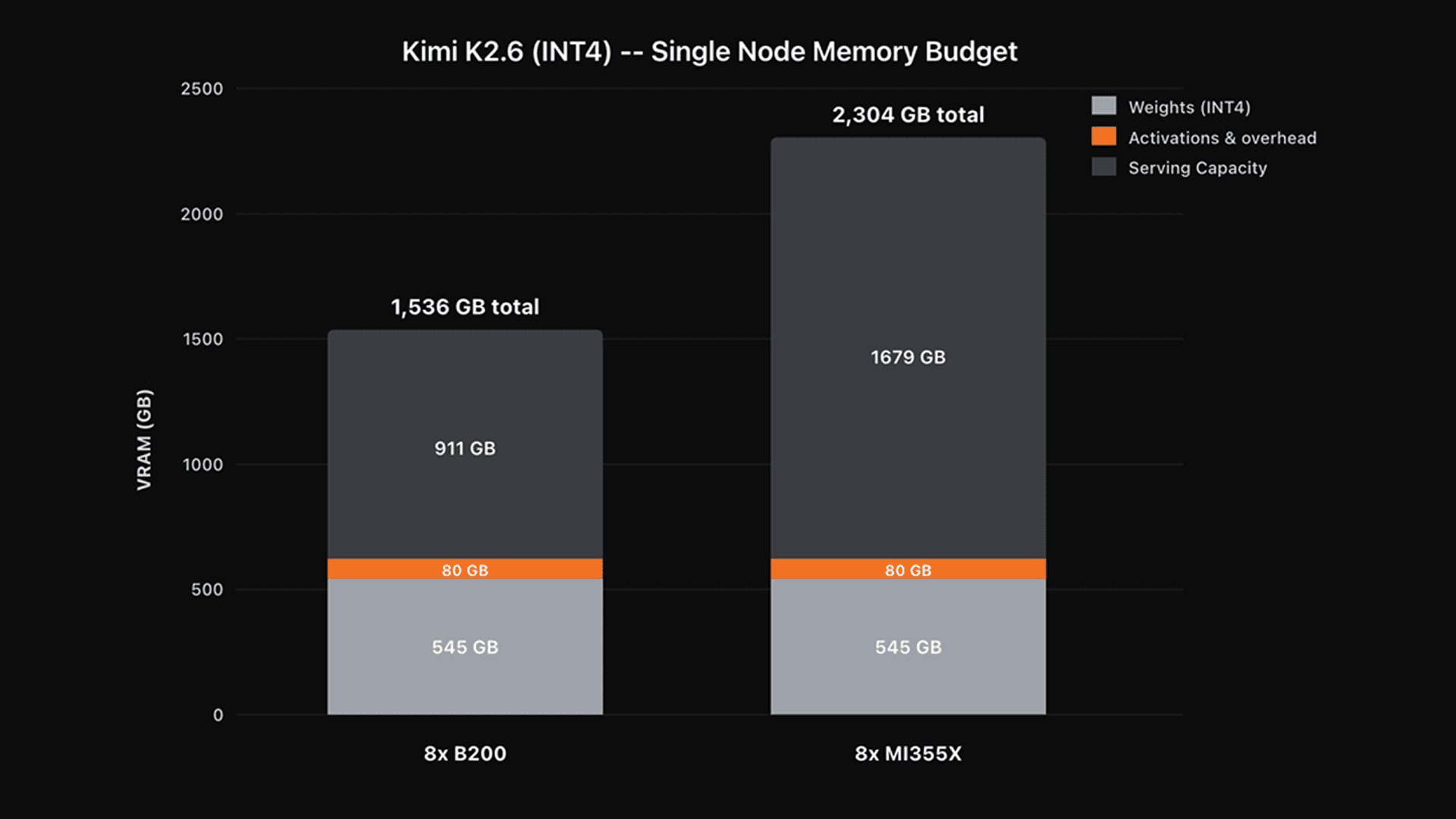
Single-node HBM memory budget for Kimi K2.6 (INT4) on 8x B200 versus 8x MI355X.
Assuming a 256K context length per agent (the max context length for Kimi K2.6), this translates to ~100 active agents on one B200 node compared to ~184 active agents on one MI355X node.
The MI355X node can hold almost 2 times the number of agent sessions in GPU HBM as the B200 node before sessions are evicted.
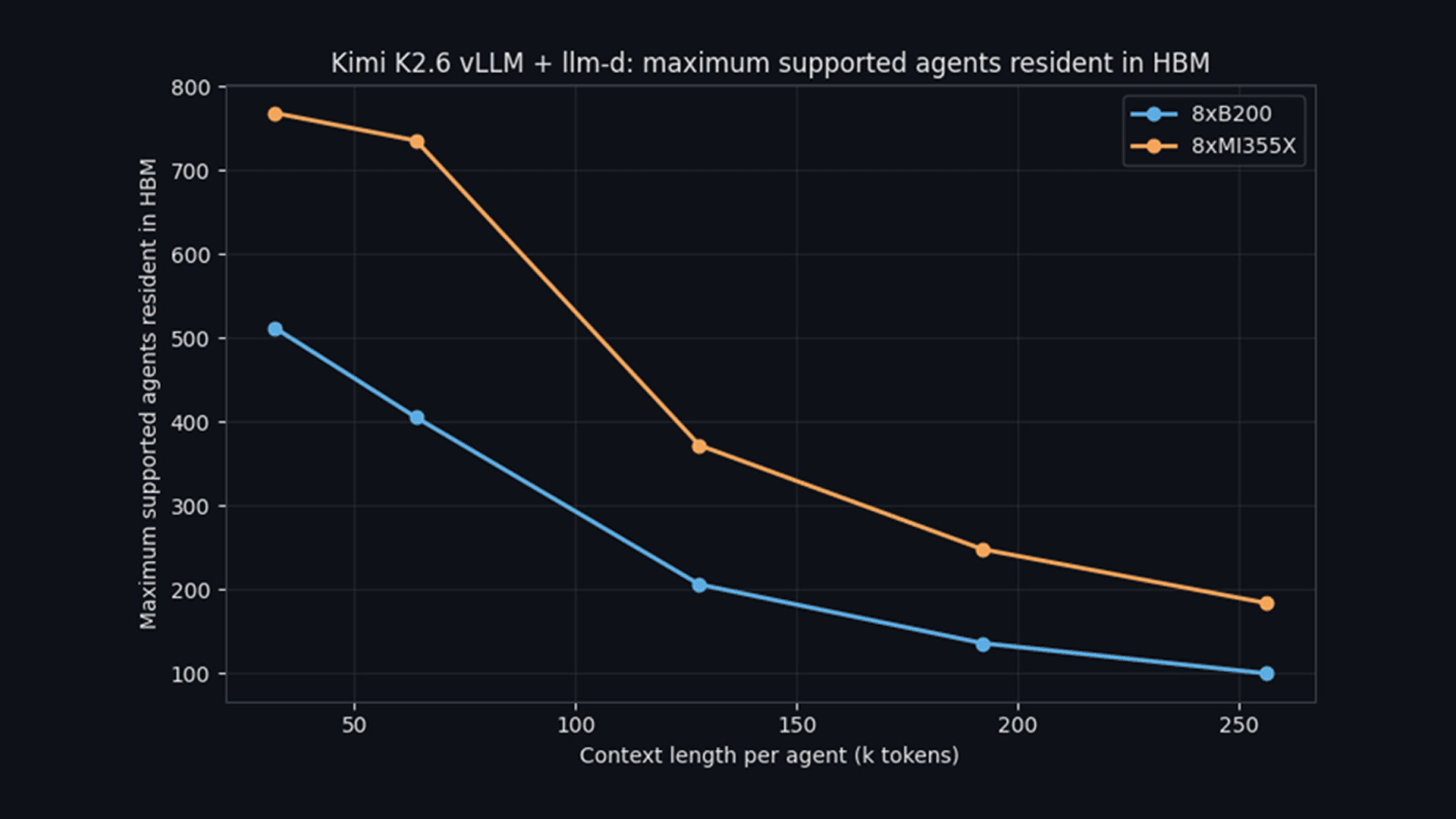
Maximum agents resident in HBM versus context length per agent
This is important for users. Once the resident set exceeds available HBM, the prefix and KV caches are evicted and must be recomputed on the next request. This recomputation overhead causes throughput to drop. A synthetic example of this effect is shown in the chart below where throughput begins to significantly degrade at ~100 active 256K sessions on the 8x B200 node compared to ~184 active 256K sessions on the 8x MI355X node. The 8xMI355X node is able to fit more traffic on fewer GPUs before it begins to degrade, which enables us to serve more traffic on fewer resources.
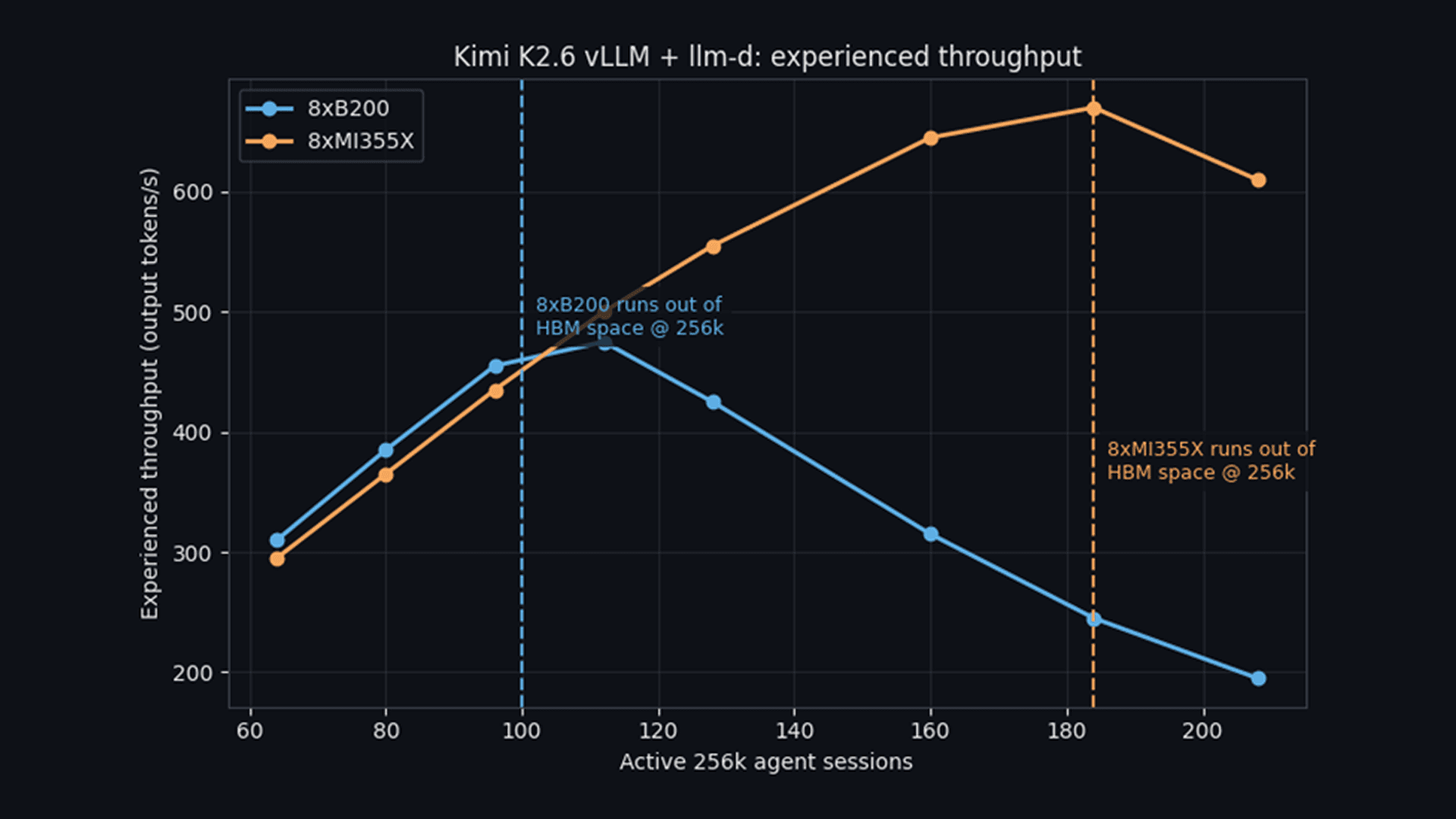
Output throughput versus active 256K sessions.
Similar patterns hold across the other models hosted on Zyphra Inference. MI355X roughly doubles the serving budget across GLM 5.1, DeepSeek V3.2, and DeepSeek V4-Pro (coming soon!).
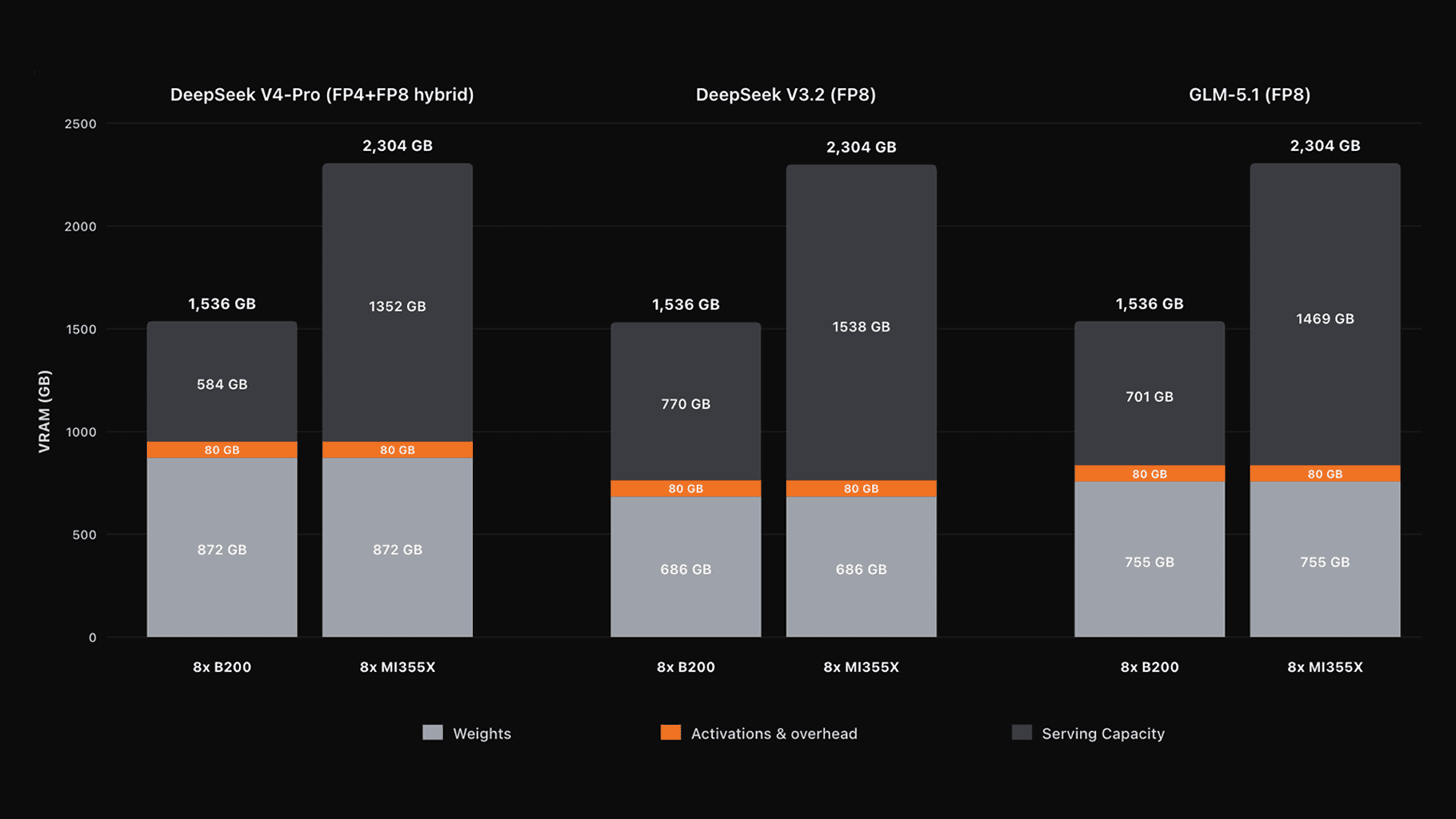
Single-node HBM memory budgets across GLM 5.1, DeepSeek V3.2, and DeepSeek V4-Pro.
The synergy between Zyphra Research & Zyphra Cloud
Zyphra Cloud is the productization of many of the innovations coming out of Zyphra Research. As an organization, Zyphra is dedicated to deep research across next-generation architectures, multimodal world models and silicon-level performance.
This creates a tight feedback loop between research and production. Advances in architectures, parallelism, and training systems translate directly into gains in latency, throughput, and cost in Zyphra Cloud, while real-world workloads inform how we design and train the next generation of models.
By innovating across the full stack, Zyphra can co-design and optimize advanced AI systems end-to-end, enabling faster iteration and more efficient deployment.
Training-informed Inference (Research → Cloud)
Zyphra Inference benefits from the optimized low-level software stack developed during the pretraining of ZAYA1-base at scale on AMD, along with novel parallelism schemes and custom kernels.
AMD hardware is well-suited to the inference problem, and Zyphra is deeply optimized for AMD, enabling us to translate raw hardware into efficient, high-performance serving by directly applying training-time innovations to inference.
Parallelism schemes
AMD's intra-node fabric is point-to-point rather than switched, which favours full-participation collective communication if the message size is large enough. Ring Attention, the standard sequence-parallel attention algorithm, can perform poorly on this topology because its communication pattern is a point-to-point ring. We instead use Zyphra's Tree Attention, which restructures the attention collective as a collective tree-reduction over per-device flash attention kernels. The result is substantially better AllReduce bus bandwidth and lower AllReduce latency at the message sizes required care for long-context inference.
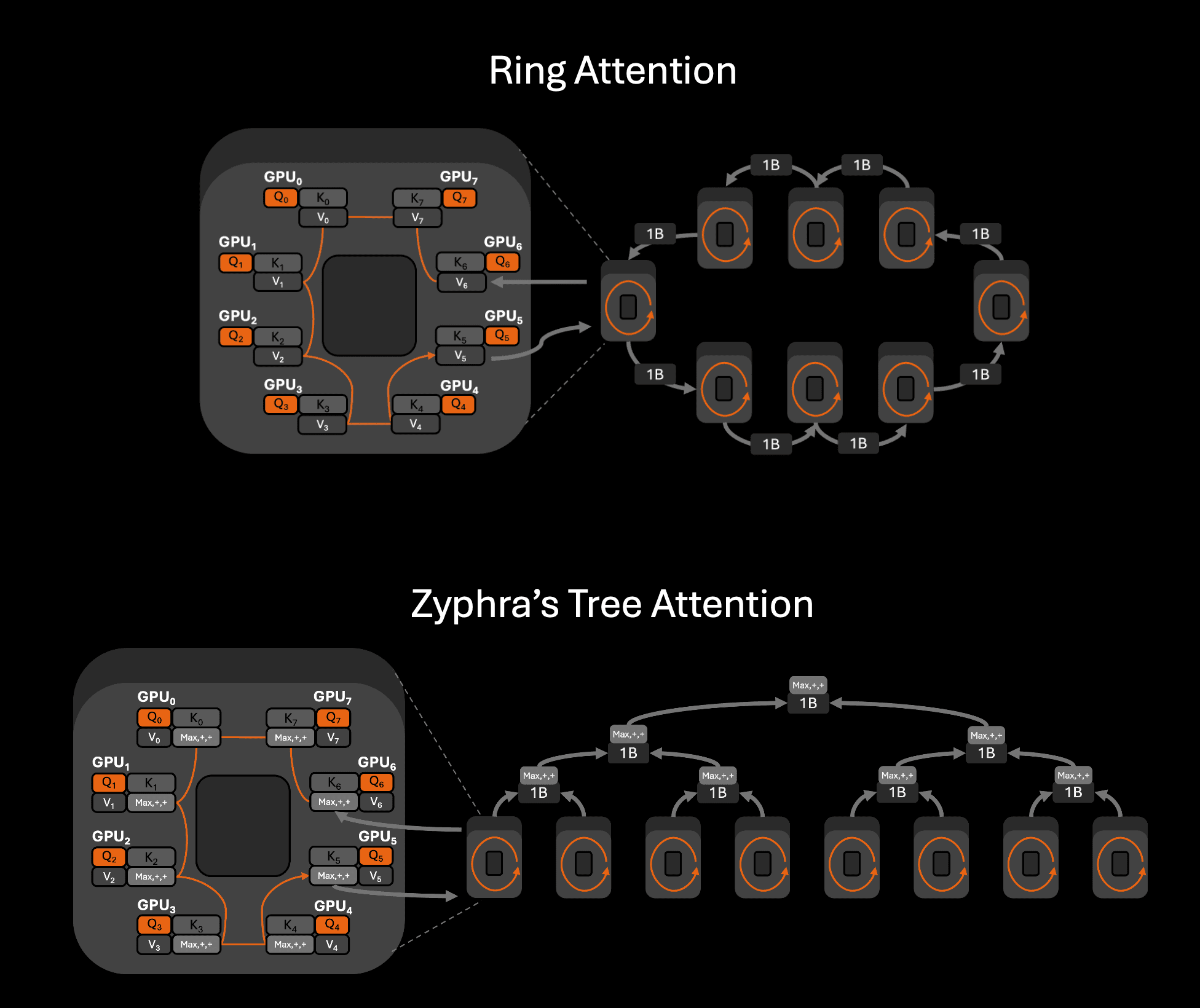
For models that are simultaneously large and serve long contexts, we additionally fold the tensor-parallel and sequence-parallel axes onto a single device axis, which we call Tensor and Sequence Parallelism (TSP). Standard TP+SP allocates a product of ranks (T x S devices), which on a fixed node means giving up data-parallel replicas, creating smaller parallelism sizes for each axis whose performance is penalized by the point-to-point intra-node fabric, or spilling the model-parallel group across the slow inter-node fabric. TSP collapses both axes onto a single dimension of degree max(T, S), preserving the memory benefits of both while keeping the model-parallel group inside high-bandwidth intra-node links. We discuss TSP in detail in our companion technical post.
Forward-pass kernels
We deploy a variety of novel and custom kernels we developed internally including a custom ROCm implementation of Flash Attention and a fused MoE kernel that handle the routing, expert dispatch, and grouped GEMM in a single pass.
Model quality
We are also exploring MI355X's MXFP support with aggressive mixed-precision quantization to dramatically improve throughput for minimal quality degradation. Moreover, we also plan to apply speculative decoding using larger and more capable draft models than is typical. This will enable us to serve with substantially superior throughput and latency without sacrificing quality, and our experience training will enable us to produce this quickly and to rigorously test and maintain model quality by understanding and controlling the sources of degradations.
Inference-informed Training (Cloud → Research)
Operating an inference cloud at scale enables us to better anticipate inference overheads and challenges which provides vital feedback for improving architectures, optimizations, and training methodologies. Optimization specifically has a high degree of overlap across training and inference. For instance:
Backward-pass kernel efforts inform forward-pass kernels and vice-versa
Quantization effects are deeply understood from the GEMMs-level up
RL post-training stack optimizations
Inference engine optimizations improve both the RL post-training stack and production inference simultaneously
Looking forward
Zyphra Inference is in active development. We are focusing heavily on improved kernels, quantization, and training better speculators. We will also be supporting new and better open-source models as they are released, and are actively working towards DeepseekV4-Pro support.
Zyphra Cloud is designed to expand beyond inference into a broader integrated platform. Upcoming capabilities include distributed post-training services such as reinforcement learning and fine-tuning, sandboxed agent and development environments powered by AMD EPYC™ CPUs, and access to dedicated GPU clusters and bare-metal infrastructure. Together, these components provide a unified environment for building, training, and deploying AI systems on AMD.
For more information about Zyphra Cloud visit www.zyphra.com/cloud or to access Zyphra Cloud directly go to cloud.zyphra.com For the technical details on Tree Attention, TSP, and our kernel work, see the accompanying technical reports here.