
Research
San Francisco, California
Zyphra presents Tensor and Sequence Parallelism (TSP), a novel parallel sharding strategy for training and serving long-context transformer models.
Vasu Shyam, Anna Golubeva, Quentin Anthony
Introduction
As model-sizes and context lengths grow into the trillions of parameters and millions of context lengths, GPU memory has become a central bottleneck in both model training and inference. Training or serving a model at scale typically requires combining several forms of parallelism.
Tensor Parallelism (TP) shards model weights across GPUs, reducing the memory cost of a model’s parameters and, in training, gradients and optimizer states, but requires additional communication overhead for every sharded block. Sequence Parallelism (SP) shards the token sequence across GPUs, reducing the activation memory and KV cache per GPU and enabling long context training and serving.
Since TP shards model weights but does not touch activations, it is extremely effective when model-weights are the principal bottleneck, but declines in effectiveness for longer contexts when activation memory becomes substantial. Conversely, SP shards the activations and so excels in enabling long contexts, but does not address the usually large ‘fixed costs’ of parameter and optimizer state memory. TP and SP are thus highly complementary, with TP sharding parameters and SP sharding activations.
However, in standard multi-dimensional parallelism setups, TP and SP are assigned to separate dimensions of the device mesh. Along one dimension, the parameters are sharded and then the sequence is sharded along an orthogonal dimension. This means that using TP and SP together consumes a product of ranks – i.e., with a TP degree of T and SP degree of S, the combined model-parallel group requires T x S devices.
Because the total device count is fixed, this strategy has a substantial cost. Allocating more ranks to TP and SP leaves correspondingly fewer replicas for data or other parallelism. Moreover, if both TP and SP degrees are large, then their product may not fit within a single node’s high-bandwidth interconnect domain (AMD Infinity Fabric or NVLink) and instead be forced to spill onto lower-bandwidth inter-node interconnects such as Ethernet or InfiniBand which stresses network bandwidth, increases the difficulty of overlapping communication with computation, and ultimately could decrease training iteration time or inference throughput.
The core insight of TSP is that we can ‘fold’ TP and SP onto the same device axis. What this means concretely is that instead of having T x S ranks assigned in orthogonal dimension on the device mesh, we use only a single dimension and assign N ranks to it where N is the larger of T and S.
By combining TP and SP on a single GPU, TSP dramatically reduces the per-GPU memory peak, enabling either larger models to fit within a given topology or else allowing larger batch sizes or less parallelism to be used. However, TSP comes at the cost of extra communication since essentially each GPU must perform both TP and SP communication strategies for every forward and backward pass. We show, however, that in many realistic regimes, the benefits of TSP strongly outweigh these costs.
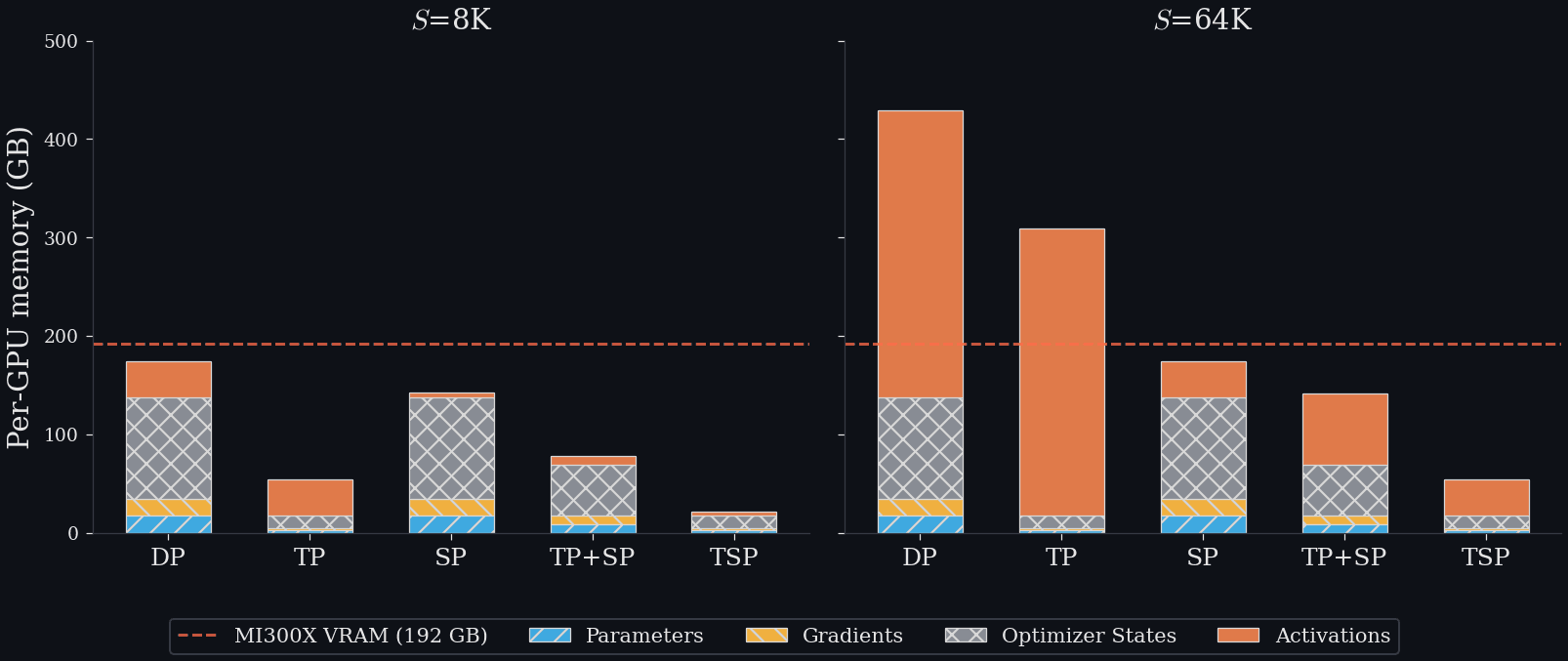
The memory benefits of TSP for training at 8k and 64k. The dotted line represents the 192GB VRAM of the MI300x GPU. If a parallelism scheme crosses this line it will OOM.
Tensor-Sequence Parallelism
TSP assigns each GPU two responsibilities simultaneously:
It owns a shard of the model weights.
It owns a shard of the input sequence.
Thus across a D-way TSP group, each GPU stores both 1/D of the model state and 1/D of the activation sequence. This gives TSP the memory profile of combining TP and SP, but without requiring a D × D two-dimensional layout.
However, this strategy necessitates additional communication. If each rank has only part of the weights and part of the sequence, then both the parameters and activations must be simultaneously gathered and sharded correctly. TSP does this with two communication schedules: one for attention and one for the MLP.

A visual schematic of the memory layout of TSP vs SP, TP, and TP+SP. Note that TP+SP uses two orthogonal axes to split the parallel groups while TSP lets both weights and activations be sharded simultaneously.
For attention, TSP loops over weight shards. At each step, one rank broadcasts its packed attention weights to the rest of the group. Each GPU then computes local Q, K, and V projections on its own sequence shard. The K/V tensors are all-gathered across the sequence dimension so that every rank can reconstruct the full attention context for its local tokens.
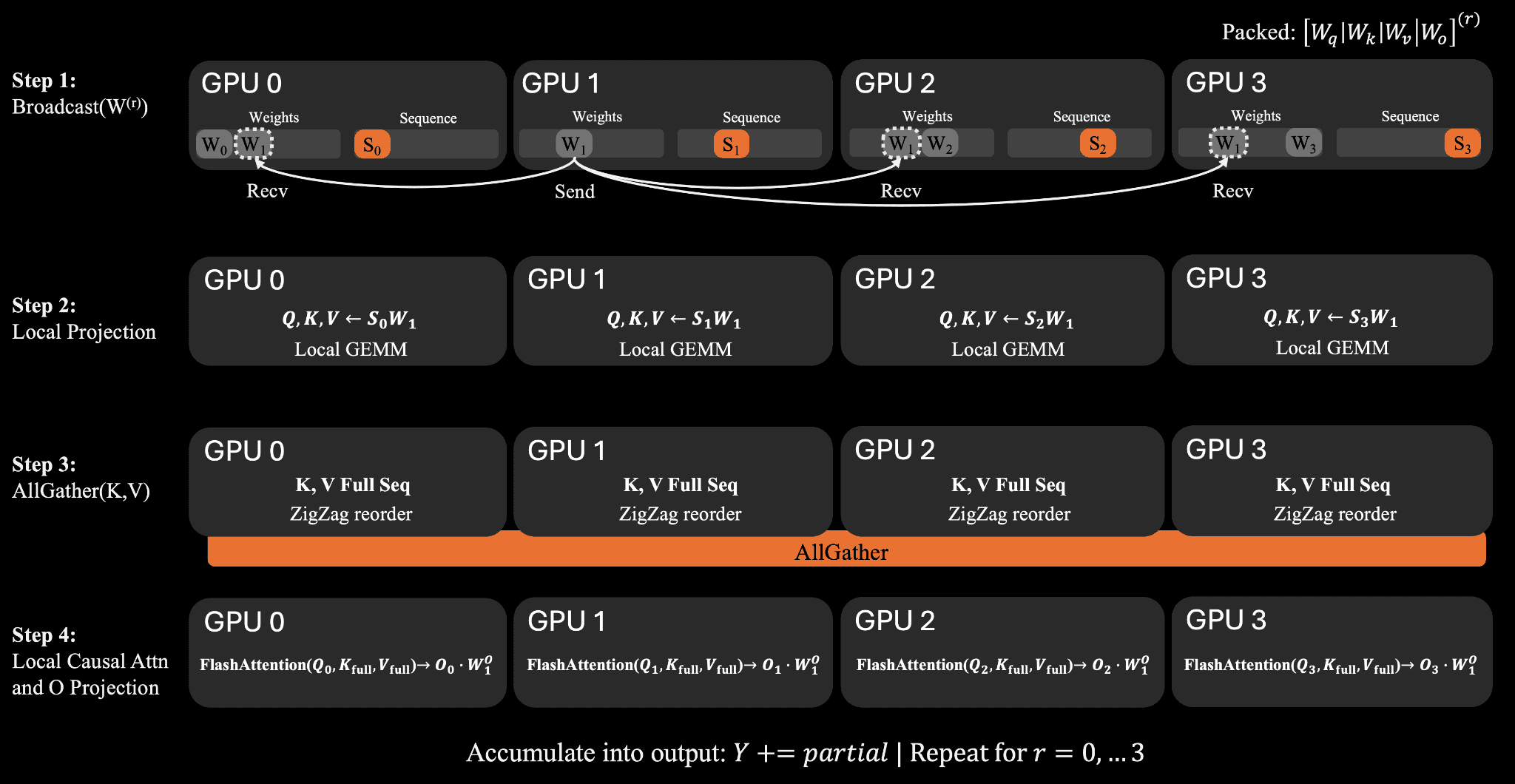
A visual schematic of the communication schedule for TSP attention.
For the gated MLP, TSP uses a ring schedule. Weight shards circulate from rank to rank while each GPU accumulates partial outputs locally. This removes the need for the standard tensor-parallel all-reduce in the MLP and makes the communication pattern easier to overlap with GEMM compute.
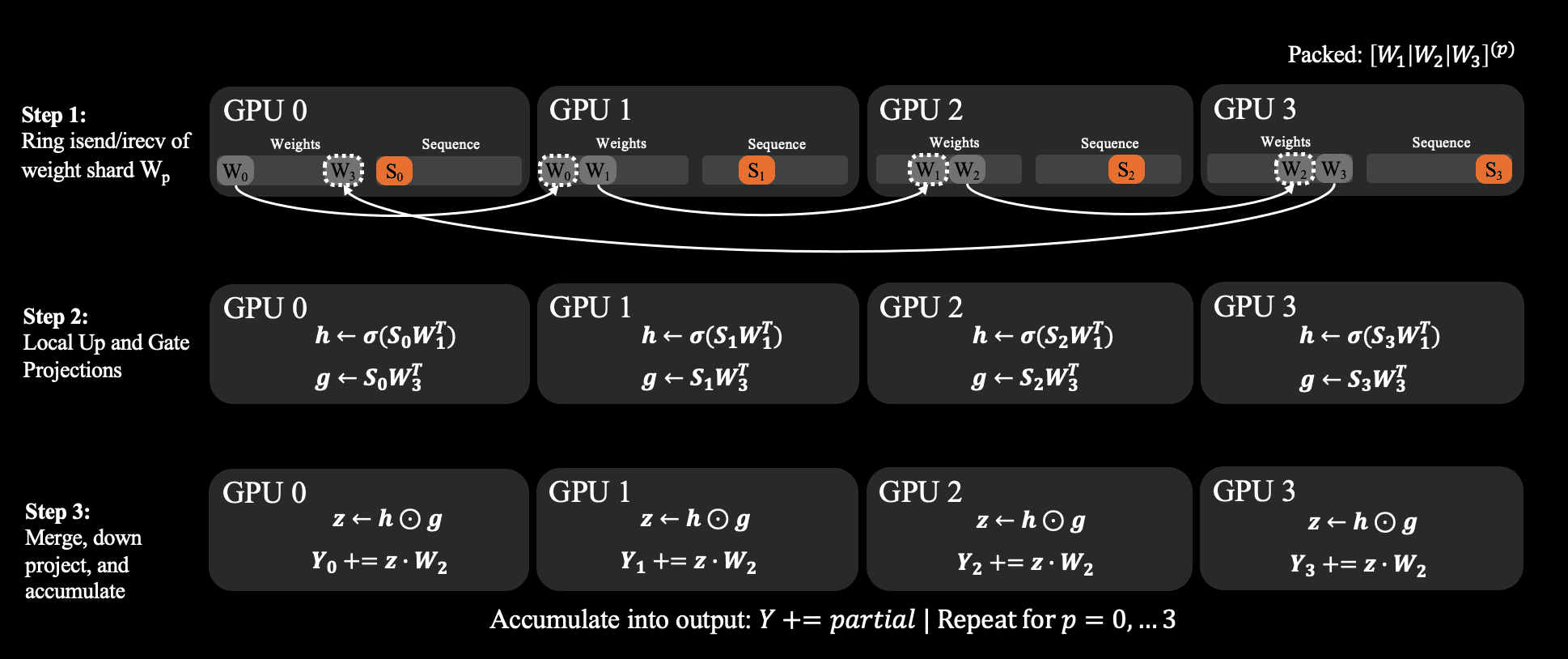
Results
We evaluate TSP on our MI300X training cluster and compare against tensor parallelism, sequence parallelism, and conventional TP+SP baselines.
First, we compare per-device peak memory of each strategy across sequence lengths from 16K to 128K tokens on a single 8-GPU node. We observe that TSP achieves the lowest peak memory of all tested strategies. At 16K tokens, TSP and TP are nearly identical, using approximately 31.0 GB and 31.5 GB per GPU respectively. This is expected since, at short context lengths, activation memory is minimal and the weights are the principal bottleneck. As sequence lengths grow, however, activation memory grows unimpeded for a pure TP strategy while TSP grows at the much smaller rate of SP. This is highly visible at 128K tokens. TSP uses 38.8 GB per GPU, compared to 70.0 GB for TP and 85.0 GB / 140.0 GB for the tested TP+SP factorizations.
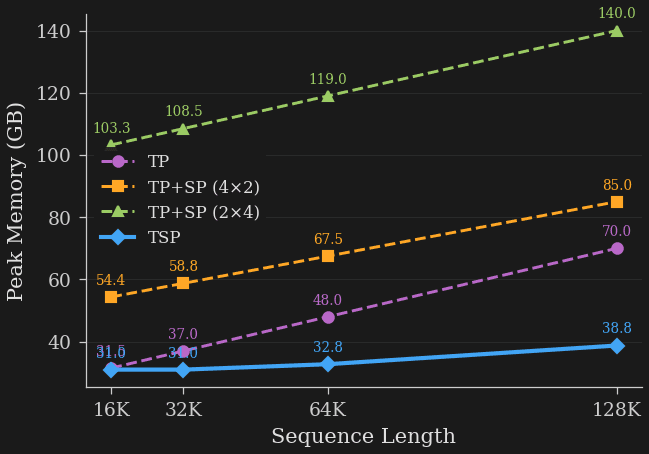
Peak Memory vs Sequence length for TP, TP+SP, and TSP. TP and TSP start out similar when parameter memory is the bottleneck, but due to the SP component, TSP peak memory grows at a substantially smaller rate and dramatically outperforms at longer sequence lengths.
We see that TSP remains close to TP in the short-context regime, where weight-proportional memory dominates, and then increasingly diverges in the long-context regime as activations become dominant. TSP inherits TP's reduced memory at short context and SP's reduced memory at long context, without requiring the two-dimensional device allocation of conventional TP+SP.
TSP also maintains strong throughput at large scale. We test on 128 full nodes, or 1024 MI300X GPUs. TSP outperforms matched TP+SP baselines across 32K–128K context lengths, with the advantage widening at higher folded degrees. With high parallelism (D=8) and long contexts (128K sequence length), TSP reaches 173M tokens/sec compared to 86M tokens/sec for the matched TP+SP baseline, a more than 2x speedup.
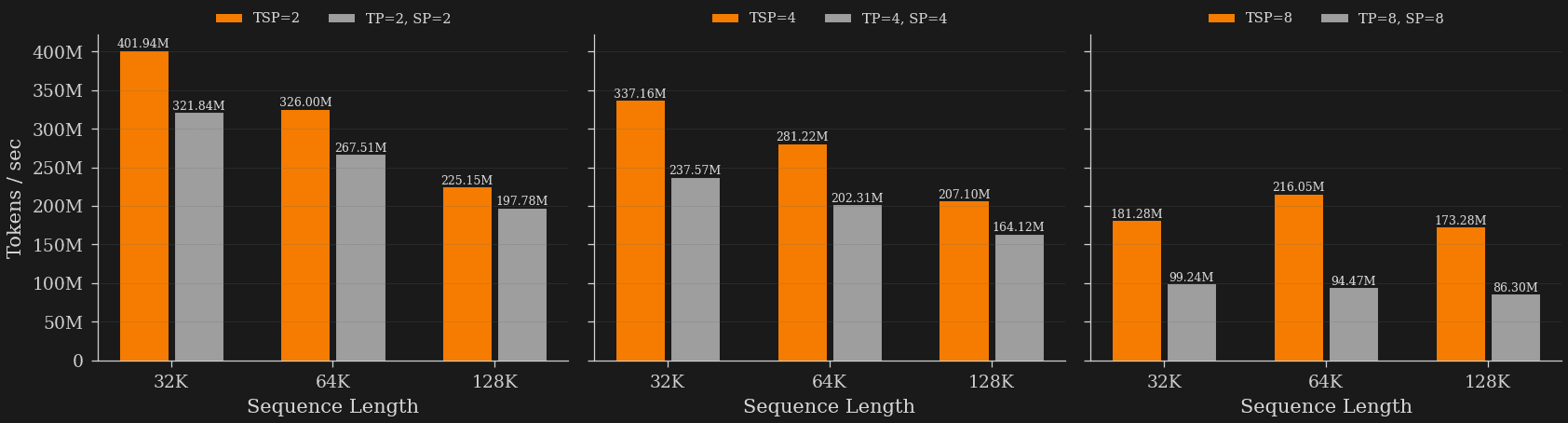
Throughput (tok/s) at different sequence lengths and parallelism strategies. TSP results in substantially higher throughput than various TP+SP configurations, and TSPs advantage grows with greater sequence length.
One major benefit of TSP is in reduced replication of weights and activations. The results above suggest that in long-context and memory-constrained settings eliminating replication can be more important than minimizing communication volume, especially when communication volume occurs over high bandwidth intra-node links and can be overlapped with compute.
It is important to note that TSP is not a silver bullet, nor intended to replace all existing parallelism strategies. Instead, it adds a new point in the design space. TSP can be inserted as a flexible axis wherever the parallelism budget would otherwise force model-parallel groups across slow links, which makes it a useful addition to the pool of potential parallelism schemes and enables easier optimization to future or unforeseen hardware topologies.
TSP also composes orthogonally with the existing axes of multi-dimensional parallelism such as expert, pipeline, and data-parallelism. As context lengths continue to grow and memory pressure becomes the paramount constraint, we believe that parallelism schemes like TSP will become increasingly important.
For the full derivations and theoretical modelling of the FLOP and communication volume, algorithm details, and detailed benchmarking results, read the technical report on arXiv.