
Model
San Francisco, California
Zyphra releases ZAYA1-8B, an AMD-trained MoE model which performs strongly on complex reasoning, mathematics, and coding tasks.
Robert Washbourne, Rishi Iyer, Tomás Figliolia, Henry Zheng, Ryan Lorig-Roach, Sungyeon Yang, Pritish Yuvraj, Quentin Anthony, Yury Tokpanov, Xiao Yang, Ganesh Nanduru, Stephen Ebert, Praneeth Medepalli, Skyler Szot, Srivatsan Rajagopal, Alex Ong, Bhavana Mehta, Beren Millidge
Introduction
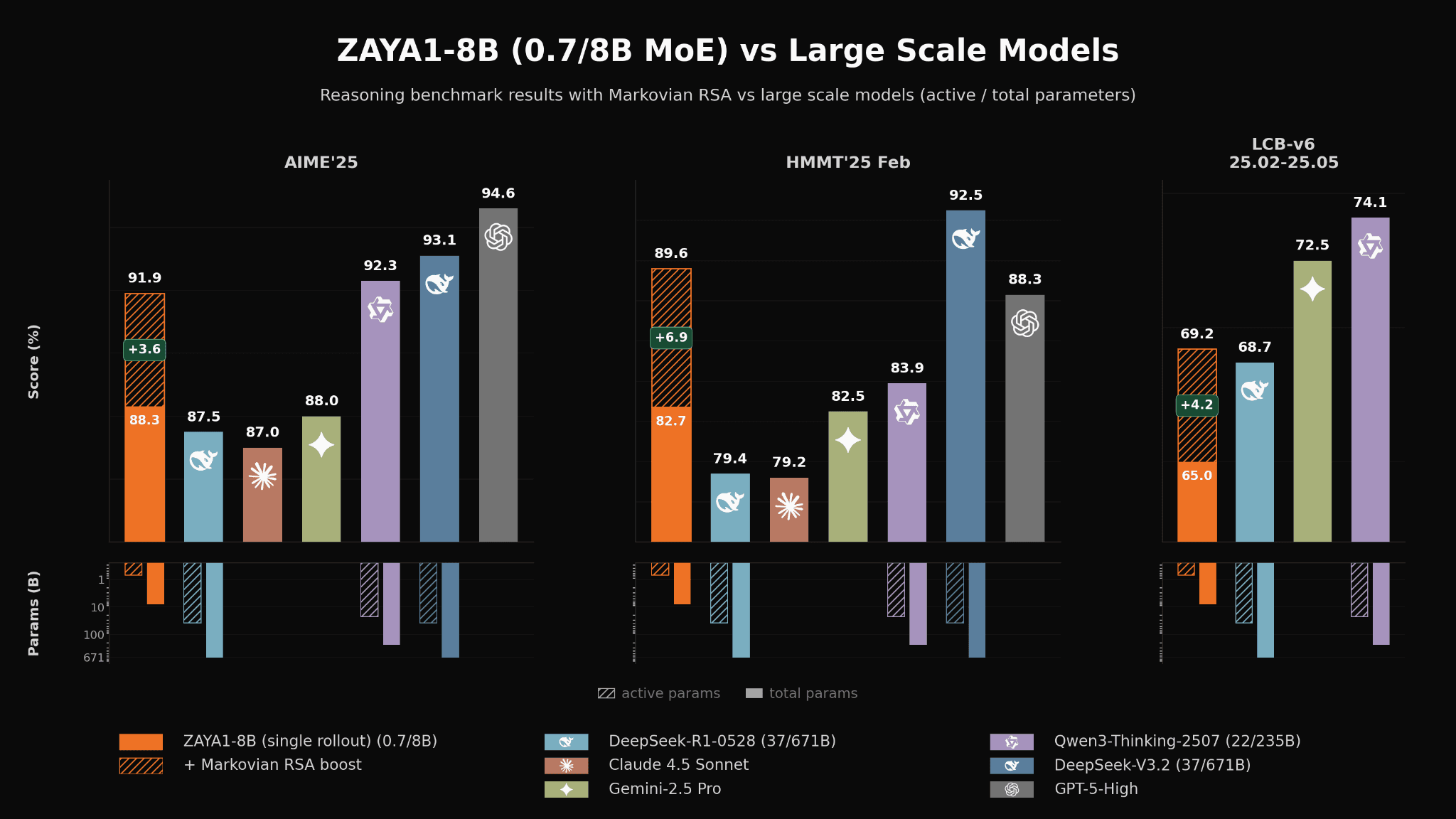
Mathematical and coding performance of ZAYA1-8B vs substantially larger open-weight and proprietary reasoning models.
Today Zyphra is releasing ZAYA1-8B, the first MoE model pretrained, midtrained, and supervised fine-tuned on an AMD Instinct™ MI300 stack. ZAYA1-8B delivers frontier intelligence density per active parameter and outperforms substantially larger open-weight models on certain mathematics and coding benchmarks.
At under 1 billion active parameters, ZAYA1-8B performs strongly on reasoning, mathematics and coding benchmarks, matching or exceeding the performance of models many times its size such as Mistral-Small-4-119B, and remaining competitive with substantially larger first-generation frontier reasoning models such as DeepSeek-R1-0528, Gemini-2.5-Pro and Claude 4.5 Sonnet. With our novel Markovian-RSA test-time compute methodology, we achieve significant additional performance gains — exceeding Claude 4.5 Sonnet and GPT-5-High on HMMT'25 (89.6 vs 88.3) and closing in on frontier open-weight models such as DeepSeek-V3.2 on mathematics benchmarks.
ZAYA1-8B’s performance is a testament to Zyphra’s innovations across the full stack from model architecture, pretraining and optimization, to post-training and large-scale RL. Moreover, its strength demonstrates the power of our post-training stack and we are excited to continue to scale our efforts here both in terms of model size and the breadth and diversity of domains.
ZAYA1-8B is available today as a serverless endpoint on Zyphra Cloud.
Performance
ZAYA1-8B also performs competitively against recent SOTA OS models in the same weight class and against many substantially larger OS models across a wide range of evaluations such as mathematics (AIME and HMMT), coding (LCB), reasoning and knowledge retrieval (GPQA-Diamond) and instruction following (IFEval and IFBench).
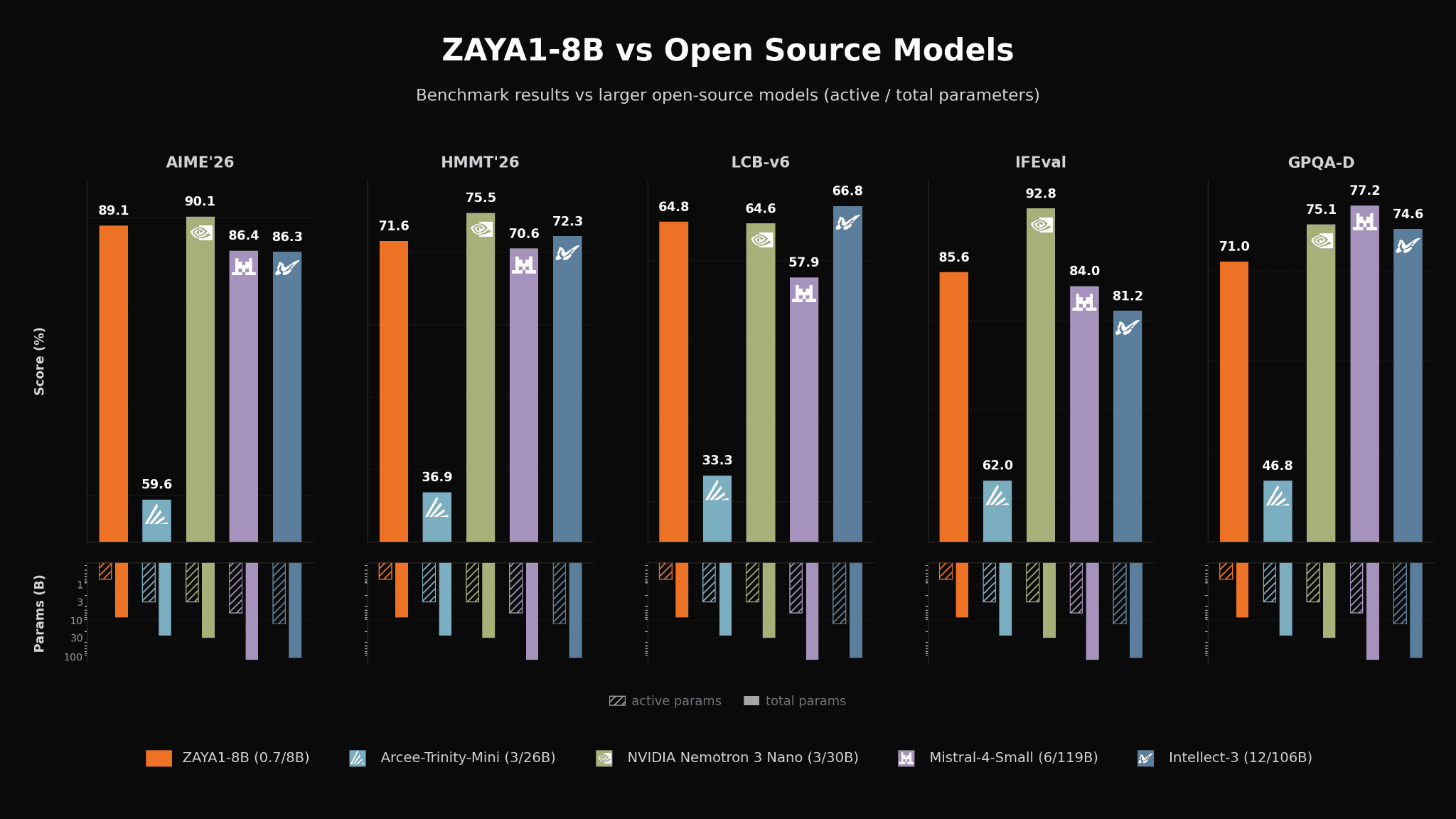
ZAYA1-8B vs leading open-weights models on a variety of evals.
Architecture
ZAYA1-8B achieves its efficiency through a combination of unique architecture, pretraining methodology, and reinforcement learning pipeline, with novel innovations at each level of the stack optimized toward a singular objective – maximize the intelligence extracted per parameter and per FLOP of the final model.
ZAYA1-8B demonstrates three key architectural changes: Compressed Convolutional Attention (CCA), a substantially more efficient and performant attention variant developed by Zyphra; a novel MLP-based router for expert selection that improves routing stability over linear routers; and learned residual scaling, which controls residual-norm growth through depth at negligible parameter and FLOP cost. Together, these form the base of ZAYA1-8B's intelligence efficiency.
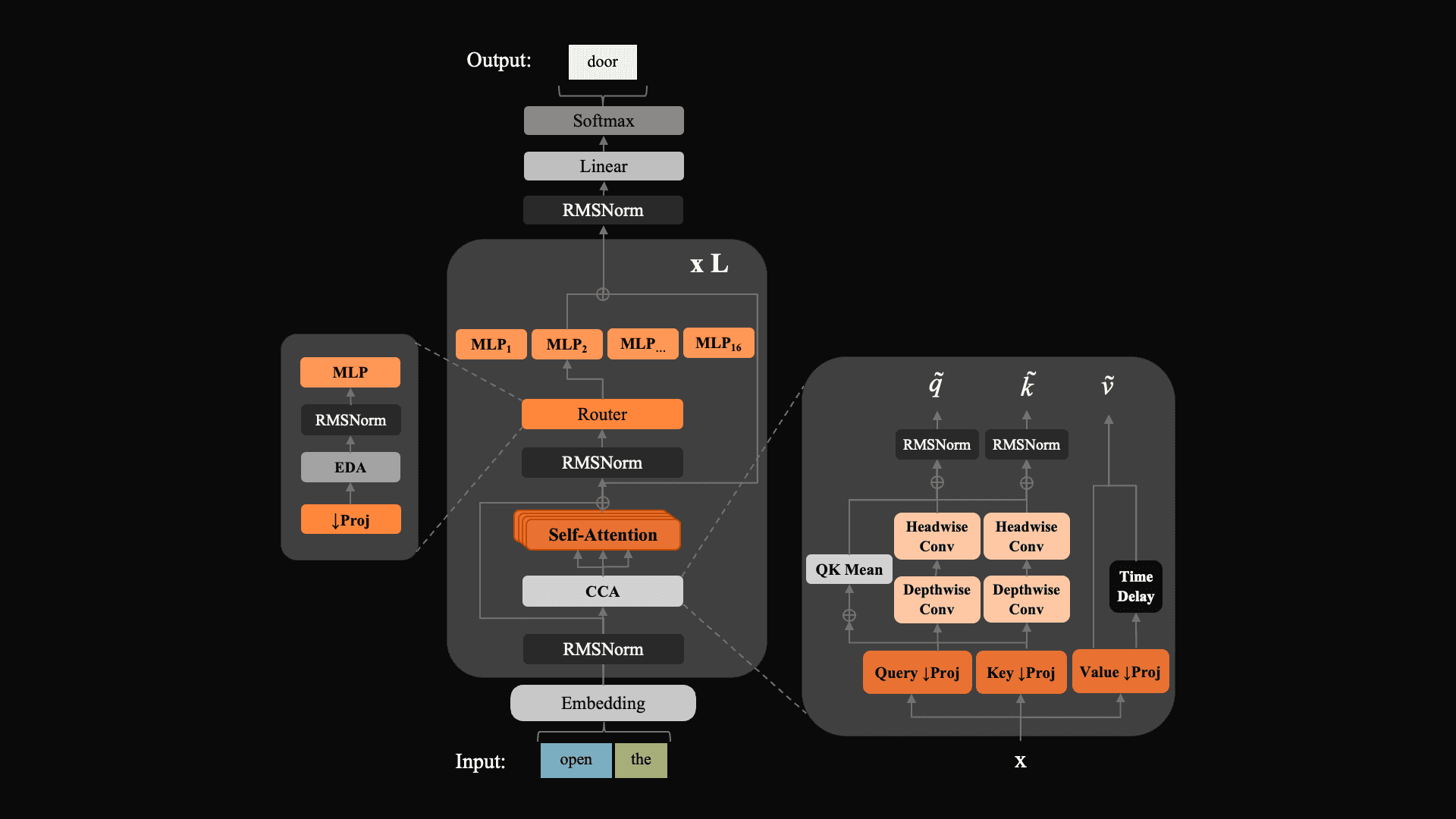
A schematic of the architecture of ZAYA1-8B which combines CCA with our novel router.
Pretraining
Uniquely, ZAYA1-8B was pretrained entirely on AMD hardware and networking using a cluster of 1,024 MI300x nodes with AMD Pensando Pollara interconnect on a custom training cluster built with IBM. Our pretraining and cluster design is described in depth in our previous technical report on ZAYA1-base.
Post-training
Zyphra’s novel large-scale post-training pipeline is also a core component of ZAYA1-8B’s performance. Our pipeline consists of five stages, each focused on sequentially improving the capabilities of ZAYA1-8B. The first SFT stage focused on basic chat, IF, code, math, and TTC abilities. This was followed by a reasoning warmup stage combining mathematical tasks, logic and puzzle solving, with TTC prompts to train the model to natively self-aggregate candidate solutions. This was followed by a large RLVE-Gym phase with dynamically adjusted puzzle-difficulty to train core reasoning circuits. The model then underwent large-scale math and code RL designed to improve its knowledge and reasoning skills in these fundamental domains. Finally, there was a relatively lightweight RLHF/RLAIF phase which focused on improving the model’s chat capabilities and behavior as well as focusing on less verifiable rewards such as instruction following and writing style.
We observe substantial improvements across many capabilities during our RL phase, with improvements especially focused on mathematics, instruction-following, and coding tasks, however we also saw smaller improvements in multiple-choice knowledge retrieval (MMLU and GPQA) and non-verifiable tasks such as creative-writing.
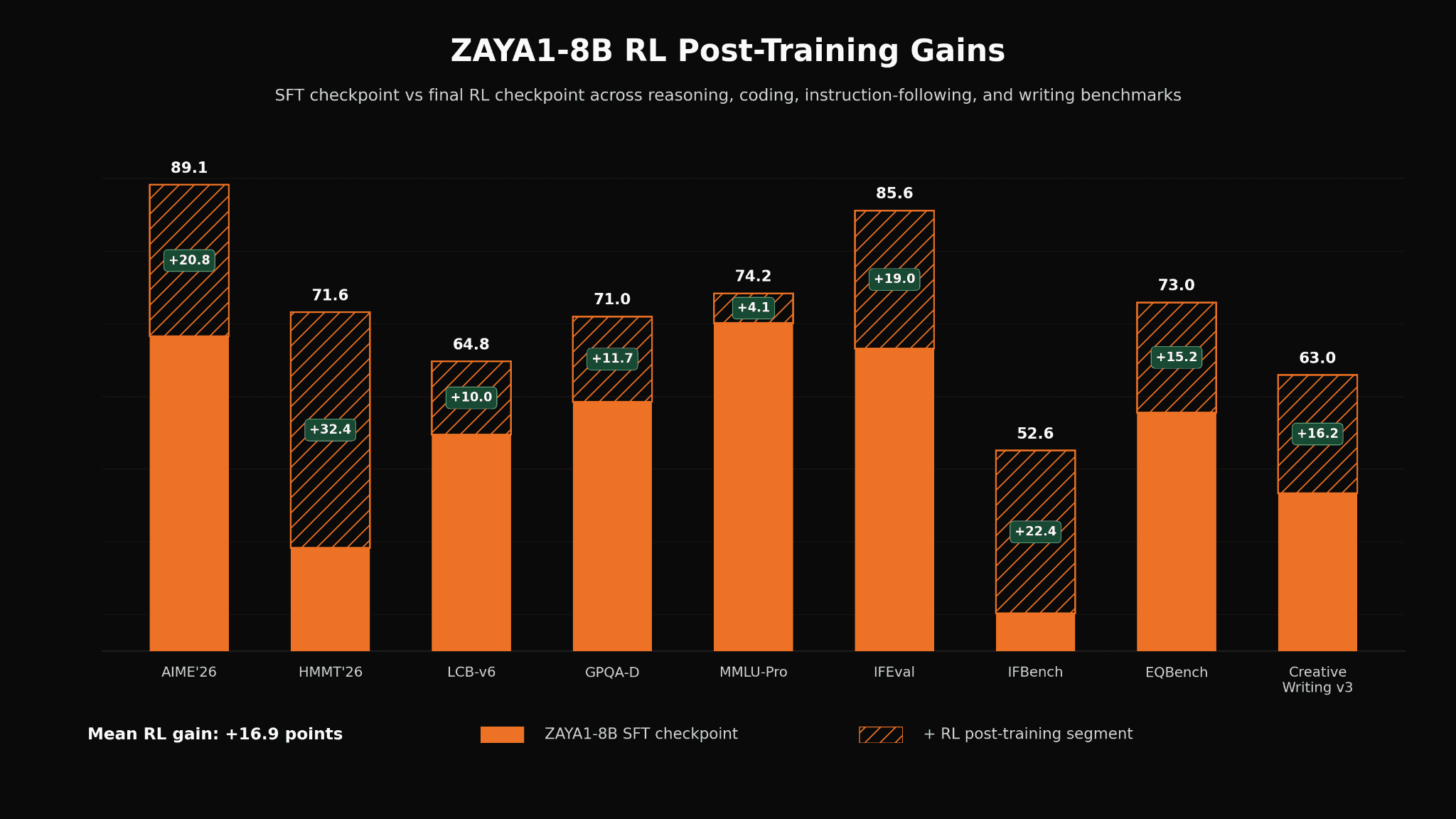
Improvements observed during the RL phase from the SFT checkpoint. We observe most substantial capability boost on mathematics and coding but also obtained smaller boosts on instruction-following and creative writing.
Markovian RSA
Alongside the ZAYA1-8B, we also introduce a novel test-time-compute (TTC) scheme called Markovian RSA that was used to train ZAYA1-8B. Markovian RSA combines the idea of generating multiple traces in parallel then aggregating these recursively from RSA, and the Markovian thinker idea of performing reasoning in chunks of a fixed duration, after which only the tail end of the previous chunk is passed on to the next chunk in the sequence, thus keeping the context window of fixed size despite potentially unlimited reasoning.
With Markovian RSA, we combine these ideas and first, for each prompt, generate multiple traces in parallel, extract fixed-length tail segments from the traces, and then create new aggregation prompts by sub-sampling a few references from the candidate pool. These aggregated prompts are then used as the seed to generate the next round of parallel responses.
As a result Markovian RSA has favorable inference properties – rollout generation can be done in parallel taking advantage of batching, while the Markovian chunking strategy ensures that no matter how long the model reasons for the intermediate chain-of-thoughts, the context length always remains bounded.
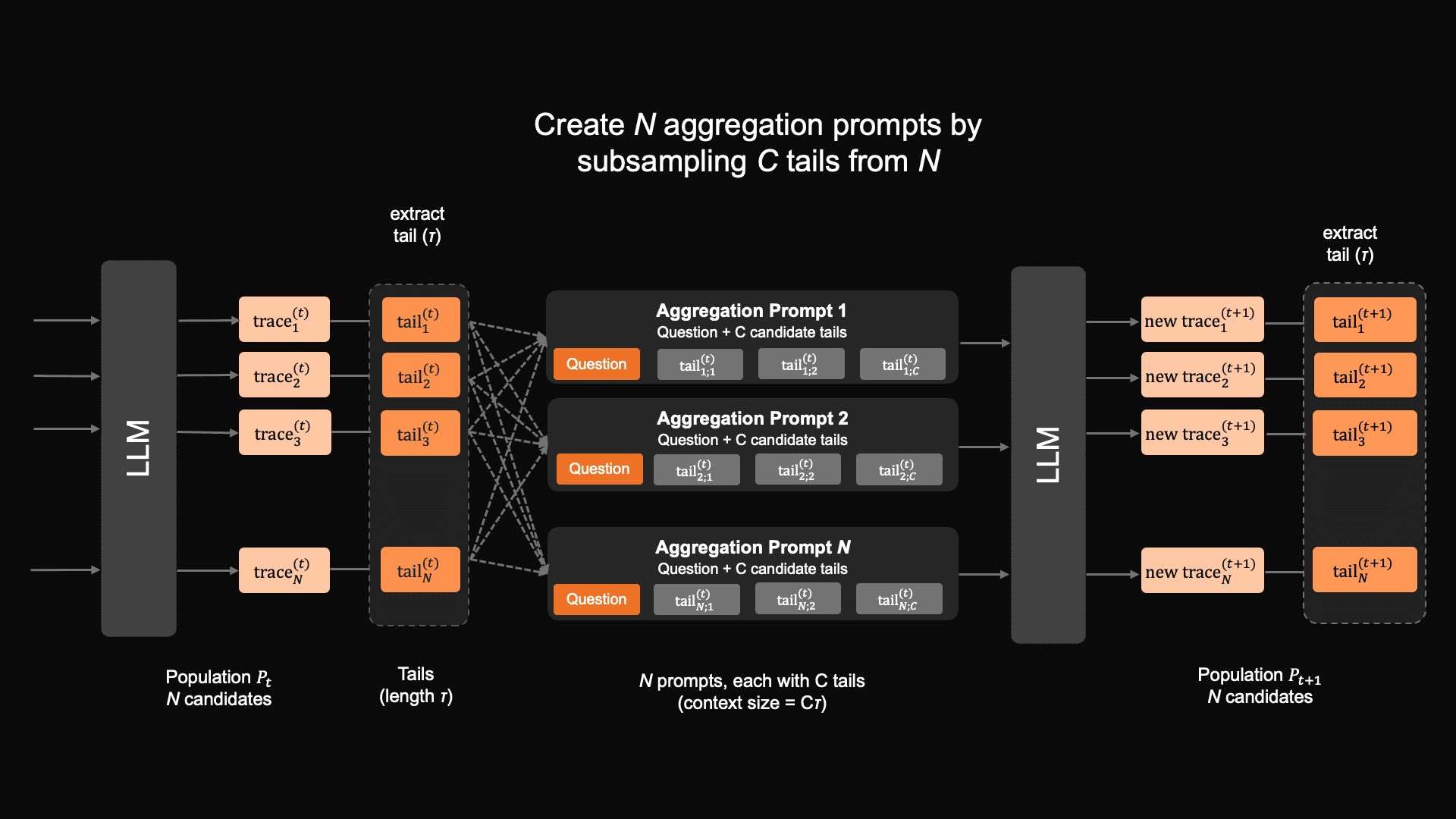
A schematic of the Markovian RSA process
ZAYA1-8B was trained to understand and respond to the Markovian RSA aggregation prompts and chunking methodology starting in SFT, where we synthetically constructed prompts reflecting the desired behaviour and then also during RL where on some portion of prompts trained Markovian RSA self-aggregation behavior. We found that for ZAYA1-8B, Markovian RSA substantially boosts performance, especially on challenging mathematical reasoning tasks.
In the headline figure, we demonstrate that with Markovian RSA on a 40k-token budget for intermediate chain-of-thoughts and with only the last 4K tokens forwarded to the next iteration, that ZAYA1-8B can approach the level of open-weight frontier models such as DeepSeek-V3.2 and Qwen3-A22B, and is only a few points away from GPT-5-High. Furthermore, with a Markovian RSA configuration using extra-high compute, ZAYA1-8B surpasses DeepSeek-V3.2 and GPT OSS 120B (high) in APEX-shortlist.
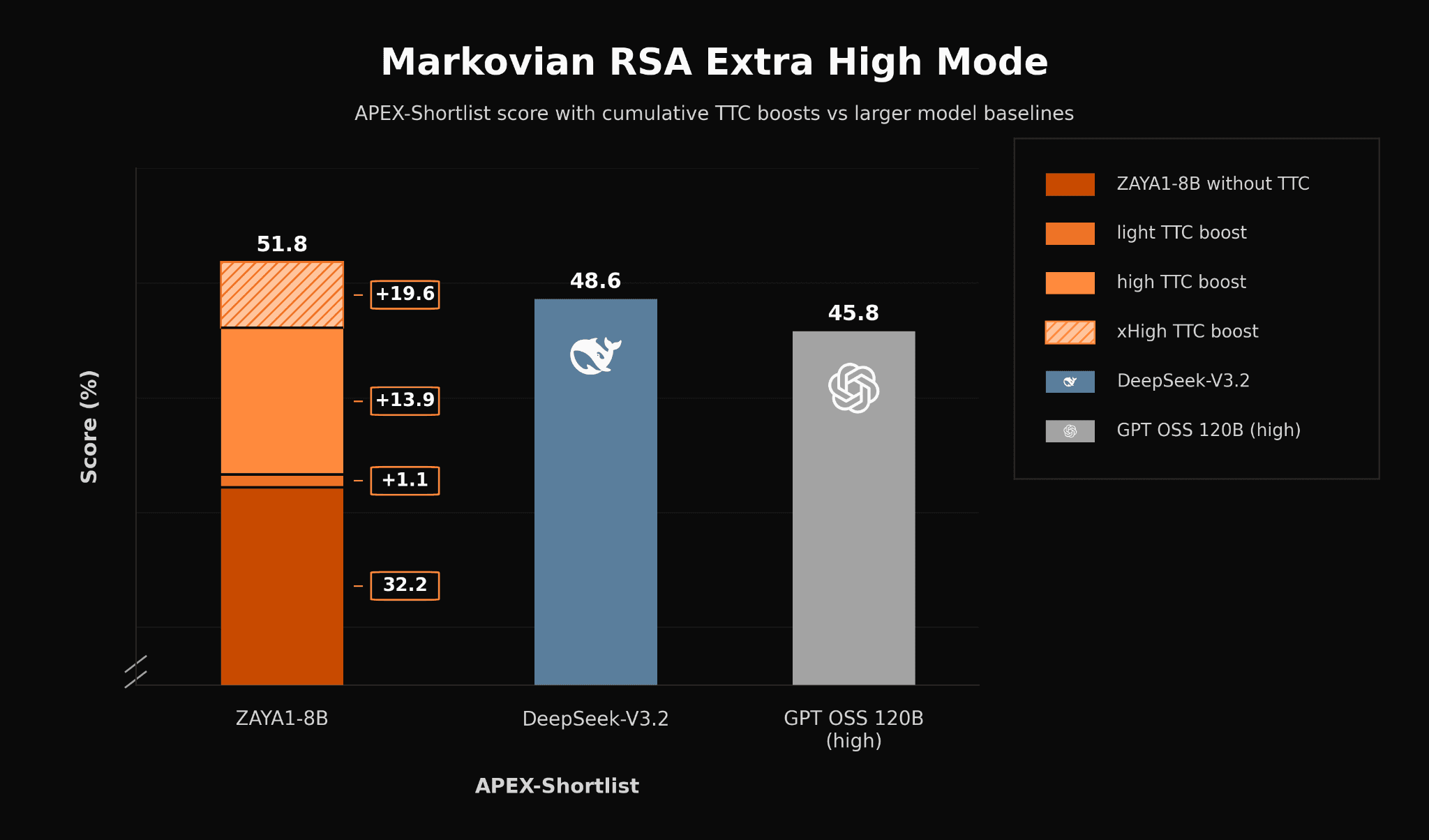
We continue to observe performance gains when scaling test-time compute. With extra-high-TTC (5.5M tokens per problem), ZAYA1-8B outperforms DeepSeek-v3.2 and GPT-OSS-High on the challenging APEX-shortlist mathematics benchmark.
We found that training ZAYA1-8B to understand the Markovian-RSA harness was important to achieving this performance. When we applied the same methodology to Qwen3-4B-Thinking-2507, the performance uplift was substantially less, highlighting the importance of co-design of the eventual model harness and the post-training methodologies.
Conclusion
ZAYA1-8B punches well above its weight class and we are excited for you to try it. It is available to test today Zyphra Cloud or get the model weights from Huggingface.
ZAYA1-8B is released under an Apache-2.0 license.
If you are interested in learning more, there is substantial detail about the architecture, pretraining, and especially our post-training and RL methodologies we used to train ZAYA1-8B in our technical report.