
Model
San Francisco, California
Zyphra releases ZAYA1-VL-8B, a vision-language model building on the ZAYA1-8B-base. ZAYA1-VL-8B is an MoE model with 700M active and 8B total parameters. ZAYA1-VL-8B excels at visual understanding, grounding, and OCR-type tasks. The model is released under an Apache 2.0 license and the weights are available here.
Hassan Shapourian, Kasra Hejazi, Olabode M. Sule, Beren Millidge
Introduction
Zyphra releases ZAYA1-VL-8B, our first vision-language model. ZAYA1-VL-8B marks Zyphra's first step into vision and the foundation of our multimodal roadmap. ZAYA1-VL-8B builds upon Zyphra’s ZAYA1-8B LLM which was pretrained end-to-end on AMD. ZAYA1-VL-8B delivers unparalleled performance for its size, and thus leads in flop-efficiency and intelligence density.
ZAYA1-VL-8B performs strongly against models of comparable size, outperforming competitors such as Deepseek-VL2, Qwen3-VL, and MolmoE. This is despite being trained on far fewer tokens than competing models, which are typically trained on trillions of vision–language tokens, compared to roughly 140B tokens for ZAYA1-VL-8B.
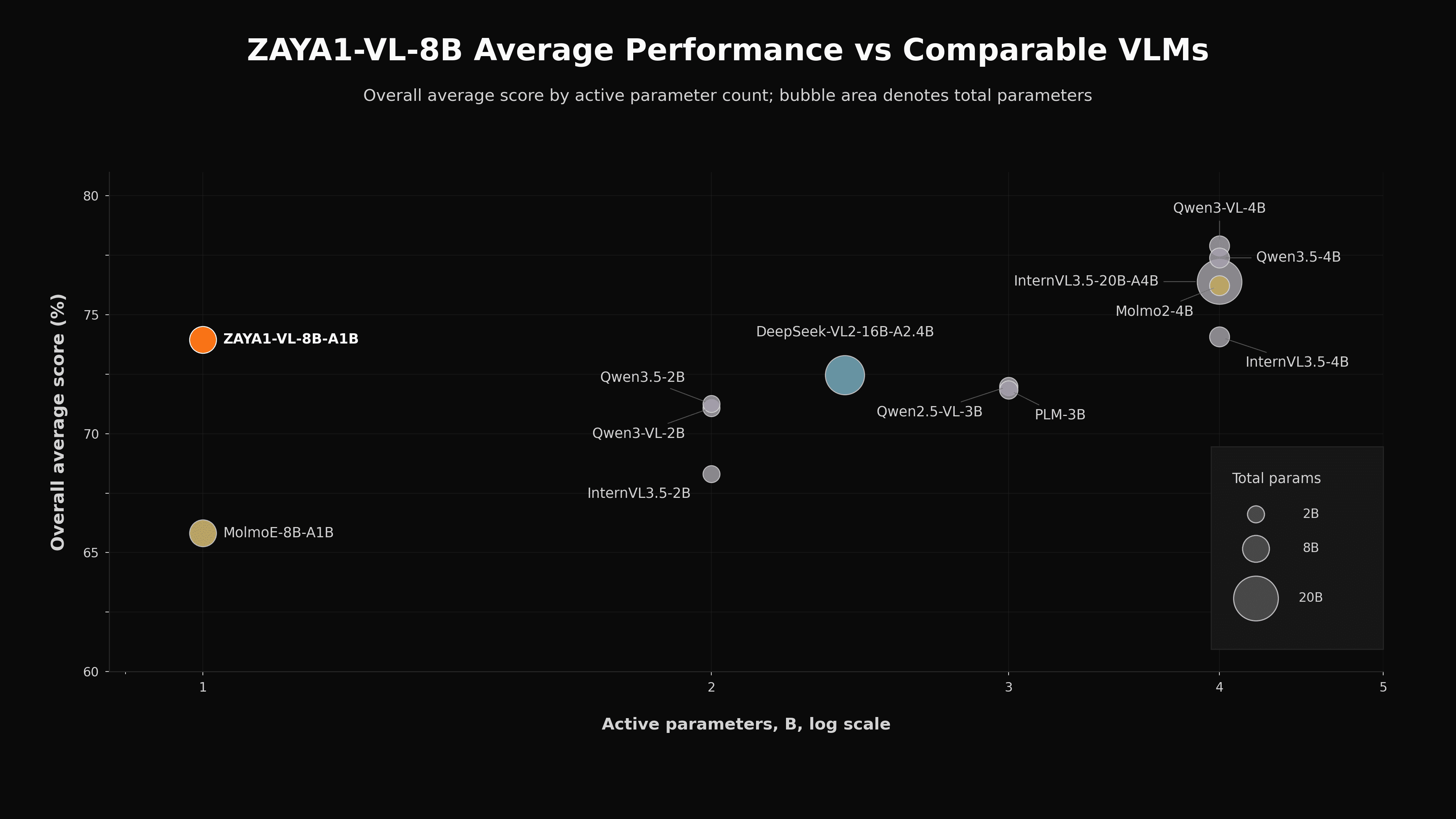
Performance of ZAYA1-VL-8B vs comparable models based on active parameters (inference-efficiency). Aggregate score is reported here. For full breakdown by eval please see the technical report.
Architecture
ZAYA1-VL-8B achieves its efficiency through novel architectural innovations to better integrate and process visual information in the LLM. Specifically, we make two fundamental architectural innovations that each address a core mismatch between vision and language. Firstly, images do not have a natural left-to-right causal order, yet standard VLMs process visual tokens with the same causal attention used for text. Secondly, images carry modality-specific structure and knowledge that is distinct from textual knowledge, yet most VLMs force all processing through identical parameters. To address these issues, we introduce:
Vision-specific LoRA parameters: ZAYA1-VL-8B utilizes specialized LoRA parameters on its MLPs and CCA weights which are only activated on vision tokens. We find that adding vision-specific parameters substantially improves model performance since the model has the option to devote specific parameters solely to visual processing. We train these LoRA parameters alongside the main model parameters during training. This is a lightweight yet effective modification during both training and inference.
Bidirectional Attention for image tokens: ZAYA1-VL-8B processes all image token inputs with a bidirectional attention mask, meaning attention is not causal across an image. We find that this improves performance by not imposing an arbitrary causal order to image tokens which are naturally non-causal.
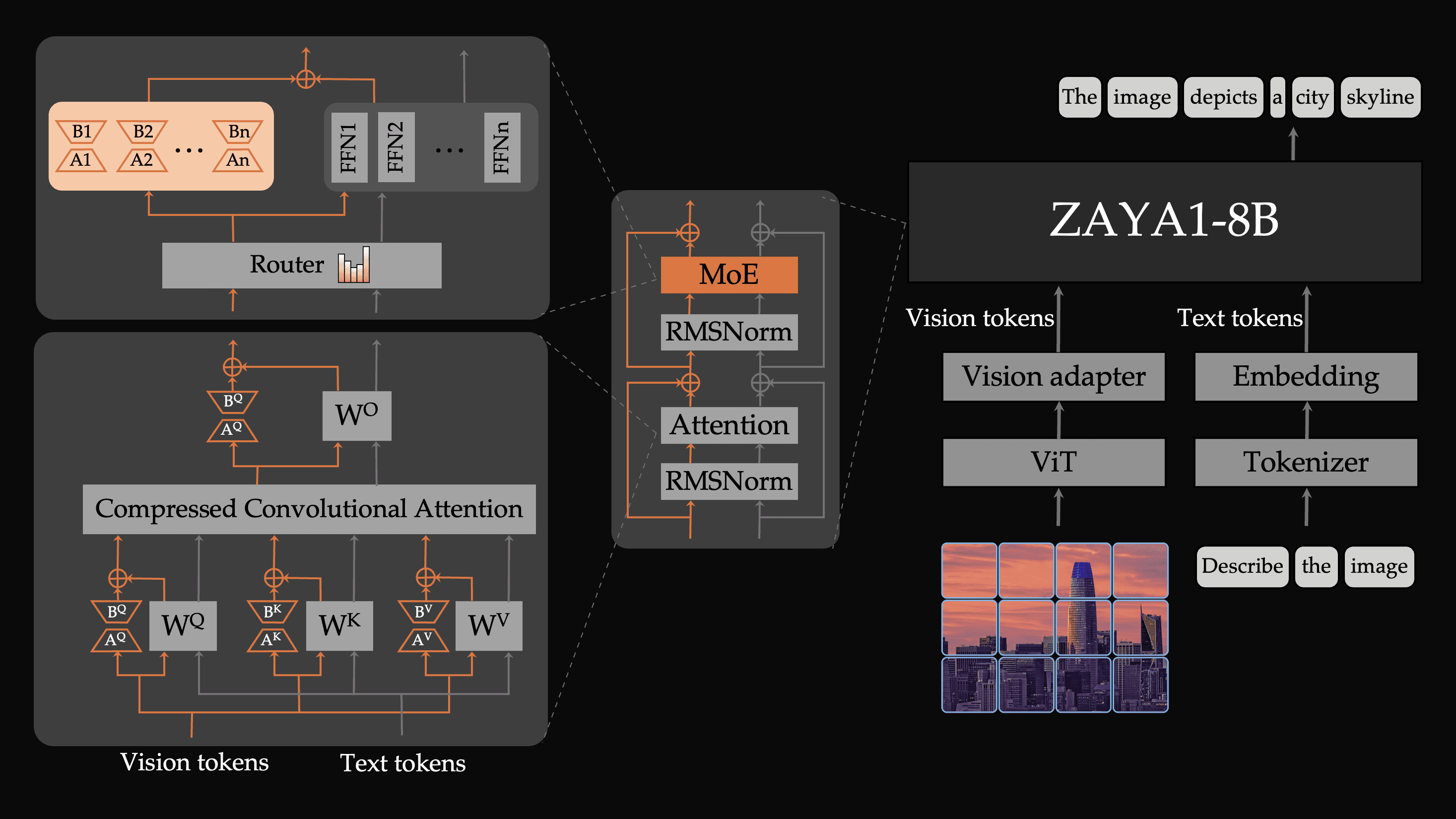
Schematic of the architecture of ZAYA1-VL-8B. The two core changes we made to the standard VLM recipe are bidirectional attention for image tokens and vision-specific LoRA parameters on the expert MLPs and CCA attention weights.
Despite the growing success of MoE architectures in large-scale language modeling, there remain surprisingly few compact MoE-based VLMs. We believe this is in part due to training challenges of MoEs that are amplified in the VLM setting. First, for VLM training, since we only train on language-answer tokens and not vision tokens, the effective batch size can become extremely small. This is compounded by MoEs splitting a batch across many experts. We find that to train stably we need to use substantially larger batch sizes than is normal to compensate for this.
Secondly, the sudden domain shift from language-only to language-vision substantially alters routing patterns in the MoE which can cause dramatic instability or degradation of the model’s language capabilities. We address this architecturally by introducing vision-specific LoRA parameters which are only activated on vision tokens. This gives the model an extra bank of capacity it can use for vision which can buffer some of the domain shift caused by introducing vision tokens.
Examples
ZAYA1-VL-8B performs especially strongly at:
Document understanding and OCR
Spatial perception and grounding
GUI and Computer use tasks
To give a sense of ZAYA1-VL-8B’s capabilities in these areas, we present below a series of example images, prompts, and the model’s responses











































Conclusion
We are releasing ZAYA1-VL-8B as a research preview for the open community. Our goal is for ZAYA1-VL-8B to be useful both as a capable base model and as a concrete research artifact. In future work we will develop our post-training reasoning stack for vision and continue to scale both in model and dataset sizes.
ZAYA1-VL-8B is released under a permissive open-source Apache 2.0 license. The model weights and model card can be found here.
For more details please see our technical report.