
Model
San Francisco, California
Zyphra releases a preview of ZAYA1-74B, an MoE model with 4B active and 74B total parameters, demonstrating large-scale pretraining capabilities end-to-end on AMD. ZAYA1-74B-Preview is a pre-RL reasoning-base checkpoint, released under an Apache 2.0 license. Weights and model card are available here.
Introduction
The recently released ZAYA1-8B shows exceptional performance and intelligence density for its scale due to the strengths of our architecture, pretraining, and post training stacks.
With the release of ZAYA1-74B-Preview, we aim to offer a glimpse of our progress. ZAYA1-74B-Preview is a pre-RL reasoning base checkpoint that has undergone pretraining, midtraining, and context extension. The model has not undergone RL post-training or any kind of instruction or chat tuning.
ZAYA1-74B-Preview is a pre-RL checkpoint not a final reasoning model, making it challenging to properly compare it to other models in a fair way. We choose to compare directly against fully RL post-trained versions of competing models and to provide both avg@1 and pass@4 scores for our model. We view the pass@4 scores as evidence that the scaled ZAYA1-74B-Preview base model is already capable of producing successful reasoning and agentic trajectories with meaningful frequency. This suggests there is sufficient signal available for verifiable and agentic RL to build on in the corresponding domains.
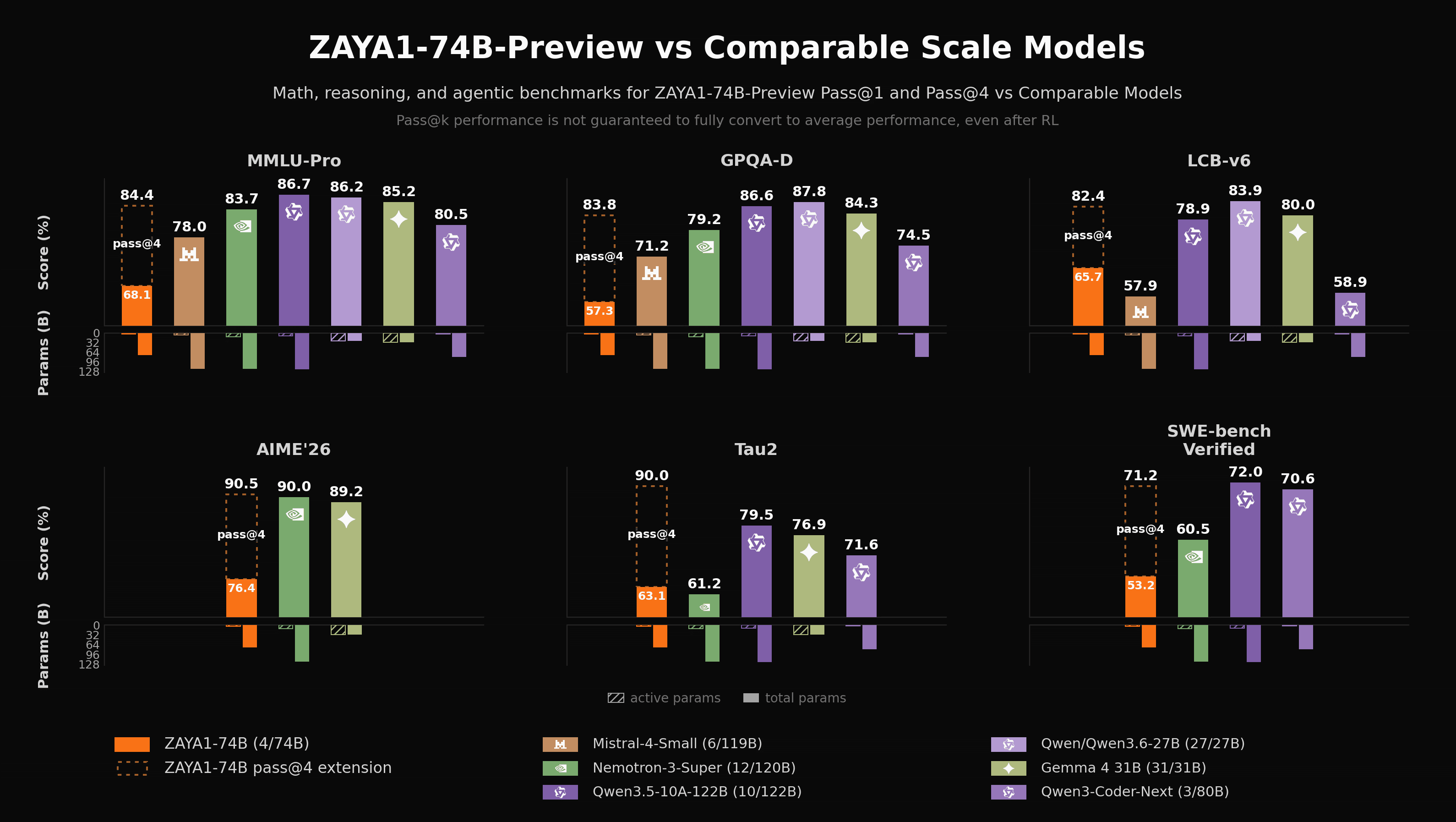
While the reasoning-base model unsurprisingly lags the fully post-trained competitor models, our pass@4 scores are highly competitive and provide significant boosts, demonstrating that the model maintains substantial diversity and a large reservoir of latent capability waiting to be honed by RL. For ZAYA1-8B, we observed a close correlation across midtraining checkpoints between pass@k performance and final post-RL performance, and the realized gains were large: +20.8 AIME'26, +32.4 HMMT'26, +10.0 LiveCodeBench-v6, +11.7 GPQA-Diamond, +19.0 IFEval, +22.4 IFBench, +7.1 BFCL-v4, +3.4 τ². We view this as a signal for potential similar improvements at 74B.
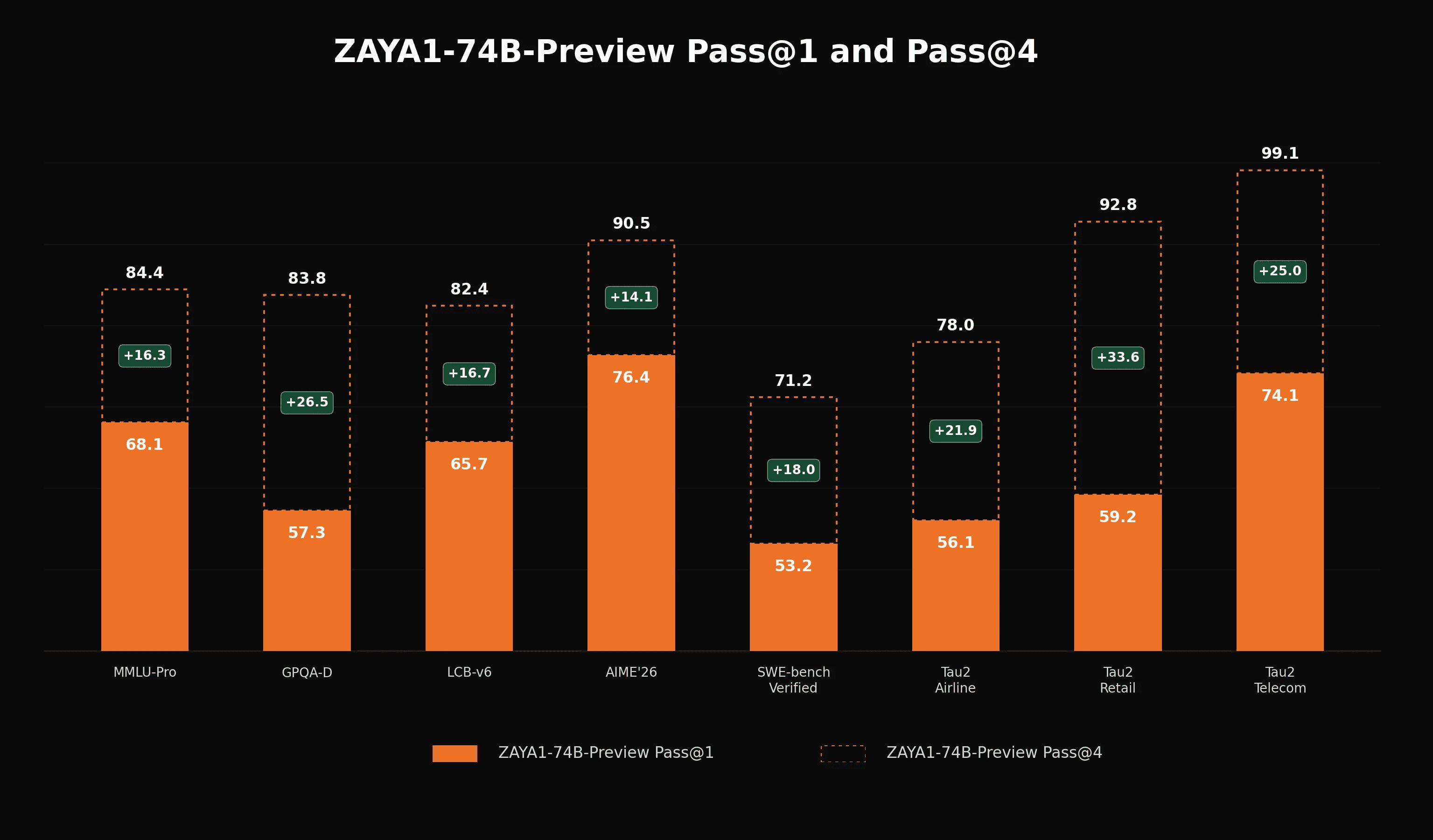
While ZAYA1-8B was weaker at agentic tasks, we have placed substantial focus on agentic capabilities in the pretraining and midtraining corpus for ZAYA1-74B-Preview, and we observe promising indications on evaluations such as τ-bench. For agentic tasks in particular, pass@k is an incomplete measure of the reasoning model's capabilities: multi-turn environments place much greater weight on instruction following, state tracking, and robustness to intermediate failures. We therefore expect dedicated agentic RL to produce additional gains in capability beyond what is presented here. At the same time, we recognize that RL is not guaranteed to translate the derived pass@4 performance on the base reasoning model into corresponding pass@1 gains on the reasoning model on these benchmarks.
Architecture and Pretraining
ZAYA1-74B-Preview follows largely the same architecture as ZAYA1-8B where, to aid with long-context efficiency, we replaced every other attention layer with a sliding window attention (SWA) layer with a window size of 4K. Both global and sliding window attention utilize Zyphra’s CCA attention variant. In our ablations, we observed that SWA reduced the total KV cache usage by nearly half with lossless impact on long context benchmarks. To get this performance improvement we found it important to retain the original pretrained RoPE base of the SWA layers during context extension while extending the RoPE base of our global layers. Maintaining the original RoPE base induces a strong recency bias in our SWA layers which we find improves long context performance overall.
Pretraining and midtraining for ZAYA1-74B-Preview was undertaken in multiple phases. There were two pretraining phases, the first focused on general knowledge using primarily large publicly available web corpora. The second phase focused more on building general mathematical, coding, and scientific capabilities of the model although still primarily using web datasets. Together, pretraining covered approximately 15T tokens.
Midtraining progressed through three phases which progressively extended the context, introduced the model to modern reasoning traces, and focused the model's capabilities on mathematical, coding, and agentic skills. We extended the context first to 32k, then 128k, then 256k. Each midtraining phase covered approximately 1T tokens.
Our pretraining hardware consists of MI300x GPUs each with 192GB of VRAM alongside efficient inter-node communication via Pensando Pollara. Our co-designed training stack’s expert-context-parallel folding and model architecture’s CCA compute efficiency improved our ability to train at long contexts for substantial token counts.
Conclusion
We are excited to release and showcase ZAYA1-74B-Preview as a milestone on our journey to scale on AMD. Full-scale RL on AMD is underway and we expect to release the final ZAYA1-74B model in the coming weeks.
The model weights are available on Hugging Face under an Apache 2.0 license.