
Research
San Francisco, California
Building on our launch of Zyphra Cloud, today we publish the first end-to-end benchmarks for Zyphra Inference on AMD Instinct™ MI355X GPUs. We show inference metrics achieved on a single node of MI355X GPUs on our cloud for Kimi K2.6, GLM-5.1 and DeepSeek V3.2 compared to the baseline AMD MI355X and Nvidia B200 inference configurations. These results reflect the first phase of our broader full-stack inference optimization effort across kernels, parallelism, communication, quantization, and speculative decoding.
Methodology and Limitations
Showing fair inference metrics is difficult, especially fair comparisons across hardware and software platforms. We wish to clearly describe our methodology, present our initial findings, and show where we can make the most impact for our customers with our hardware. Some specific limitations in our work:
All results are taken on a single node and with no live traffic, meaning requests arrive at fixed intervals instead of randomly, and scheduling is not tested in real settings.
The performance of speculative decoding methods tends to be sensitive to the dataset used in the benchmark. This is because draft model acceptance rates can vary substantially across input distributions. This effect is less pronounced for speculative decoding methods like EAGLE because the draft model is trained on the target model's hidden states rather than as an independent language model. Therefore, the EAGLE speculator’s acceptance tracks the verifier's distribution rather than its own pretraining distribution. To further reduce this source of variability, we use the same input prompts across models so that KV and prefix cache behavior is as similar as possible. For these tests, we use ShareGPT and LMSYS-Chat-1M.
There are stochastic effects in open-source inference stacks such as KV cache corruption and race conditions, which can affect performance and can be difficult to detect or reproduce.
Both our inference software stack and those of the external baselines are rapidly progressing so any results we show here are only valid for a point-in-time. We also limit our investigations to vLLM to avoid framework comparisons, but warn that models can have different performance metrics across inference frameworks.
Introduction
LLM inference runs in two phases. A prefill phase processes the entire input prompt in parallel, then a decoding phase emits output tokens one at a time autoregressively, each conditioned on every previous token. Two families of metrics capture performance across these phases. Time-to-first-token (TTFT) is the latency from request arrival to the first generated token. The first token is emitted from the final step of prefill, so TTFT is essentially prefill cost plus small contributions from request scheduling and prompt tokenization. TTFT is the most user-visible component of perceived responsiveness on interactive workloads. Output throughput measures the token-generation rate after prefill, and we report it in two ways. The first is per-request output tokens-per-second at concurrency c=1, which characterizes single-request speed. The second is aggregate output tokens-per-second across c concurrent requests, which characterizes how much traffic a node can sustain.
The B200 and MI355X GPUs have hardware properties that greatly affect inference performance.
Memory capacity: Each MI355X provides 288 GB of HBM3E, compared to the B200's 180 GB HBM3E. Greater HBM capacity per GPU enables more resident KV and prefix caches, longer per-replica context windows, and less parallelism required to hold a model replica in VRAM. In general, this means the MI355X can serve larger models at longer contexts for more users than the B200, all else equal.
HBM bandwidth: Both platforms deliver roughly 8 TB/s per GPU. Therefore single-request decode, which is typically the most bandwidth-bound operation in LLM inference, is comparable between the two chips.
Intra-node fabric: B200 connects GPUs through a switched NVLink fabric where each GPU's links terminate at NVSwitches rather than at peer GPUs directly. Any communication operation can achieve full 900 GB/s bidirectional bandwidth regardless of the number of participating ranks. MI355X connects GPUs through a fully-connected point-to-point Infinity Fabric, where each GPU has direct xGMI links to all seven peers. Effective per-GPU bandwidth therefore scales with participation: a 2-GPU pairing uses one link's worth of bandwidth, while an 8-way collective engages all seven xGMI links per GPU and reaches the peak 537.6 GB/s bandwidth. This poses challenging but surmountable implementation challenges, namely reformulating communication operations as full-participation collectives (e.g. replace Ring Attention on AMD with Zyphra Tree Attention), as well as aggressive overlap of communication with computation. Large models such as Kimi K2.6, GLM 5.1, and DeepSeek-V3.2 are large enough to require model parallelism across multiple GPUs to ensure sufficient serving headroom and low latencies, so the intra-node fabric affects all inference metrics significantly.
Low-precision compute: Both GPUs expose MXFP4, MXFP6, and MXFP8 in hardware. B200 GPUs additionally expose NVFP4, which provides smaller block size and FP8 scale. While these settings determine what quantization configurations are possible, we don’t evaluate non-default model quantization schemes in this work, but will in subsequent engineering blogs. Quantization reduces both the VRAM required to store the model weights as well as the memory bandwidth to stream weights and KV cache, resulting in substantial performance boosts.
Optimizations
Our inference stack comprises numerous optimizations and techniques we have developed to improve performance and lower TCO. These include:
Tuning: We perform tuning of the core generalized matrix multiplication (GEMM) kernels, in addition to non-GEMM kernel tuning to ensure we use the best-performing kernels for each model that we host and on all possible input sizes. Specifically, we perform offline tuning for every GEMM in every model against each available kernel library, and select the optimal kernels for the shape incurred at deployment time. Tuning is not exclusive to kernels, and every layer of the inference software stack should be tuned, including HIP graph shapes and RCCL communication library tuning. Each library’s tuning settings affect other layers of the software stack, so tuning all layers together is a challenging search problem in and of itself.
Novel Parallelism and Communication Schemes: Zyphra Research has developed novel parallelism and communication schemes such as Tensor-Sequence Parallelism (TSP) and Tree Attention. For Tree Attention, AMD's intra-node fabric is point-to-point rather than switched, and therefore favors collective operations with participation from all ranks on the node. Tree Attention reorganizes long-context attention's communication around a balanced tree-reduction instead of point-to-point operations in a ring as used by standard Ring Attention. TSP folds the tensor and sequence-parallel axes onto a single device axis so the entire model-parallel group stays inside high-bandwidth intra-node links instead of spilling across the slower inter-node fabric or forcing one to decide between parallelizing along weights or sequence in isolation. In both cases, communication must be fully overlapped with the surrounding computation in the style of FLUX or Comet, so that collective latency is hidden rather than affecting user-facing metrics. This is especially impactful in decode, where there is very little compute to overlap the communication. Additionally this greatly affects long-context prefill, where attention collectives could dominate if not overlapped.
Speculative Decoding: We rigorously choose speculative decoding methods that are tuned for ROCm. We pair each model with a draft model and verifier path tuned for the MI355X's inference characteristics at each context length and batch size.
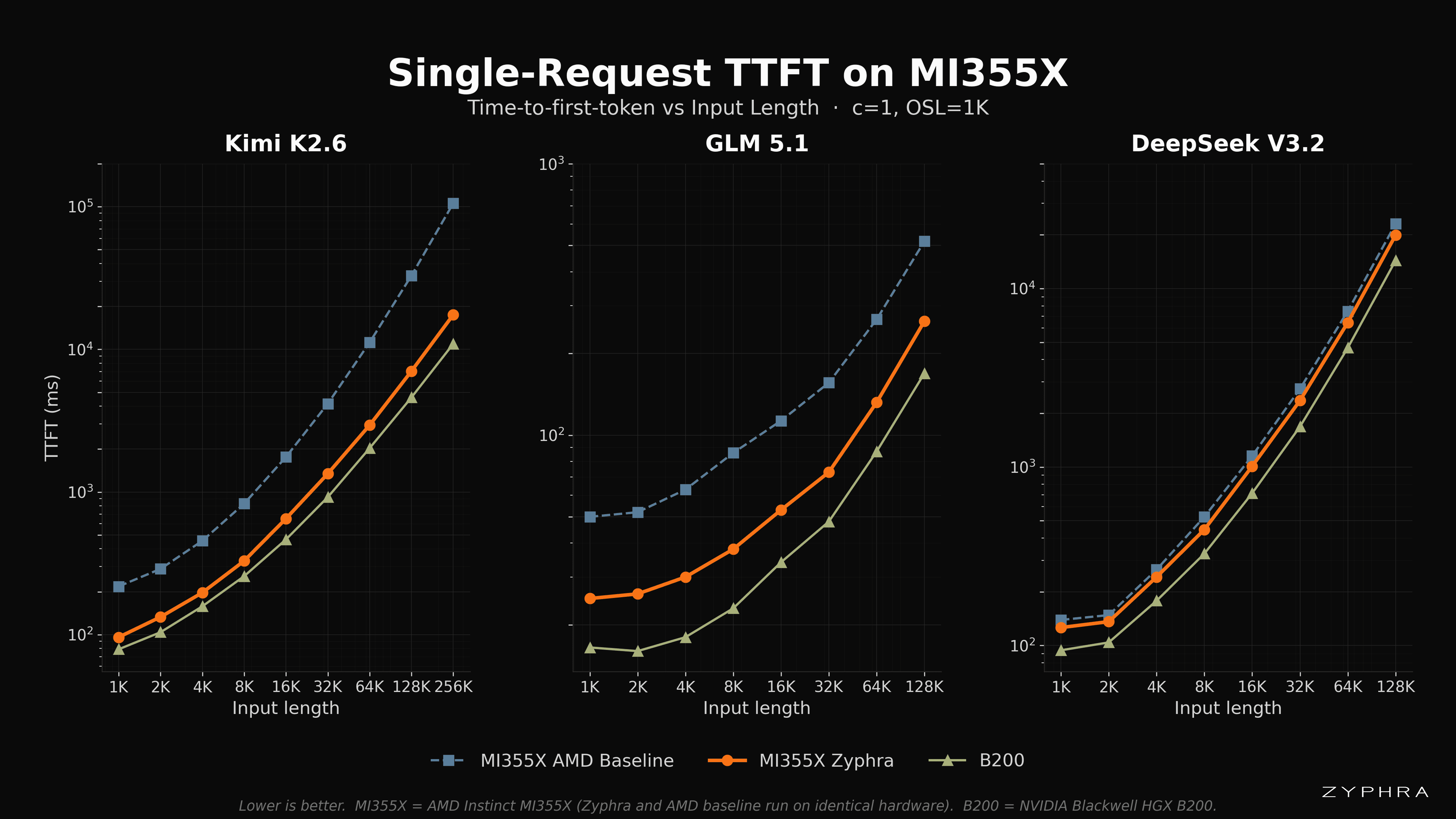
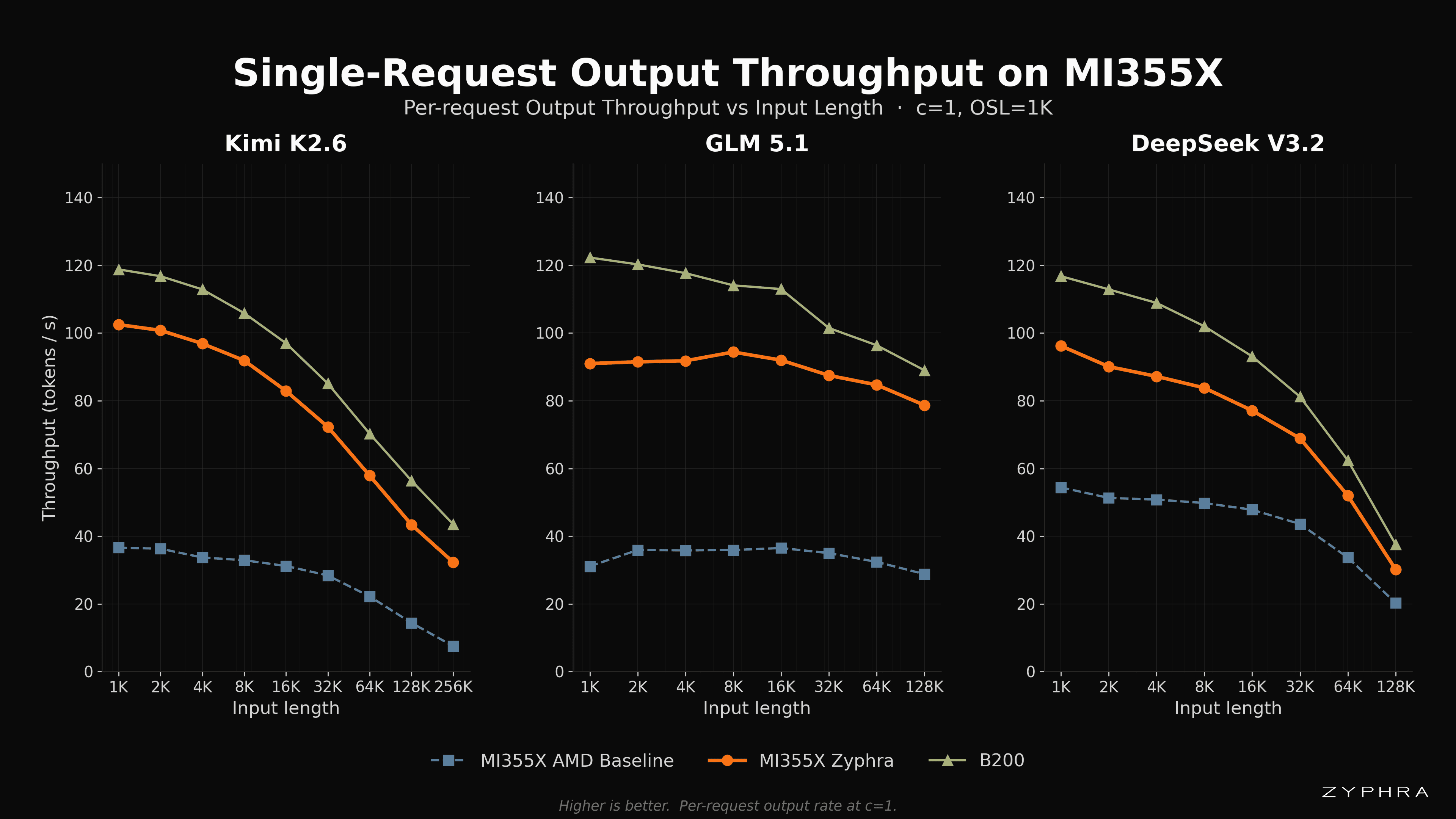
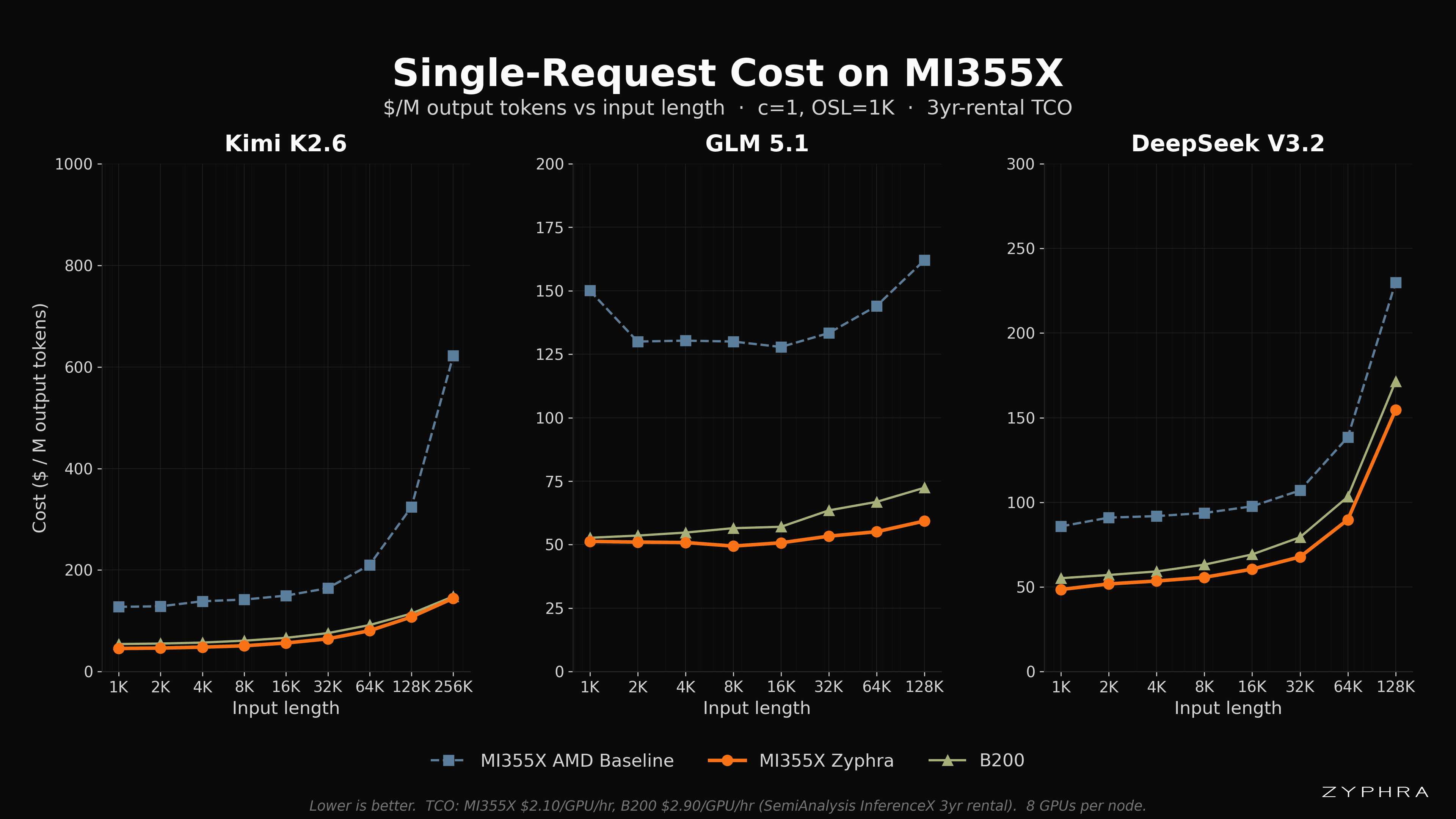
Single-Request Results
While we try to batch as much as possible, there will inevitably be single-request events. Further, single-request runs avoid scheduling overhead noise and provide a cleaner measurement of the model’s performance characteristics. There are a few trends to point out in our results:
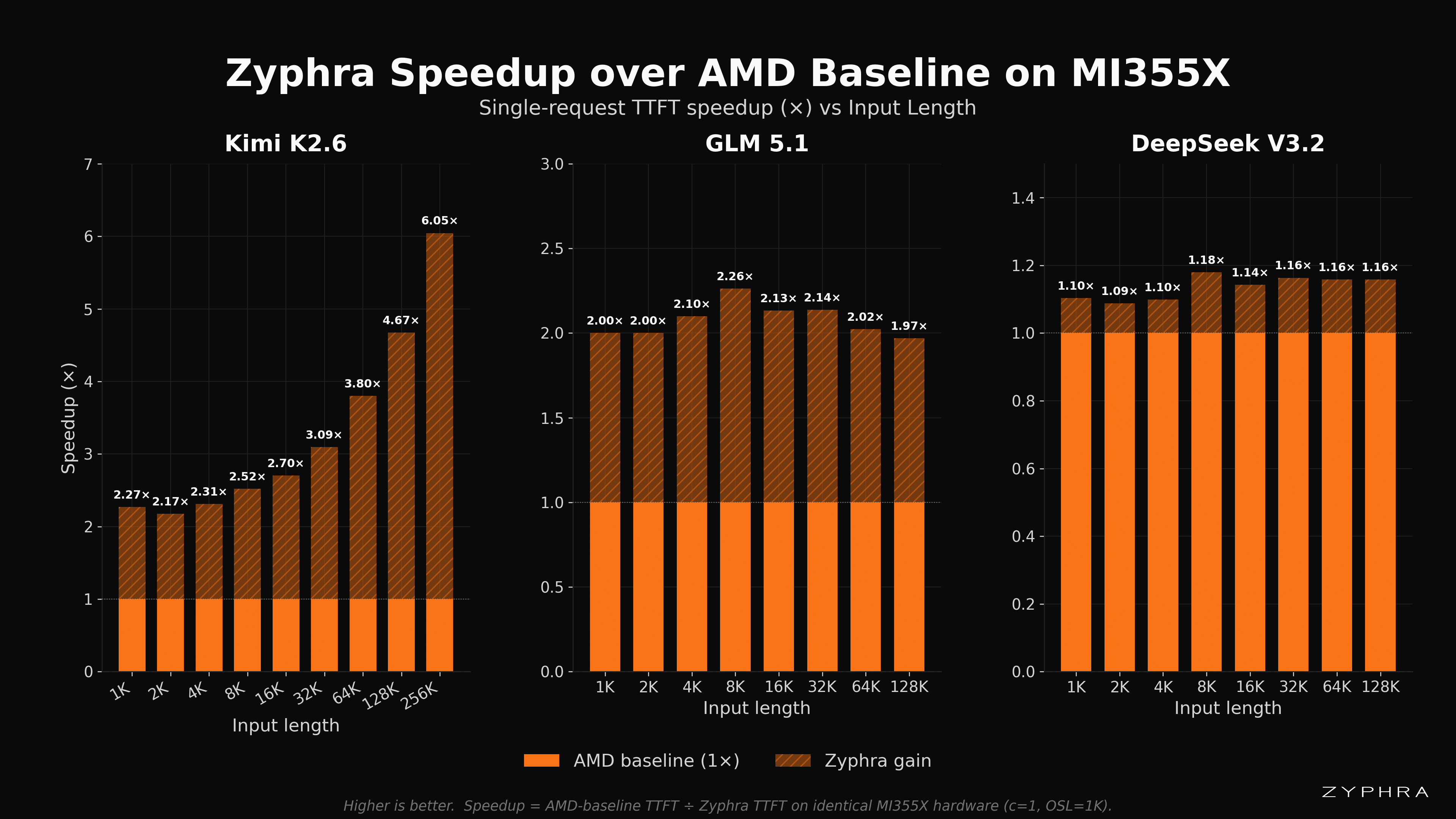
DeepSeek-V3.2 is a more established and popular model, and its performance spread is more narrow since all teams have had significantly more time to optimize for it. Despite this, there was still room for optimization, and we achieved nontrivial speedup with our optimizations.
B200 outperforms both our inference stack and AMD baselines for the time being across all models. We see there are tradeoffs across all three solutions with the primary tradeoff for the B200 being cost. See Pricing section below for specifics on these tradeoffs.
As the context length grows, the throughput of Zyphra’s inference stack approaches B200. This is due to parallelism becoming more important at longer contexts, and demonstrates where Zyphra’s TSP, tree attention, and communication overlap methods have more of an impact.
Zyphra’s speedup over the AMD baseline demonstrates two points. First, the AMD baselines serve as a solid foundation upon which we are able to perform optimization work. AMD’s transparency and willingness to collaborate with Zyphra enables the ecosystem to produce better solutions for customers on AMD silicon. Second, it shows that Zyphra’s experience in large-scale training within the AMD ecosystem translates to our ability to rapidly iterate on inference optimizations that provide meaningful speedup to our customers.
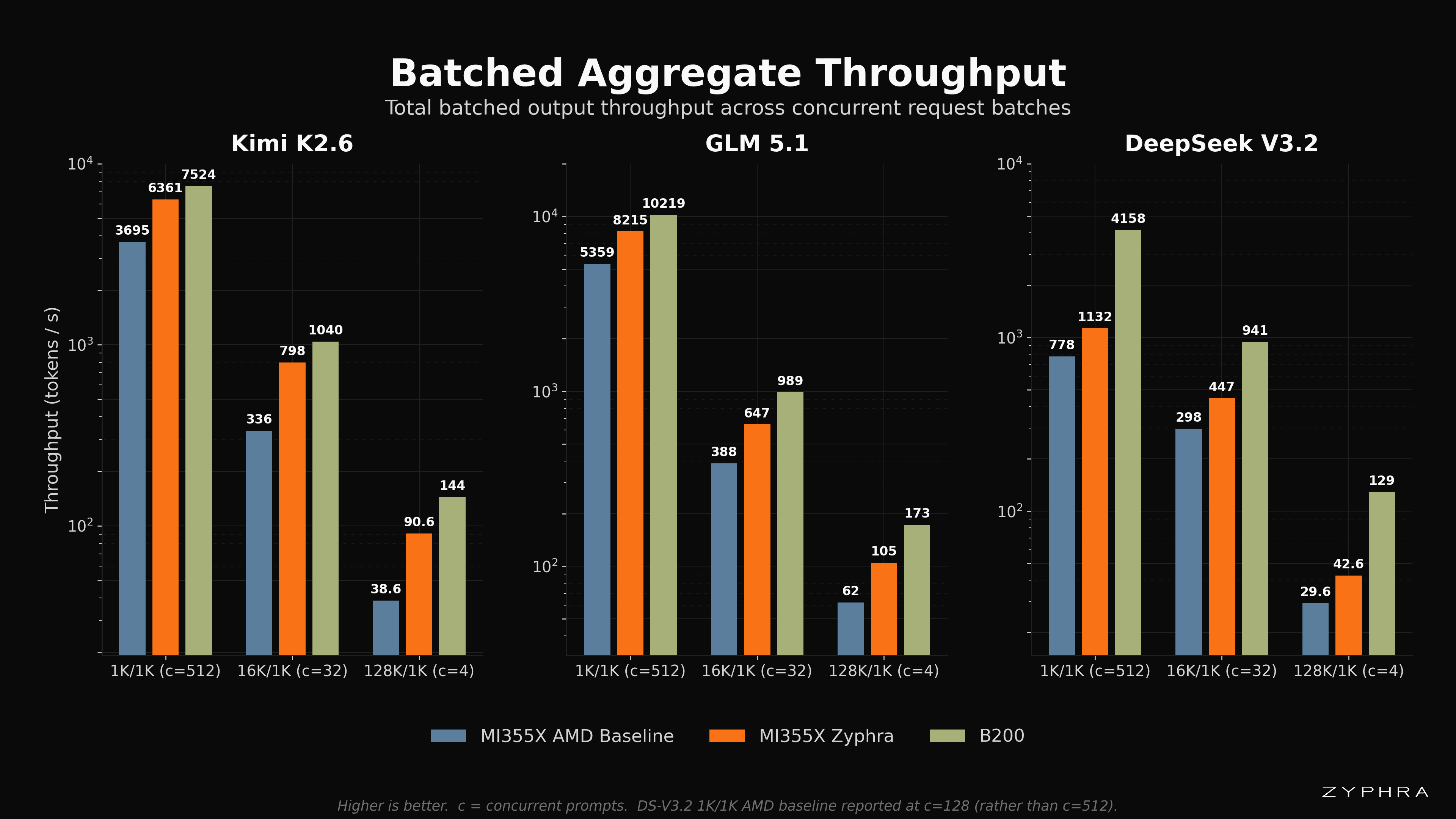
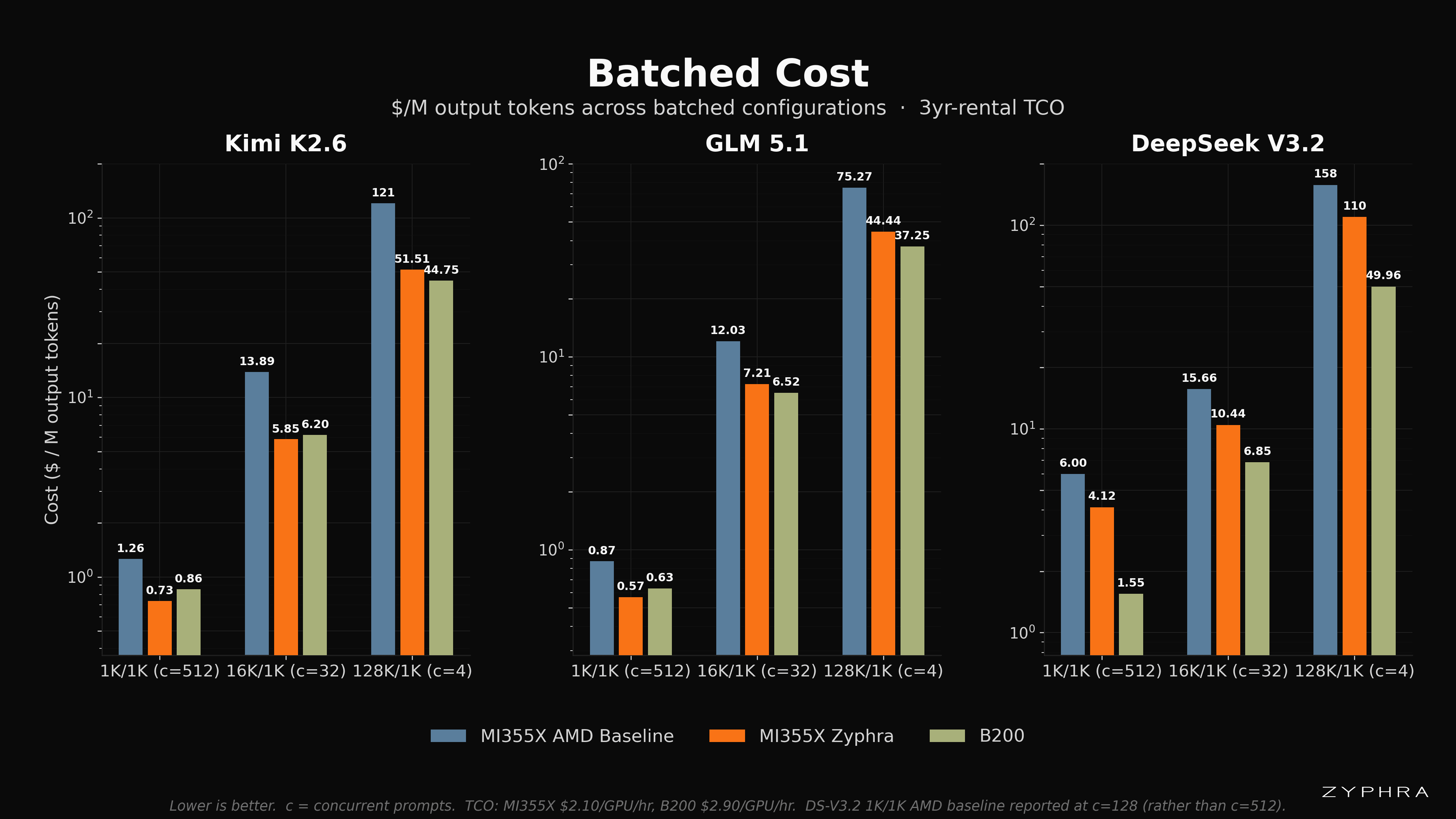
Batched Results
While single-request workloads provide a cleaner measurement of the model’s performance characteristics as opposed to that of the core serving engine, the actual experience of the user is also heavily affected by batched performance. In our initial optimizations we have primarily focused on improving the model forward pass especially in the low-batch regime. In our future work, we will focus on improving the high-batch and high-load performance, which is becoming increasingly representative of our inference cloud workloads as traffic increases. Nonetheless, much of the general-purpose optimization work described above, such as GEMM tuning and speculative decoding, still provides sizable improvements in the interim. See the “Future Work” section below for more information on which optimizations we intend to target next.
Pricing
Ultimately the point of optimization is to translate hardware and software gains into user value. One should not compare inference providers entirely based on absolute cost, since this incentivizes providers to purchase cheaper hardware and serve extremely slow inference at low prices. One should evaluate inference providers based on a combination of cost and performance. Therefore we show inference metrics normalized by GPU price for MI355X and B200.
The first step is hardware. Our goal is to purchase hardware that has the lowest possible inference provider TCO along with the highest possible empirical performance ceiling. From the perspective of an inference provider, the provider TCO of a given accelerator must be viewed in the context of what that hardware can deliver. Zyphra didn’t choose MI355X due to its lower provider TCO alone, but rather due to its combination of low provider TCO and high performance ceiling. We can reach this performance ceiling given dedicated optimization effort as well as the position of its software stack today. Empirical maximum performance (principally GPU throughput and bandwidth, interconnect bandwidth and latency) is highly workload-dependent and vendor maximums are rarely representative of realistic model workloads. GPU throughput at a target datatype for example can be communicated across a spectrum from hardware-focused to software-focused metrics:
Per-core-type MFMA operations
Vendor library GEMMs
DL framework model operations
These metrics are in descending order of what the hardware can deliver in principle but ascending order of how well current low-level compute libraries can achieve this performance in practice. At Zyphra, we consider software-focused metrics like libraries and framework operations as software-bound metrics measures of current position. Then hardware-bound metrics such as the per-core MFMA operations as measures of performance targets. This is why we don’t have performance targets in units of serving metrics alone, as we find these limiting. A better target is what the hardware can deliver and we settle for nothing less.
Future Work
The work we have presented here represents our first round of full-stack inference optimization on Zyphra Inference. We will continue to improve our inference platform focusing on the following:
By providing DeepSeek V4 Pro support, we intend to push our hardware by extending model size and context range to 1.6T parameters and a 1M-token window. Our designs such as TSP and Tree Attention should provide ample speedup within this regime.
Quantization schemes informed by training. We intend to translate our pretraining experience from Zyphra Research in quantization-aware training into novel quantization regimes that exploit the MI355X's matrix cores in MXFP4/MXFP6/MXFP8 while preserving parity with official API providers’ evaluation benchmark scores.
New parallelism schemes and tuning targeting short-context high-concurrency workloads.
Training custom speculators. The greater HBM capacity of our hardware enables the use of larger and more powerful speculators than are standard, which provide higher acceptance rates across a wider range of input domains and contexts. Further, our work in Zyphra Research on diffusion models enables us to train and deploy diffusion speculator models that will provide substantial speedups compared to methods like EAGLE.
Further optimizing kernels, both the improvement of existing kernels within the ROCm ecosystem as well as novel kernels from scratch, will continue to be a focus.
One layer of the software stack that remains largely untouched by us thus far is improvements at the core serving engine layer. Scheduling, KV cache management, prefix caching and hierarchical caches, and novel batching schemes all could provide meaningful improvement and are being explored. Ultimately the order of optimizations will be determined based on highest potential speedup and how rapidly they can be deployed.
Zyphra Inference is available now at cloud.zyphra.com. For the technical details behind Tree Attention and TSP, see the accompanying technical reports here.