
Model
San Francisco
Zyphra presents ZAYA1-8B-Diffusion-Preview, a preview of our early work in diffusion-language models. We demonstrate that we can convert the existing ZAYA1-8B language model, which was trained autoregressively, into a discrete diffusion model with no systematic loss of evaluation performance. ZAYA1-8B-Diffusion-Preview diffuses blocks of 16 tokens simultaneously resulting in a 4.6x speedup with a lossless sampler and 7.7x speedup with our new logit-mixing sampler. ZAYA1-8B-Diffusion-Preview is the first MoE diffusion model converted from an Autoregressive LLM and the first diffusion-language model trained on AMD.
Introduction
Almost all language models in use today are autoregressive, meaning they decode one token at a time in sequence. For each token, the attention mechanism must look back over all previous tokens and use the results of these prior computations (the KV-cache) to generate a new token. Each user in a batch of requests has a different history of tokens, therefore the KV cache for every user has to be loaded in parallel and cannot be amortized across users like the loading of parameters. This means that in many situations, autoregressive decoding becomes memory-bandwidth bound.
Diffusion removes this bottleneck. In a diffusion model, the model generates multiple ‘drafts’ of N tokens simultaneously and iterates this drafting process multiple times. With diffusion, N tokens can be generated at once as part of a single sequence using the same KV-cache, therefore the entire operation becomes compute-bound (rather than memory-bandwidth bound) resulting in maximum GPU utilization and dramatic speedups over autoregressive inference. Our model is a single-step transformation from mask to token for each token in the block.
Autoregression to Diffusion
Training a diffusion model from scratch is challenging and few known recipes exist. In addition, there is no advantage to training in diffusion-mode since training is already compute-bound.
Instead, we present a method which converts an existing autoregressively-trained base model into a diffusion model rather than requiring training in diffusion-mode from scratch. This enables us to reuse our existing pretraining stack and existing models while gaining the inference-time benefits of diffusion-language modelling.
Building on the TiDAR recipe, we take the ZAYA1-8B-base checkpoint and perform additional diffusion-conversion mid-training of 600B tokens at 32k, then natively context extend to 128k for 500B tokens followed by a diffusion SFT phase.
ZAYA1-8B-Diffusion-Preview is the first MoE diffusion model converted from an autoregressive LLM and the first to be trained on AMD. The ZAYA1-8B architecture with Zyphra’s CCA attention variant makes it well suited for diffusion. CCA dramatically reduces prefill flops in attention. Diffusion converts decoding into prefill, so we gain large decoding speed advantages from CCA since CCA lets us diffuse more tokens in parallel before becoming compute-bound.
We saw minimal evaluation degradation compared to the base autoregressive checkpoint, and saw gains on some benchmarks such as LCB-v6. We attribute this to a combination of improved mid-training datasets since the original ZAYA1-8B midtrain. We could also potentially be seeing gains from the greater expressivity of diffusion-style within-block non-causal inference compared to causal autoregression.
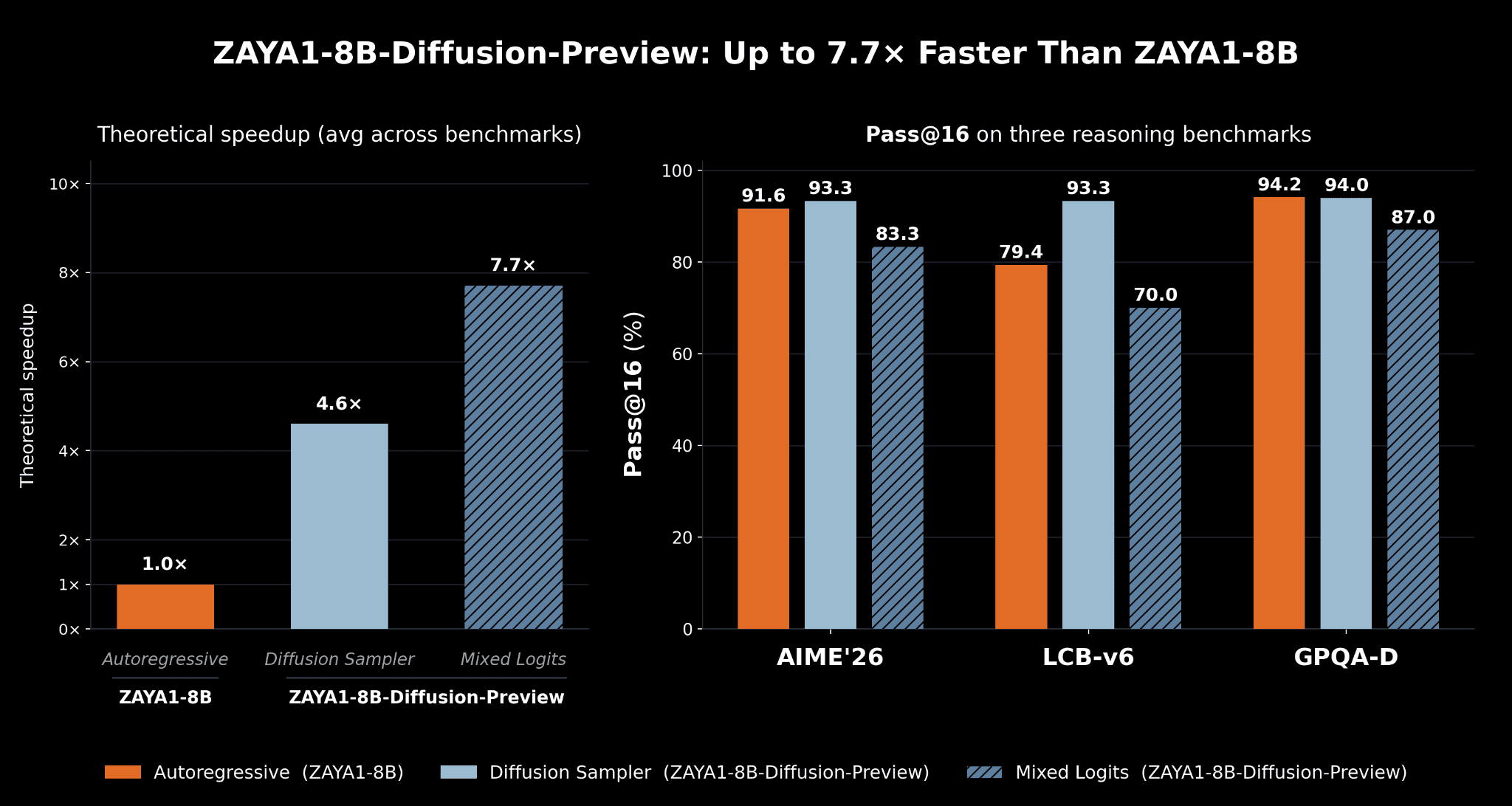
Theoretical speedup vs autoregressive decoding (AR) for the standard diffusion sampler and our mixed-logits sampler. We show that with the lossless standard sampler we do not observe systematic eval degradation (and in fact some improvement) through our diffusion conversion. For our mixed-logit sampler we see some degradation but receive substantial speed gains, thus leading to a trade-off between quality and performance which can be chosen at runtime. Since this is a base mid-train checkpoint, we use pass@ evals to give a better sense of ultimate potential after RL training.
Results
Once the diffusion conversion was complete, we set out to understand the potential gains in inference. ZAYA1-8B-Diffusion-Preview generates a draft of 16 tokens simultaneously during the diffusion phase. Of these, some fraction are ‘accepted’ by a sampling criteria, similar to speculative decoding. The tokens that are ‘accepted’ can then be treated as generated and can be appended to the token sequence for the next round of inference. The advantage of single model speculator and verifier is to allow for speculation in the same forward pass as verification, thus reducing the overhead compared to traditional speculation methods like EAGLE, or dFlash.
In heavily memory-bandwidth-bound regimes, almost all the ‘accepted tokens’ are ‘free’ speedup over autoregression. In practice, attaining such speeds is more challenging because of additional overhead of diffusion and the fact that the inference stack for diffusion models is substantially less optimized than for autoregression. In our experiments, we manage to obtain a 4.6x acceptance rate from the lossless diffusion sampler and a 7.7x acceptance rate from the mixed-logits sampler.
In our results above we presented two samplers. The default diffusion sampler is from speculative decoding and uses acceptance criteria of min(1, p(x)/q(x)), where p is the AR model’s logit distribution and q is the diffusion model’s distribution. Upon rejection, the next token is sampled from the residual distribution of p(x)-q(x).
Our mixed-logit sampler first mixes the logits from the diffusion speculator and the autoregressive mode, then uses the averaged distribution for verification. This improves acceptance since the verification logits are closer to the diffusion logits, but has some impact on quality.
Even in these early stages, we observe the speedup we attain from diffusion is higher than alternative methods such as multi-token prediction (MTP) and various speculative decoding strategies such as EAGLE3. Since TiDAR style diffusion models utilize a single forward pass only, acceptance rates comparable to dFlash still yield substantial speedups.
Architecture
Our diffusion model is a single-step speculative diffusion model. This allows for order constrained generation, where the diffusion model is only capable of generating tokens in a contiguous subsequence starting from the prefix. This increases the training stability dramatically in comparison to unconstrained mask diffusion objectives, or in set block decoding. This stability, as well as the quality of the conversion, led us to build on top of the TiDAR recipe.
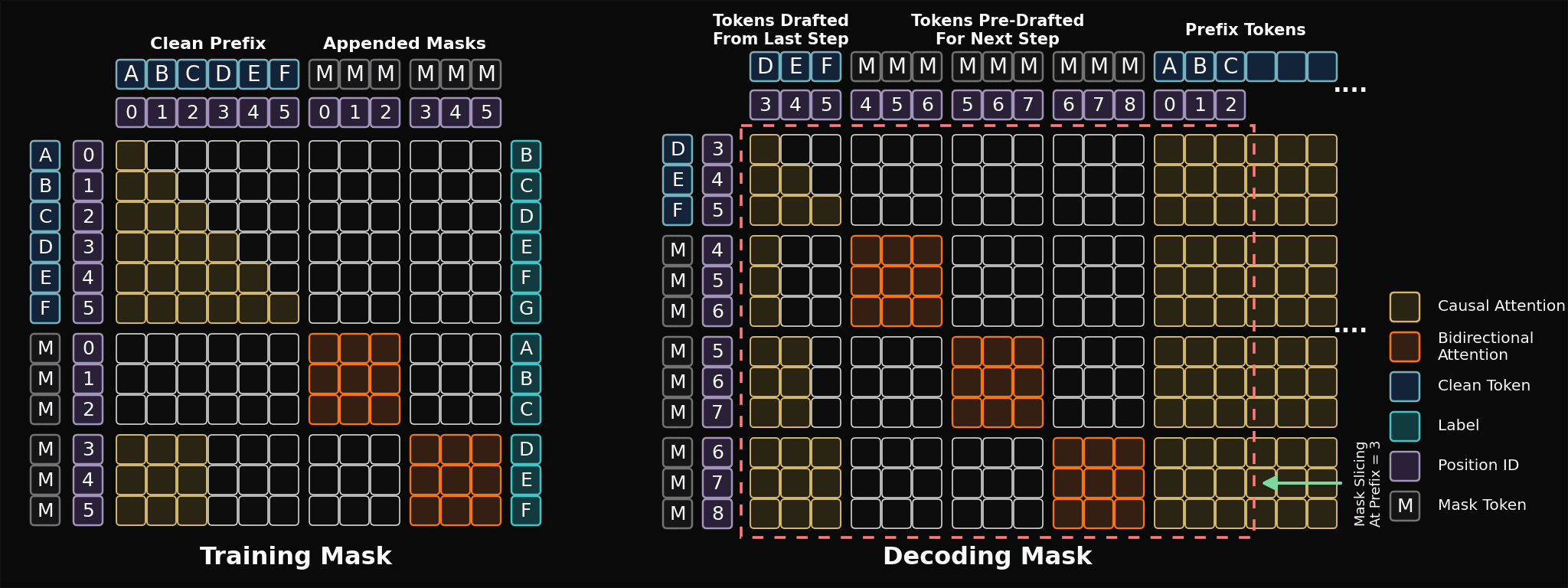
The block-mask and decoding strategy used in ZAYA1-8B-Diffusion-Preview. Figure adapted from TiDAR paper.
We designed our ZAYA1-8B architecture with diffusion in mind. One of the primary reasons we avoided MLA in the past was due to the large arithmetic intensity of MLA compared to CCGQA. With CCGQA in ZAYA1-8B, we have a 4:1 ratio between query heads and key heads, resulting in a memory bandwidth bound attention. Since block diffusion accesses the same cache, the arithmetic intensity scales with the block size, and scales with the number of blocks per forward pass. This allows us to do a single forward pass that verifies a block, while speculating on that block with ~3 block sized proposals on MI300x in bf16, and ~5 block sized proposals on MI355x. As modern GPUs continue to scale FLOPs more than memory bandwidth, we believe diffusion offers an increasingly strong benefit on modern hardware.
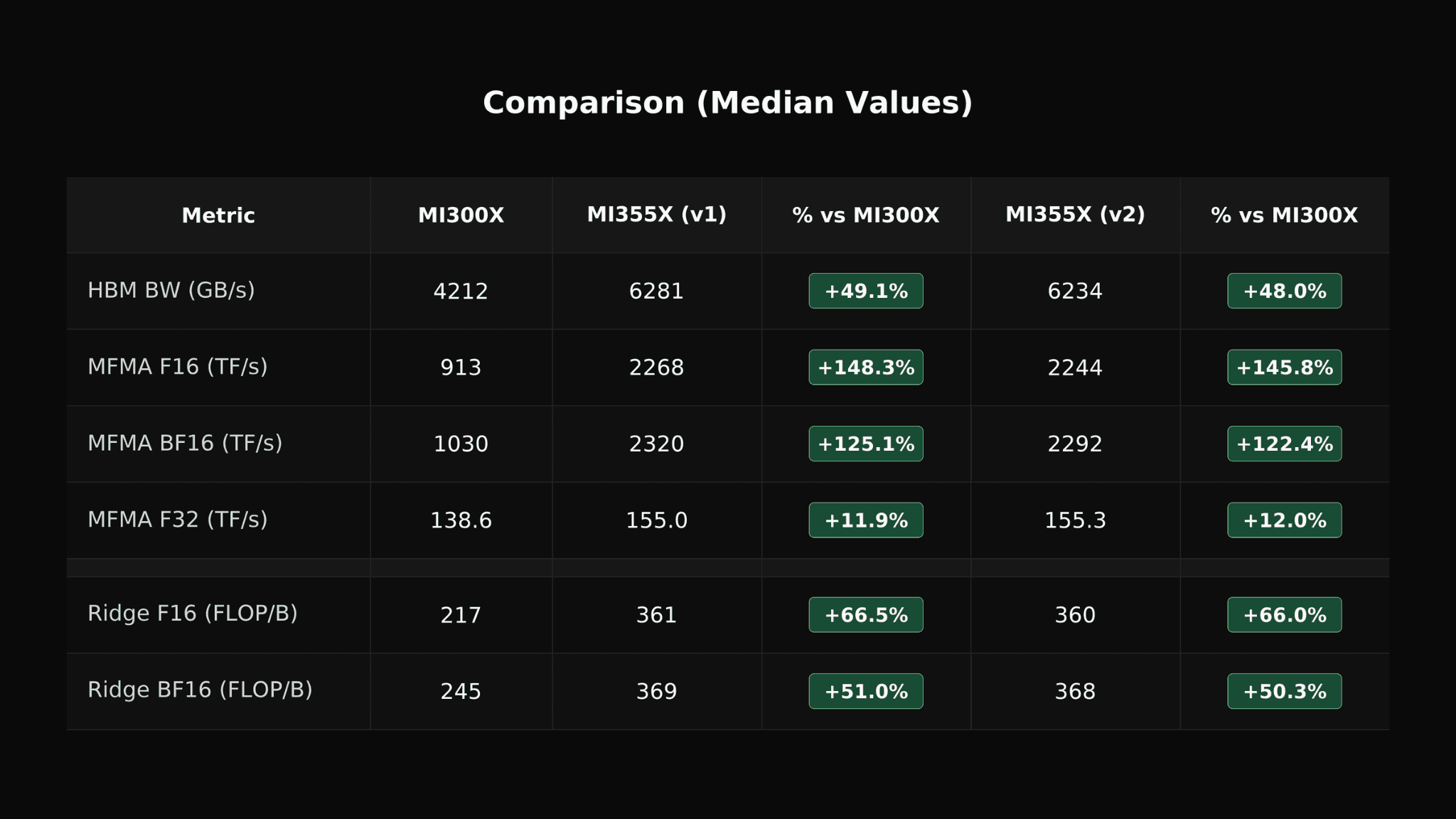
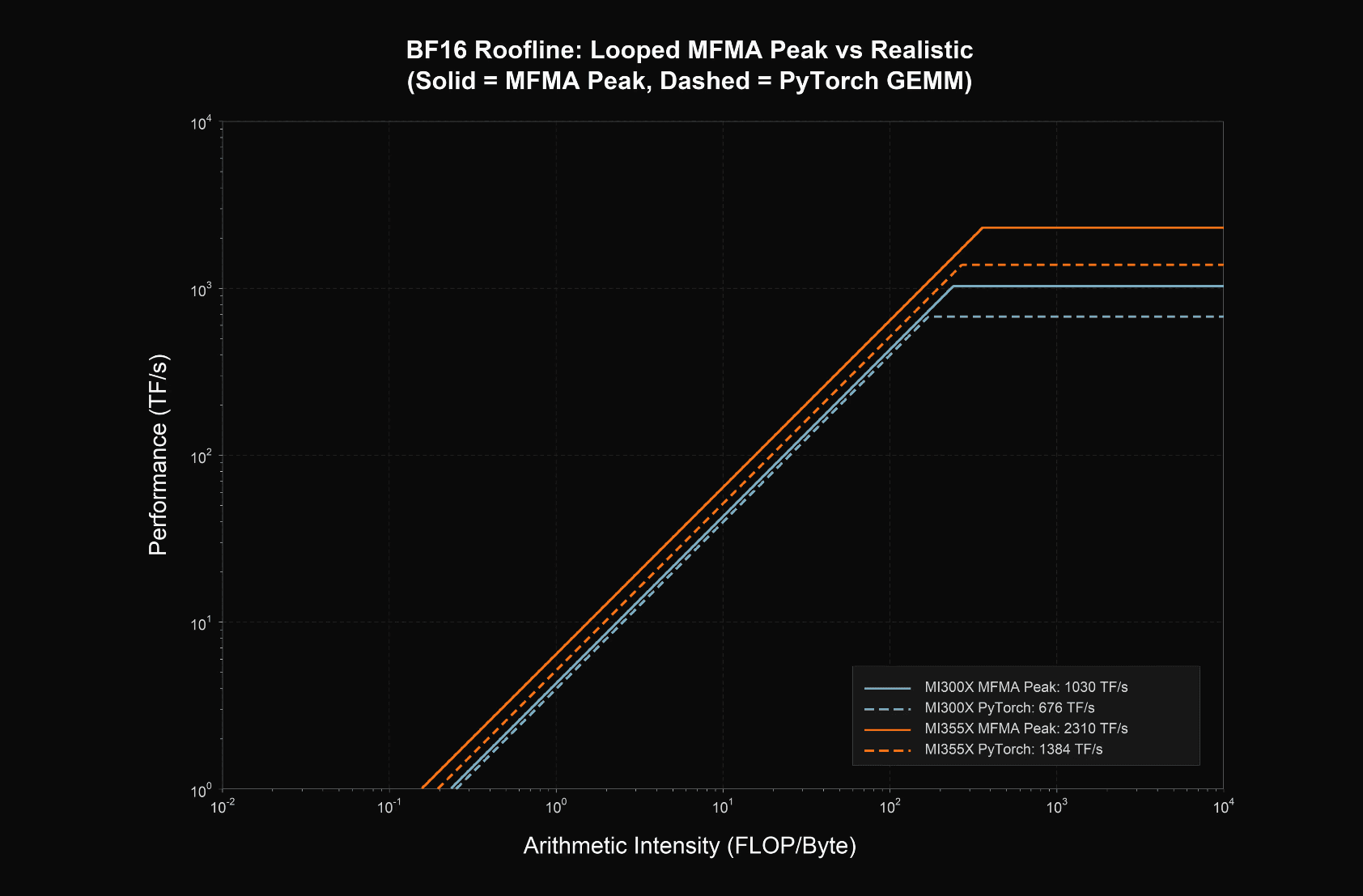
Additionally, CCGQA allowed us to afford the additional training FLOPs in midtraining associated with TiDAR, since we operate with 2x compression. The greater VRAM capacity of AMD GPU hardware enabled substantially more efficient diffusion training.
Overall, diffusion-language models offer concrete advantages in inference speed and rollout cost, as well as enable more expressive modelling than the causal left-to-right order of autoregression permits. Faster and compute-optimal generation also substantially reduces the cost of on-policy rollouts enabling greater RL and test-time-compute scaling than is cost-effective for standard autoregressive models. This is a clear example of our vision regarding end -to -end data, architecture, posttraining and inference codesign.